지도의 각 칸에는 그 지점의 높이가 주어지며 (0, 0) 지점에서 (n-1, m-1) 지점으로 내려가려고 한다. 항상 높이가 더 낮은 지점으로만 이동하여 목표 지점까지 가고자 할 때 이동할 수 있는 경로의 수를 구하시오.
2.문제예제
3.팩트추출
Fact 1:전형적인 BFS 와 DFS 문제인것처럼보이지만, 입력의범위를보면완전탐색시시간초과가발생할수있다. 최대칸수가 500 * 500 으로 250000 이며상하좌우 4방향으로움직일수있으니 4 의 250000 제곱경우의수가존재한다. 경우의수를줄일수있는방법을찾아야한다.
Fact 2: 문제예제를살펴보면전체문제의답이작은부분문제의답의합으로구성되어있다. 50 번지점에서 목적지까지가는경로의수는 45번지점에서가는경로의수 + 35번지점에서 가는경로의수로이루어져있다. 35번지점이나 30번지점, 27번 지점은경로의수가하나로나중에이지점을방문하더라도계산할필요가없다. 즉 DP 문제이다.
Fact 3 : 기존 DFS 나 BFS 에서사용하던 visited 배열을응용하여 "해당지점에서목적지까지가는경로의수" 로생각하여해당값을재활용하면탐색범위를줄일수있다. 여기서중요한점은 DFS 와 BFS 의 visited 배열활용도가조금다르다는 것이다. BFS 는주변부터탐색하기때문에단순방문했는지여부만파악할수있지만 DFS 는한가지경우의수부터모두탐색하고다시원래위치로돌아오기때문에수행도중 visited 배열을오염시킨다면 그경로는다시탐색하지않아도된다. 4 번 문제 풀이 (수동) 부분에서 자세히 확인한다.
Fact 4: DP[x][y] 배열을 0 으로 초기화하면 이 경로의 수가 0 인지 노드를 방문하지 않은 것인지 확인이 불가능하다. DP 배열이 visited 배열의 역할도 하기 때문에 -1 로 초기화한다.
4.문제풀이(수동)
문제 예제 입력 1을 DFS 알고리즘 + DP 방식으로 문제를 풀었을 때 애니메이션이다.
손수 애니메이션으로 만들어준 우투리와툴툴 티스토리 블로그님께 감사의 말씀을 전한다. 덕분에 이해하기가 쉽다.
5.문제전략
문제 전략은 팩트 추출을 통해 알아보았다. DFS + DP 방식으로 문제를 풀었다.
6.소스코드
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
public class Main {
static int M, N;
static int[][] map;
static int[][] dp;
static int[] dx = { -1, 1, 0, 0 };
static int[] dy = { 0, 0, 1, -1 };
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
M = Integer.parseInt(st.nextToken());
N = Integer.parseInt(st.nextToken());
map = new int[M][N];
dp = new int[M][N];
for(int j = 0; j < M; j++) {
st = new StringTokenizer(br.readLine());
for (int i = 0; i < N; i++) {
map[j][i] = Integer.parseInt(st.nextToken());
}
}
initDP();
System.out.println(dfs(0, 0));
}
private static void initDP() {
for(int j = 0; j < M; j++) {
for (int i = 0; i < N; i++) {
dp[j][i] = -1;
}
}
}
private static int dfs(int x, int y) {
if(x == M-1 && y == N-1){ return 1; }
if(dp[x][y] != -1) return dp[x][y];
dp[x][y] = 0;
for (int i=0; i<4; i++) {
int newX = x + dx[i];
int newY = y + dy[i];
if (newX < 0 || newX >= M || newY < 0 || newY >= N) continue;
if (map[x][y] <= map[newX][newY]) continue;
dp[x][y] += dfs(newX, newY);
}
return dp[x][y];
}
}
Fact 3: lgN 트리 길이만큼 매번 연산하지 말고, 업데이트나 조회 시 해당 구간이 필요하면 변수를 하나 두어 해당 변수에 업데이트하고 다음 번에 도착했을 때 한 단계씩 자식에게 값을 늦게 전파하면 연산을 획기적으로 줄일 수 있다. 이러한 방법을 Lazy Propagation 이라고 한다. 자세한 내용은 다음 글을 참고하자.
값이 변하지 않는다면 구간합을 한 번 연산하고, 계속 질의하면서 쿼리에 대한 결과값을 가져오면 되는데 중간에 있는 값이 변하게 된다면 다시 구간합을 구해야 하므로 O(N) 시간만큼 시간 복잡도가 발생하게 된다. 그래서 조회, 수정 시에도 O(lgN) 시간만큼 줄일 수 있는 자료구조가 필요했다.
일반적인 세그먼트 트리는 입력되는 값 범위의 트리 높이만큼 계산하기 때문에 (N개의원소가있을때 구현에따라) 2배에서 4배정도의추가공간이필요하지만원소의변경, 특정범위내의연산을 logN 에수행할수있다는 장점이 있다.
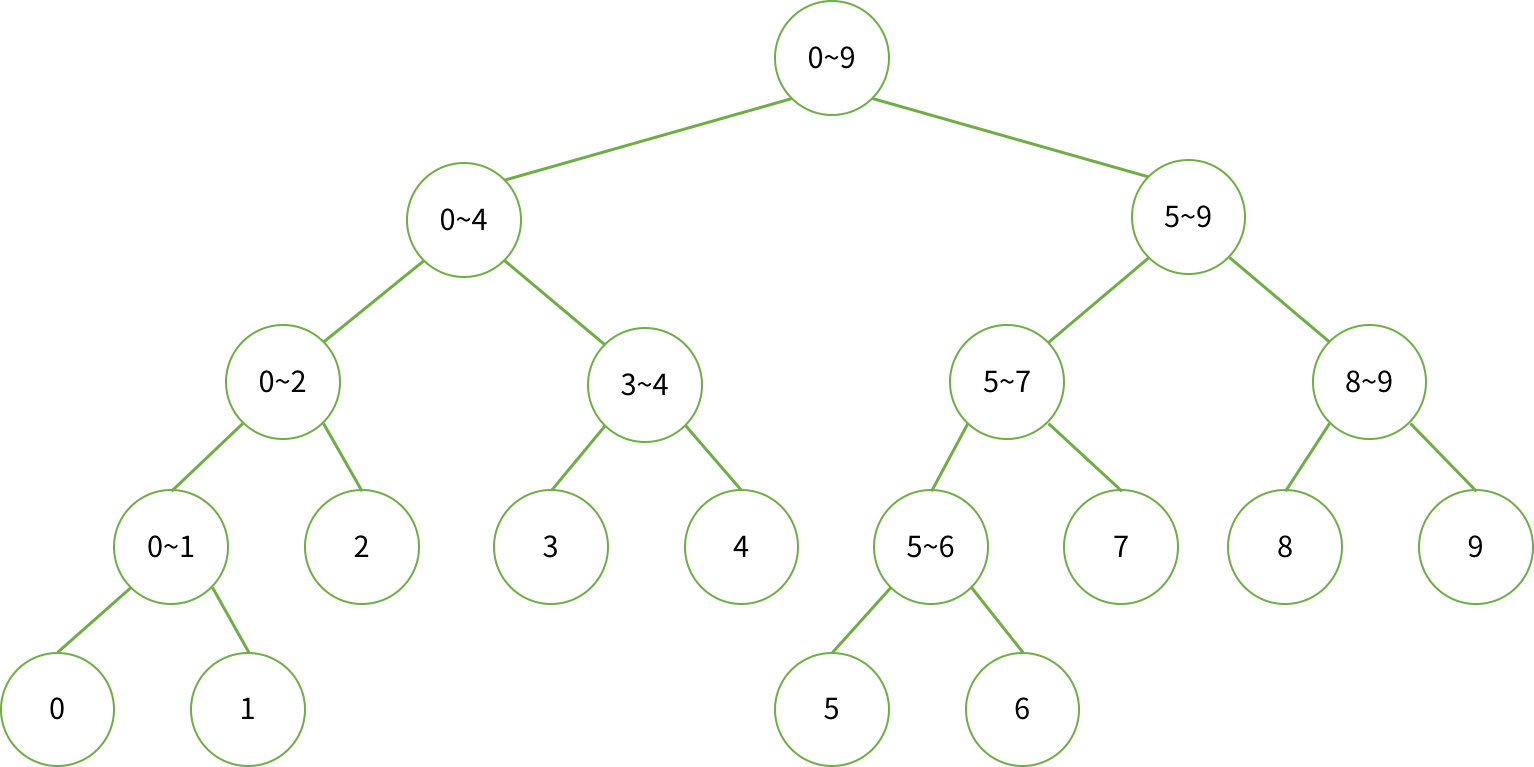
데이터 관점에서 보면 트리는 아래처럼 구성된다.
인덱스 관점에서 보면 트리는 아래처럼 구성된다.
트리의인덱스가 0 이 아닌 1 인 이유는 1 부터시작할 때좌측부터차례로인덱스를부여하면아래공식이성립한다.
이진 탐색 트리 연산이므로 Top-Down 방식으로 이분할하여 데이터를 수정하고 조회하면 된다.
<템플릿>
class SegmentTree {
static long[] tree;
int treeSize;
public SegmentTree(int arrSize){
int h = (int) Math.ceil(Math.log(arrSize)/ Math.log(2));
this.treeSize = (int) Math.pow(2,h+1);
tree = new long[treeSize];
}
// 초기화와 수정을 update 에서 동시에
static void update(int node, int index, int updateValue, int left, int right) {
// 기저사례 (구간에 index 가 없는 경우)
if (index < left || index > right)
return;
// 기저사례 (마지막 구간에 index 가 있는 경우)
if (left == right) {
tree[node] = updateValue;
}
tree[node] += updateValue;
int mid = left + (right - left) / 2;
update(node * 2, index, updateValue, left, mid);
update(node * 2 + 1, index, updateValue, mid+1, right);
}
static void long query(int node, int startIndex, int endIndex, int left, int right){
// 기저사례 (구간에 쿼리구간이 없는 경우)
if (endIndex < left || startIndex > right)
return 0;
// 기저사례 (마지막 구간에 index 가 있는 경우)
if (endIndex >= right && startIndex <= left) {
return tree[node];
}
int mid = left + (right - left) / 2;
return query(node*2, startIndex, endIndex, left, mid) + query(node*2 + 1, startIndex, endIndex, mid+1, right);
}
}
반면, Dynamic Segment Tree 는이름에서도알수있듯이노드가필요할때만생성해서만들기때문에공간을낭비하지않는다. 값을 없데이트할 때 mid 노드의 자식 노드가 없는 경우 노드를 동적으로 생성해준다는 점이 다르다. 구간에 대한 쿼리 로직은 자식이 없는 경우만 예외처리해주면 일반적인 세그먼트 트리와 동일하다.
<템플릿>
static class SegmentTree {
static class Node {
long value;
Node leftChild, rightChild;
}
static Node getNode() {
Node temp = new Node();
temp.value = 0;
temp.leftChild = null;
temp.rightChild = null;
return temp;
}
static void initTree(Node node, int index, long updateValue, int left, int right) {
// 기저사례 (구간에 index 가 없는 경우)
if (index < left || index > right)
return;
// 기저사례 (마지막 구간에 index 가 있는 경우 (수정할 필요 없는 경우 값 셋팅))
// 초기화 과정이 없기 때문에 필요
if (left == right) {
node.value = updateValue;
return;
}
int mid = left + (right - left) / 2;
long leftSum = 0, rightSum = 0;
if (index <= mid) {
if (node.leftChild == null) {
node.leftChild = getNode();
}
update(node.leftChild, index, updateValue, left, mid);
} else {
if (node.rightChild == null) {
node.rightChild = getNode();
}
update(node.rightChild, index, updateValue, mid+1, right);
}
if (node.leftChild != null)
leftSum = node.leftChild.value;
if (node.rightChild != null)
rightSum = node.rightChild.value;
node.value = leftSum + rightSum;
}
static void updateRange(Node node, long updateValue, int updateStart, int updateEnd, int left, int right) {
// 기저사례 (구간에 쿼리구간이 없는 경우)
if (updateEnd < left || updateStart > right)
return;
int mid = left + (right - left) / 2;
updateRange(node.leftChild, updateValue, updateStart, updateEnd, left, mid);
updateRange(node.rightChild, updateValue, updateStart, updateEnd, mid + 1, right);
node.value = node.leftChild.value + node.rightChild.value;
}
static void int query(Node node, int startIndex, int endIndex, int left, int right){
// 기저사례 (할당되지 않은 경우)
if (node == null)
return 0;
// 기저사례 (구간에 쿼리구간이 없는 경우)
if (endIndex < left || startIndex > right)
return 0;
// 기저사례 (마지막 구간에 index 가 있는 경우)
if (endIndex >= right && startIndex <= left) {
return node.value;
}
int mid = left + (right - left) / 2;
return query(node.leftChild, startIndex, endIndex, left, mid) + query(node.rightChild, startIndex, endIndex, mid+1, right);
}
}
3. Dynamic Segment Tree (+ Lazy Propagation)
( 아무리 구글에 검색해봐도 메모리를 절약할 수 있는 Dynamic Segment Tree 와 연산을 줄이는 Lazy Propagation 을 같이 사용하는 코드가 없었다... 특히 Java 는 더욱 없었다. 그래서 내가 쓰려고 템플릿을 만들었다. )
Dynamic Segment Tree 에서 값을 업데이트할 때 자식노드들도 모두 변경하는데 굳이 지금 당장 자식노드의 조회나 수정이 필요 없는 경우라면 트리를 순회하면서 업데이트할 필요는 없다. lazy 라는 변수를 하나두고, 그 변수에 업데이트할 변수를 저장한 다음 나중에 조회하거나 수정할 때 한 단계씩 자식에게 전파하면 된다. 그래서 이름이 느린 전파이다.
업데이트 하고자 하는 범위를 updateStart, updateEnd 라고 할 때, 자식노드를 순회하면서 left, right 탐색 범위가 업데이트 하고자 하는 범위에 완전히 포함된다면 자식노드를 방문하지않고 lazy 값만 자식노드에게 전파한뒤 종료한다. 자식노드들을방문하지않는다.
<템플릿>
static class SegmentTree {
static class Node {
long value;
long lazy;
Node leftChild, rightChild;
}
static Node getNode() {
Node temp = new Node();
temp.value = 0;
temp.lazy = 0;
temp.leftChild = null;
temp.rightChild = null;
return temp;
}
static void updateLazy(Node node, int left, int right) {
// 만약 현재 노드에 lazy 값이 있다면
if (node.lazy != 0) {
// 만약 자식이 있다면 자식들에게 lazy 값을 전파한다.
if (node.leftChild != null) {
node.leftChild.lazy += node.lazy;
}
if (node.rightChild != null) {
node.rightChild.lazy += node.lazy;
}
// 현재노드 업데이트 ( 부모노드이므로 구간 길이만큼 업데이트 )
node.value += node.lazy * (right - left + 1);
// lazy 값을 업데이트했으므로 0으로 만들어준다.
node.lazy = 0;
}
}
// 초기화
static void initTree(Node node, int index, long updateValue, int left, int right) {
// 기저사례 (구간에 index 가 없는 경우)
if (index < left || index > right)
return;
// 기저사례 (마지막 구간에 index 가 있는 경우 (수정할 필요 없는 경우))
// 초기화 과정이 없기 때문에 필요
if (left == right) {
node.value = updateValue;
return;
}
int mid = left + (right - left) / 2;
long leftSum = 0, rightSum = 0;
if (index <= mid) {
if (node.leftChild == null) {
node.leftChild = getNode();
}
initTree(node.leftChild, index, updateValue, left, mid);
} else {
if (node.rightChild == null) {
node.rightChild = getNode();
}
initTree(node.rightChild, index, updateValue, mid + 1, right);
}
if (node.leftChild != null)
leftSum = node.leftChild.value;
if (node.rightChild != null)
rightSum = node.rightChild.value;
node.value = leftSum + rightSum;
}
static void updateRange(Node node, long updateValue, int updateStart, int updateEnd, int left, int right) {
updateLazy(node, left, right);
// 기저사례 (구간에 쿼리구간이 없는 경우)
if (updateEnd < left || updateStart > right)
return;
// 기저사례 (업데이트 구간이 완전히 포함되는 경우)
if (updateEnd >= right && updateStart <= left) {
node.value += (updateValue * (right - left + 1));
if (node.leftChild != null) {
node.leftChild.lazy += updateValue;
}
if (node.rightChild != null) {
node.rightChild.lazy += updateValue;
}
return;
}
int mid = left + (right - left) / 2;
updateRange(node.leftChild, updateValue, updateStart, updateEnd, left, mid);
updateRange(node.rightChild, updateValue, updateStart, updateEnd, mid + 1, right);
node.value = node.leftChild.value + node.rightChild.value;
}
static long query(Node node, int queryStart, int queryEnd, int left, int right) {
updateLazy(node, left, right);
// 기저사례 (할당되지 않은 경우)
if (node == null)
return 0;
// 기저사례 (구간에 쿼리구간이 없는 경우)
if (queryEnd < left || queryStart > right)
return 0;
// 기저사례 (쿼리 구간이 완전히 포함되는 경우)
if (queryEnd >= right && queryStart <= left) {
return node.value;
}
int mid = left + (right - left) / 2;
return query(node.leftChild, queryStart, queryEnd, left, mid) + query(node.rightChild, queryStart, queryEnd, mid + 1, right);
}
}
Q . updateRange 와 Query 함수에서 updateLazy 를 가장 먼저 호출해야 되는 이유?
A . 해당 템플릿이 완성되기 전, 구간에 쿼리 구간이 없는 경우 updateLazy 를 할 필요가 없지 않나? 라고 생각했었다. 그래서 "기저사례 (구간에 쿼리구간이 없는 경우)" 로직 뒷 부분에 updateLazy 를 배치하고 최적화를 잘 했다며 만족했었다.
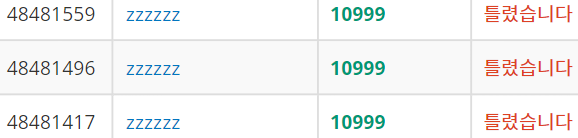
그런데, Lazy Propagation 의 대표문제인 백준 10999 문제를 풀어보니 모두 틀렸다고 나오는 것이었다. 게시판에서 언급하고 있는 반례 케이스들은 모두 맞았는데 안 되니까 답답할 노릇이었다. 잘 생각해보면 잘못된 생각이었다.
만약 부모 노드에 lazy 값이 있는데 자식 노드가 범위를 벗어난다면 lazy 를 전파받지 못하고 계산이 되기 때문이다. 꼭 query 와 update 할 때 updateLazy 를 먼저 호출하자.
public class Main {
static final int SIZE = 65536;
static int[] arr, tree;
public static void main(String[] args) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int n = Integer.parseInt(st.nextToken());
int k = Integer.parseInt(st.nextToken());
arr = new int[n+1];
for(int i=1; i<=n; i++) {
arr[i] = Integer.parseInt(br.readLine());
}
tree = new int[SIZE*4];
// 1 번부터 k 직전까지 노드 삽입
for(int i=1; i<k; i++) {
update(0,SIZE,1,arr[i],1);
}
int prev = 1;
int mid = (k+1)/2;
long ans = 0;
// k 부터 n 까지 노드 삽입하면서 중앙값을 계산하고, 슬라이딩 윈도우 기법으로 K 배열을 움직인다.
for(int i=k; i<=n; i++) {
update(0,SIZE,1,arr[i],1);
ans += find(0,SIZE,1,mid);
update(0,SIZE,1,arr[prev++],-1);
}
System.out.println(ans);
}
static int update(int start, int end, int node, int index, int diff) {
// 기저사례 1 : 타겟 인덱스가 범위 밖인 경우, skip
if(index < start || end < index) {
return tree[node];
}
// 기저사례 2 : 타겟 인덱스 안에 있으면서 start == end 값이 같다면 index 지점에 도착했다는 뜻
if(start == end) {
return tree[node] += diff;
}
int mid = (start + end) / 2;
// 좌측 의 카운트와 우측의 카운트를 합친 값이 부모 카운트
return tree[node] = update(start, mid, node*2, index, diff)+update(mid+1, end, node*2+1, index, diff);
}
static int find(int start, int end, int node, int k) {
if(start == end) {
return start;
}
int mid = (start+end) / 2;
if(tree[node*2] >= k) {
return find(start, mid, node*2, k);
} else {
return find(mid+1, end, node*2+1, k-tree[2*node]);
}
}
}
N개의 스위치와 N개의 전구가 있다. i (1 < i < N) 번 스위치를 누르면 i - 1, i, i + 1 의 세 개의 전구의 상태가 동시에 바뀐다.
(자기 자신을 포함해서 양 옆에 있는 전구가 동시에 바뀐다.) N개의 전구들 현재 상태와 만들고자 하는 상태가 주어졌을 때, 그 상태를 만들기 위해 스위치를 최소 몇 번 누르면 되는지 알아내는 프로그램을 작성하시오.
2.문제예제
3.팩트추출
Fact 1:자기 자신의 스위치를 바꿀 수 있는 것은 양 옆에 있는 전구이다.
그런데 만약 0 ~ N - 1 까지 순차적으로 실행하게 된다면, 왼쪽에 있는 전구는 오른쪽 전구에 의해 바뀔 수 있으므로 사고 과정에서 생략할 수 있다. 오른쪽 전구로만 컨트롤하게 바꾼다면 이전 정보가 필요 없어지게 된다. 또 부분문제이기 때문에 그리디 알고리즘으로 풀 수 있다.
Fact 2:i - 1 번째 전구만 보면서 타겟 전구와 같다면 넘기고, 다르다면 스위치를 누른다. 그런데 가장 첫 번째 전구는 눌러야 할지, 말아야 할지 결정할 수가 없기 때문에 두 가지 경우의 수 모두 구한다.
Fact 3:i 가 마지막 N 위치까지 왔는데 타겟 전구의 상태와 다르다면, 도달할 수 없다는 뜻이고 같다면 최소의 경우의 수 이므로 count 를 반환한다.이 전략이 항상 최선의 상태를 반환하는지는(최소 값을 보장하는지는) 아래 문제풀이(수동)을 통해 알아본다.
4.문제풀이(수동)
그리디 알고리즘은 해당 전략이 항상 최선의 상태를 반환해주는지 검증해야 한다. 문제를 전구 배열 3 크기로 나누어서 생각해본다.
현재 전구 상태 : 010
목표 전구 상태 : 111
목표 전구 상태와 다른 부분을 보고 바로 킨다면 010 -> 100 -> 011 루틴으로 가장 첫 번째 전구를 못 키게 된다.
그 다음 인덱스에서 킨다면 101 -> 110 -> 111 로 안정적으로 킬 수 있게 된다.
현재 전구 상태 : 000
목표 전구 상태 : 111
중간에 있는 전구 하나만 키면 되는 것처럼 보이지만 그 다음 인덱스에서 키기 때문에 이 중간 문제도 해당 공식이 성립한다. 이처럼 3 전구 상태 배열의 모든 경우의 수를 나열하고 테스트 해보았을 때, 오른쪽에 있는 전구를 킬 때가 가장 올바른 선택이라는 것을 알 수 있다.
위와 같이 히스토그램 예제가 있을 때, 0번부터 7번까지 순차적으로 문제푸는 방식과 문제를 분할하여 푸는 방식 2가지가 존재한다. 세그먼트 트리를 이용하는 방법도 있다고는 하는데 여기서는 생략한다.
1) 스택활용
먼저 순차적으로 문제푸는 방식으로 예제를 풀어보면, 다음과 같다.
H[0] * 1 = 3 ===> MaxArea 3 으로갱신
H[4] * (5-4) = 5 * 1 = 5 ===> MaxArea 5 로갱신
H[3] * (5-3) = 4 * 2 = 8 ===> MaxArea 8 로갱신
H[2] * (5-2) = 3 * 3 = 9 ===> MaxArea 9 로갱신
H[1] * 5 = 2 * 5 = 10 ===> MaxArea 10 으로 갱신
H[7] * (7-6) = 3 * 1 = 3
H[6] * (7-5) = 3 * 2 = 6
H[5] * 8 = 1 * 8 = 8
따라서 정답은 10 이다.
2) 분할정복
다음은 문제를 분할정복해서 나누어 풀 때 방식이다. 다음과 같다.
일단 문제를 mid 중심으로 나누어 쪼갠다. 좌측과 우측에서 가장 세로 길이가 큰 직사각형을 구하고, 중간 부분부터 가로의 길이를 확장해 나가면서 가로의 길이가 큰 직사각형을 구한다. 세로 길이가 큰 직사각형의 넓이를 구하는 함수를 getArea 라고 하고 중간 영역부터 확장해서 직사각형의 넓이를 구하는 함수를 getMidArea 라고 할 때 수동 풀이는 다음과 같다.
getArea(0, 7)
getArea(0, 3)
getArea(0, 1)
getMidAread(0, 1, 0)
maxArea : 4
getArea(2, 3)
getMidAread(2, 3, 2)
maxArea : 6
getMidArea(0, 3, 1)
maxArea : 8
getArea(4, 7)
getArea(4, 5)
getMidAread(4, 5, 4)
maxArea : 5
getArea(6, 7)
getMidAread(6, 7, 6)
maxArea : 6
getMidArea(4, 7, 5)
maxArea : 6
getMidArea(0, 7, 3)
maxArea : 10
이 풀이방식의 정답도 10 이다.
문제를 절반으로 나누어서 재귀 호출하고, 각각 O(N) 시간만큼 소요되니 O(NlgN) 시간 복잡도를 가진다. getMidArea 부분을 살펴보면 N 크기의 배열을 나누어서 문제를 푸는데 getMidArea(0,7,3) 처럼 최악의 케이스가 N 복잡도를 가지기 때문이다.
4. 팩트추출
Fact 1:스택 활용편의 예제를 살펴보면, "직사각형의 가로 넓이를 확장해 나가는 방향은 자신의 높이보다 작으면서 양 옆에 있는 높이 중 큰 높이를 골라야 한다." 는 점을 알 수 있다. 이 논리와 더불어 순차적으로 문제를 풀기 때문에 (0 => N) 자신의 크기보다 작은 높이가 나왔을 때 비로소 자신과 그 이전 크기들을 한 꺼번에 계산한다. 계산하는 방식을 보면 데이터를 쌓아두었다가 마지막부터 계산하므로 스택 구조를 사용해야 하는 것을 알 수 있다.
Fact 2 : 문제를 좌측에서 가장 큰 사각형과 우측에서 가장 큰 사각형, 중간에서 가장 큰 사각형을 구하는 문제로 분할할 수 있다. 분할 문제이긴 하지만 이전에 계산한 답안을 재사용하진 않는다. 따라서 DP 문제로 풀 수는 없고 분할정복으로만 풀 수 있다.
Fact 3:문제를 중심으로 분할해서 재귀로 풀 경우, 좌측에서 가장 큰 사각형을 구하는 부분과 우측에서 가장 큰 사각형을 구하는 부분은 막대의 넓이가 1 일때 세로 길이가 가장 큰 사각형이다. 결국 중간에서 가장 큰 사각형을 구하는 함수 부분이 핵심이다.
5.문제전략
문제 전략은 예제 풀이(수동)과 팩트 추출을 통해 알아보았다. 스택을 활용하는 방식과 분할 정복으로 문제를 풀 수 있다.
6.소스코드
1) 스택활용
private static long getArea(int len) {
Stack<Integer> stack = new Stack<>();
long max=0;
for (int i=0; i<N; i++) {
while (!stack.isEmpty() && histogram[stack.peek()] > histogram[i]) {
int index = stack.pop();
int width = stack.isEmpty() ? i : i-stack.peek()-1;
max = Math.max(max, (long)width*histogram[index]);
}
stack.push(i);
}
while(!stack.isEmpty()) {
int index = stack.pop();
int width = stack.isEmpty() ? N : N-stack.peek()-1;
max = Math.max(max, (long)width*histogram[index]);
}
return max;
}
2) 분할정복
private static int getArea(int left, int right) {
if (left == right) return histogram[left];
int mid = (left + right) / 2;
int max = Math.max(getArea(left, mid), getArea(mid+1, right));
max = Math.max(max, getMidArea(left, right, mid));
return max;
}
private static int getMidArea(int left, int right, int mid) {
int leftPointer = mid;
int rightPointer = mid+1;
int height = Math.min(histogram[leftPointer], histogram[rightPointer]);
int result = height*2;
while (left<leftPointer || rightPointer<right) {
if(rightPointer < right && (leftPointer == left || histogram[leftPointer-1] < histogram[rightPointer+1])) {
++rightPointer;
height = Math.min(height, histogram[rightPointer]);
} else {
--leftPointer;
height = Math.min(height, histogram[leftPointer]);
}
result = Math.max(result, height * (rightPointer - leftPointer +1));
}
return result;
}