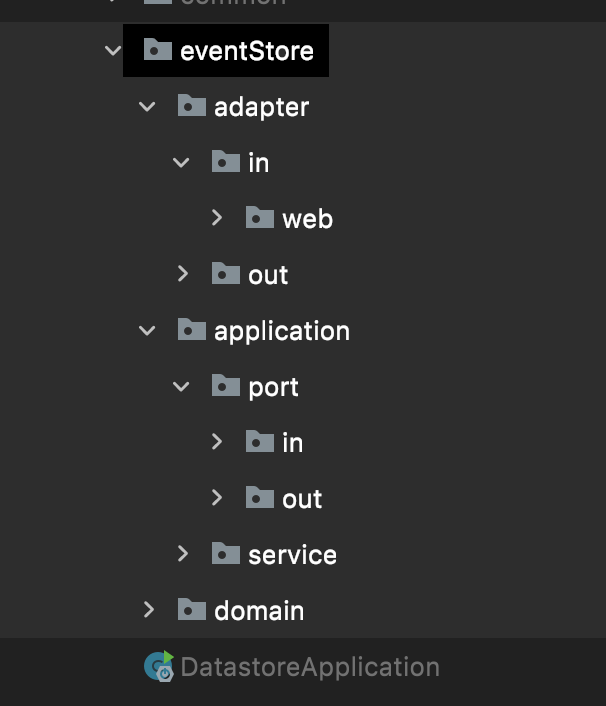
원래그림대로라면 Controller 와 UseCase 사이에 Port 가존재해야되는것이맞지않나라고생각했다. 아니호출해야되는것이맞다. 그런데아래내가공부한출처들에서모두생략하고있다. UseCase 자체가이미인터페이스이기때문에의존성역전이이미되어있는상태이니까생략한것이 아닐까라고추측했다. 결국엔포트를둔다는건서로다른영역을나누기 위한경계즉, 인터페이스로의존성역전을한다는의미일것이니말이다.
그런데, 그림을보면실체화하는위치가다르다. Driving 어댑터쪽은 UseCase 가실체화이고, Driven 어댑터쪽은 Adapter 가실체화이다. 이구조를 Spring 구조와비교해보면 UseCase 가 Input Port 라는것을알수있고 Service 가사실상저그림에서 UseCase 가되는것이다. 혼동이될수있는여지가있지만, Spring 에서는전통적으로저방식으로설계해왔기때문에 Input Port 가사라진것처럼보인것이었다.
BFS 알고리즘은 넓이 우선 탐색 알고리즘이며, DFS 알고리즘은 깊이우선탐색 알고리즘이다.
<템플릿>
public static void bfs(int start) {
Queue<Integer> q = new LinkedList<>();
q.offer(start);
// 현재 노드를 방문 처리
visited[start] = true;
// 큐가 빌 때까지 반복
while(!q.isEmpty()) {
// 큐에서 하나의 원소를 뽑아 출력
int x = q.poll();
// 해당 원소와 연결된, 아직 방문하지 않은 원소들을 큐에 삽입
for(int i = 0; i < graph.get(x).size(); i++) {
int y = graph.get(x).get(i);
// if 제어문의 반복
// if(visited[y]) continue;
q.offer(y);
visited[y] = true;
}
}
}
public static void dfs(int x) {
// 현재 노드를 방문 처리
visited[x] = true;
System.out.print(x + " ");
// 현재 노드와 연결된 다른 노드를 재귀적으로 방문
for (int i = 0; i < graph.get(x).size(); i++) {
int y = graph.get(x).get(i);
if (!visited[y]) dfs(y);
}
}
import java.util.*;
class Solution {
public int[] solution(String[] gems) {
int[] answer = new int[2];
HashSet<String> gemSet = new HashSet<>();
gemSet.addAll(Arrays.asList(gems));
int typeNum = gemSet.size();
int start = 0;
int end = 0;
int gemsNum = gems.length;
int distance = Integer.MAX_VALUE;
int distanceIndex = Integer.MAX_VALUE;
HashMap<String, Integer> gemMap = new HashMap<>();
gemMap.put(gems[0], 1);
while(start < gemsNum && end < gemsNum) {
//System.out.println("start : " + start + " end : " + end);
//System.out.println("gemMap.size() : " + gemMap.size() + " gemSet.size() : " + gemSet.size());
/* 포인터들의 이동으로 정답 조건이 되었을 경우 */
if(gemMap.size() == gemSet.size()) {
/* 답 갱신 */
/* 가장 짧은 구간이면서 시작 진열대 번호가 가장 작은 구간이 정답 */
/* 어차피 작은 인덱스에서 순차적으로 실행되기 때문에 같은 구간이라면 인덱스 검사 안 해도 됨 */
if (distance > end-start) {
distance = end-start;
answer[0] = start+1;
answer[1] = end+1;
}
/* start 포인터 지점과 관련한 변수 계산 부분 초기화 */
gemMap.put(gems[start], gemMap.getOrDefault(gems[start],0) - 1);
/* 값을 빼서 언더플로우가 되었을 때를 대비한 예외 처리 */
if(gemMap.get(gems[start]) <= 0)
gemMap.remove(gems[start]);
/* start 포인터 증가 */
start++;
} else {
/* 포인터들의 이동으로 정답 조건이 되지 않았을 경우 */
/* end 포인터 증가 */
end++;
if (end == gemsNum)
break;
/* end 포인터 지점과 관련한 변수 계산 부분 업데이트 */
gemMap.put(gems[end], gemMap.getOrDefault(gems[end], 0) + 1);
}
//System.out.println("after gemMap size : " + gemMap.size());
}
return answer;
}
}
Two Pointer 알고리즘이란, 두 개의 포인터를 조정하면서 정답 조건들을 찾아가는 알고리즘이다.
<템플릿>
def two_pointer (array) {
start, end = 각 포인터 시작 지점;
/* 순회 배열에 첫 번째 값 넣기 */
반복문 ( start < start 방향 한계 and end < end 방향 한계 ) {
If ( /* 포인터들의 이동으로 정답조건이 되었을 경우 */ ) {
/* 답 갱신 */
/* start 포인터 지점과 관련한 변수 계산 부분 초기화 */
/* start 포인터 증가 */
} else { /* 포인터들의 이동으로 정답조건이 되지 않았을 경우 */
/* end 포인터 증가와 end 포인터 증가로 인해 index 예외처리 */
/* end 포인터 지점과 관련한 변수 계산 부분 업데이트 */
}
}
}
이 템플릿에서 주의할 점은 start 와 end 포인터가 보통 0 부터 시작하기 때문에 항상 else 구문부터 시작한다.
end 가 마지막 포인터에 다 다르면 정답조건이 되었는지 비교해야 하는데 그 때에도 순회 배열에 값을 넣고 있다. 그래서 먼저 순회배열에 첫 번째 아이템을 넣고 else 구문에는 end 포인터를 미리 증가하여 2번째 아이템을 넣기 시작해야 end 포인터가 마지막 차례일 때 정답조건이 되었는지 비교할 수 있다.
이 템플릿 말고 인덱스를 신경쓰기 싫어 무한 반복문 안에서 break 구문을 써 빠져 나오는 템플릿도 있다.
가변인자는 매개변수의 개수가 정해지지 않은 함수의 인자를 말한다. 메서드에 넘기는 인자의 개수를 클라이언트가 조절할 수 있어, 인자의 개수만큼 메서드를 여러 번 오버라이딩하지 않고 원하는 개수만큼 인자를 넘길 수 있게 되었다.
가변인자를 정의할 때는 고정 매개변수가 하나 이상 있어야 하고, 고정 매개변수 뒤에 ... 을 붙여 개수가 정해져 있지 않다는 표시를 해주면 된다.
public static void example(String... args) {
//....
}
가변인수 메서드를 호출하면 내부적으로 가변인수를 담기 위한 배열이 자동으로 하나 만들어진다. 하지만 내부로 감춰야되는 이 배열이 클라이언트에 노출된다는 문제점이 있다. 이 문제점 때문에 varargs 매개변수에 제네릭이나 매개변수화 타입이 포함되면 컴파일 경고가 발생하게 된다. 결론부터 말하자면, 배열과 제네릭을 같이 쓰기 때문이다.
이전 아이템에서 보았듯이, 제네릭과 같은 실체화 불가 타입은 런타임에 타입 관련 정보가 소거가 된다. 타입에 대한 정보가 없기 때문에 실체화 불가 타입으로 varargs 매개 변수를 선언하면 컴파일러가 아래와 같이 경고를 보내게 된다.
warning: [unchecked] Possible heap pollution from
parameterized varargs type List<String>
매개변수화 타입의 변수가 타입이 다른 객체를 참조할 가능성이 있게 되고 이는 힙 오염을 발생시키는 원인이 된다.
이전 아이템 28 "배열보다는 리스트를 사용하라" 편에서 나온 예제와 유사하다. 인자형태가 List<String> 타입을 배열의 아이템으로 가지고 있기 때문에 배열의 공변성과 제네릭의 불공변성이 충돌해 ClassCastException 예외가 발생하게 된다.
마지막 부분에서 컴파일러가 생성한 (보이지 않는) 형변환이 숨어 있기 때문이다. 타입 안전성이 깨지니제네릭 varargs 배열 매개변수에 값을 저장하는 것은 안전하지 않다.
자바 7 이전에는 제네릭 가변인수 메서드의 작성자가 호출자 쪽에서 발생하는 경고에 대해서 해줄 수 있는 일이 없었다. 따라서 사용자는 이 경고들을 그냥 두거나 (더 흔하게는) 호출하는 곳마다 @SuppressWarnings("unchecked") 애너테이션을 달아 경고를 숨겨야 했었다.
하지만 자바 7 이후부터는 @SafeVarargs 애너테이션이 추가되어 제네릭 가변인수 메서드 작성자가 클라이언트 측에서 발생하는 경고를 숨길 수 있게 되었다.
그러나 메서드가 안전한 게 확실하지 않다면 @SafeVarargs 애너테이션을 달아서는 안 된다.varargs 배열에 아무것도 저장하지 않고 (그 매개변수들을 덮어쓰지 않고) 그 배열의 참조가 밖으로 노출되지 않는다면(신뢰할 수 없는 코드가 배열에 접근할 수 없다면) 타입 안전성이 보장될 때만 사용해야 한다. 예를 들어 아래와 같은 코드는 타입 안전하지 않다.
이 메서드가 반환하는 배열의 타입은 이 메서드에 인수를 넘기는 컴파일타임에 결정되는데, 그 시점에는 컴파일러에게 충분한 정보가 주어지지 않아 타입을 잘못 판단할 수 있다. T 배열이 Object 배열이고 String 타입과 Integer 타입이 toArray 인자로 전달된다고 가정해보자. Object 배열에 여러 가지 타입이 혼종되어 오염이 발생할 수 있다. 자신의 varargs 매개변수 배열을 그대로 반환하면 힙 오염 이 발생하게 되고, 메서드를 호출한 쪽의 콜스택으로까지 전이가 될 수 있다.
static <T> T[] pickTwo(T a, T b, T c) {
switch (ThreadLocalRandom.current().nextInt(3)) {
case 0: return toArray(a, b);
case 1: return toArray(a, c);
case 2: return toArray(b, c);
}
throw new AssertionError(); // 도달할 수 없다.
}
이 코드는 위에서 선언한 toArray() 메서드를 호출하고 있는 로직이다. 컴파일러는 toArray() 에 넘길 T 인스턴스 2 개를 담을 varargs 매개변수 배열이 만드는 코드를 생성한다. 여기서 중요한 점은 pickTwo에 어떤 타입의 객체를 넘기더라도 담을 수 있게 하기 위해 Object[] 배열로 반환된다. toArray() 메서드가 돌려준 Object[] 배열이 그대로 pickTwo()를 호출한 클라이언트까지 전달된다. pickTwo()는 항상 Object[] 타입 배열을 반환하게 된다.
위에서 작성했던 코드를 사용하면, ClassCastException 예외가 발생한다. pickTwo()의 반환값인 Object[] 배열을 String[] 타입의 attributes 에 저장하기 위해 String[] 로 형변환하는 코드가 컴파일러가 자동 생성하기 때문이다. 여기서 유의해야할 점은 해당 코드가 힙 오염을 발생시킨 진짜 원인인 toArray() 로부터 두 단계나 떨어져 있다는 점이다.
제네릭 varargs 매개변수 배열에 다른 메서드가 접근하도록 허용하면 안전하지 않다는 점을 확실하게 잘 보여주고 있다.
@SafeVarargs
static <T> List<T> flatten(List<? extends T>... lists) {
List<T> result = new ArrayList<>();
for (List<? extends T> list : lists) {
result.addAll(list);
}
return result;
}
위 코드가 타입 안전한 코드이다. @SafeVarargs 애너테이션을 사용했기 때문에 사용부에서도 문제없이 컴파일된다.
@SafeVarargs 애너테이션은 제네릭이나 매개변수화 타입의 Varargs 매개변수를 받는 모든 메서드에 추가하는 것이 좋다.
또한 @SafeVarargs 애너테이션은 재정의할 수 없는 메서드에만 달아야 한다. 재정의한 메서드도 안전할지는 보장할 수 없기 때문이다.
이 말인 즉슨, 타입 안전하지 않는 Varargs 메서드는 작성하면 안 된다는 것이기 때문에 개발자가 해당 메서드들이 타입 안전하도록 모두 보장해야 한다는 것이다.
첫 번째, Varargs 매개변수 배열에는 아무것도 저장하지 않는다.
두 번째, 그 배열(혹은 복제본)을 신뢰할 수 없는 코드에 노출하지 않는다.
아니면, varargs 매개변수를 List 매개변수로 바꾸는 것도 하나의 방법이다. 이 방식을 앞에서 살펴 보았던 flatten() 메서드에 적용하면 아래와 같이 작성할 수 있다. 단순히 매개변수 선언만 수정한 코드이다.
static <T> List<T> flatten(List<List<? extends T>> lists) {
List<T> result = new ArrayList<>();
for (List<? extends T> list : lists) {
result.addAll(list);
}
return result;
}
정적 팩토리 메서드인 List.of() 을 활용하면 다음 코드와 같이 이 메서드에 임의 개수의 인수를 넘길 수 있다. List.of()에도 @SafeVarargs 애너테이션이 달려 있기 때문에 가능하다.
이 방식은 컴파일러가 이 메서드의 타입 안전성을 검증할 수 있다는 장점이 있다. @SafeVarargs 애너테이션을 직접 달지 않아도 되며, 실수로 안전하다고 판단할 염려도 없게 된다. 하지만 클라이언트 코드가 길어지고, 속도가 조금 느려질 수 있다.
이 방식을 위 pickTwo 메서드에 적용하면 다음과 같다.
static <T> List<T> pickTwo(T a, T b, T c) {
switch (ThreadLocalRandom.current().nextInt(3)) {
case 0: return List.of(a, b);
case 1: return List.of(a, c);
case 2: return List.of(b, c);
}
throw new AssertionError(); // 도달할 수 없다.
}
이번 아이템에서 한정적 타입 매개변수를 사용하므로 위 동영상을 통해 아래 개념을 숙지하고 읽는 것을 추천한다.
"T extends A 는 상한 한정적 타입 매개변수로 타입 매개변수의 클래스가 A 클래스이거나 A 클래스의 하위 클래스를 의미한다. 반대로 T super A 는 하한 한정적 타입 매개변수로 타입 매개변수의 클래스가 A 클래스이거나 A 클래스의 상위 클래스를 의미한다."
매개변수화 타입은 불공변이기 때문에 해당 타입 이외에 다른 타입을 사용할 수 없다. 배열의 공변 특성처럼 상위 클래스나 하위 클래스를 인식할 수 있게 유연한 장치가 필요하다.
public class Stack<E> {
public Stack();
public void push(E e);
public E pop();
public boolean isEmpty();
public void pushAll(Iterable<E> src);
public void popAll(Collection<E> dst);
}
public void pushAll(Iterable<E> src) {
for (E e : src) { push(e); }
}
public void popAll(Collection<E> dst) {
while (!isEmpty()) { dst.add(pop()); }
}
위 스택 클래스를 Number 타입으로 선언하고, pushAll 메서드에 Integer 타입을 넣으면 어떻게 될까?
Integer 가 Number 하위 타입이기 때문에 잘 동작할 것 같지만, 제네릭은 불공변이기 때문에 하위 타입을 인식하지 못해 아래와 같은 에러를 발생시킨다. "error: incompatible types: Iterable<Integer>". 자바는 이러한 불공변에 유연한 설계를 돕기 위해 한정적 와일드카드 타입이라는 특별한 매개변수화 타입을 지원한다.
pushAll 메서드는 E 타입 뿐만 아니라 E 타입의 하위 클래스도 매개 변수로 받을 수 있어야 한다. Iterable<? extends E> 타입을 사용하는 것이 적절하다. Iterable 인터페이스를 통해 E 타입을 "생성" 한다는 특징이 있는 점을 참고하자.
popAll 메서드는 상위 클래스 컬렉션에 저장할 수 있어야 하기 때문에 반대로 E 타입 자신을 포함해서 상위 클래스를 매개 변수로 받을 수 있어야 한다. Collection 인터페이스에서 E 타입을 "소비" 한다는 특징이 있는 점을 참고하자.
이처럼 "생성" 과 "소비" 측면으로 바라보면 헤깔리지 않고 상한 경계와 하한 경계를 사용할 수 있다. 책에서는 PECS (producer-extends / consumer-super) 공식을 외워서 사용하라고 권장하고 있다. 매개변수화 타입 T 가 생산자라면 <? extends T> 를 사용하고, 소비자라면 <? super T> 를 사용하면 된다. 위 Stack 예에서 pushAll 의 src 매개변수는 Stack 이 사용할 E 인스턴스를 생성하므로 Iterable<? extends E> 가 적절하다. 한편 popAll 의 dst 매개변수는 Stack 으로부터 E 인스턴스를 소비하므로 Collection<? super E> 가 적절하다.
단, 입력 매개변수가 생산자와 소비자 역할을 동시에 한다면 와일드카드 타입을 써도 좋을 게 없다. 타입을 정확히 지정해야 하는 상황으로, 이때는 와일트카드 타입을 쓰지 말아야 한다.
조금 더 복잡한 max 메서드를 살펴보자.
public static <E extends Comparable<E>> E max(List<E> list)
위 max() 메서드를 와일드카드 타입으로 적용하면 아래와 같이 고칠 수 있다.
public static <E extends Comparable<? super E>> E max(List<? extends E> list)
이번 예제는 PECS 공식이 두 번 적용되었다.
첫 번째로 입력 매개변수 List<E> 는 E 인스턴스를 생산하므로 원래의 List<E> 를 List<? extends E> 로 수정하는 것이 바람직하다.
두 번째는 타입 매개변수 부분이다. E 가 Comparable<E> 를 확장한다고 정의했는데, 이때 Comparable<E> 는 E 인스턴스를 소비한다. 그냥 이렇게 선언만 되어 있을 경우 E 타입만 비교할 수 있게 된다. 그래서 매개변수화 타입 Comparable<E>를 한정적 와일드카드 타입인 Comparable<? super E> 로 대체하는 것이 바람직하다. Comparable 은 언제나 소비자이므로,일반적으로 Comparable<E> 보다는 Comparable<? super E> 를 사용하는 편이 더 낫다. Comparator도 마찬가지.
타입 매개변수와 와일드카드에는 공통 부분이 많아서, 메서드를 정의할 때 둘 중 어느 것을 사용해도 괜찮을 때가 많다. 예를 들어 주어진 리스트에서 명시한 두 인덱스의 아이템들을 교환(swap) 하는 정적 메서드를 두 방식 모두로 정의할 수 있다.
public static <E> void swap(List<E> list, int i, int j);
public static void swap(List<?> list, int i, int j);
만약 public API라면 간단한 두 번째가 더 낫다. 메서드 선언에 타입 매개변수가 한 번만 나오면 와일드카드로 대체합니다.이때 비한정적 타입매개변수라면 비한정적 와일드카드로 바꾸고, 한정적 타입 매개변수라면 한정적 와일드카드로 바꾸변 된다.
하지만 두 번째 swap 선언에는 문제가 하나 있다. 컴파일이 되지 않는다.
public static void swap(List<?> list, int i, int j) {
list.set(i, list.set(j, list.get(i)));
}
원인은 리스트의 타입이 List<?> 인데, List<?> 에는 null 이외에는 어떤 값도 넣을 수 없기 때문이다. 이를 해결하기 위해서는 와일드카드 타입의 실제 타입을 알려주는 private 도우미 메서드를 따로 작성하여야 한다.
public static void swap(List<?> list, int i, int j) {
swapHelper(list, i, j);
}
// 와일드카드 타입을 실제 타입으로 바꿔주는 private 도우미 메서드
private static <E> void swapHelper(List<E> list, int i, int j) {
list.set(i, list.set(j, list.get(i)));
}
swapHelper 메서드는 리스트가 List<E> 임을 알고 있다. 이 리스트에서 꺼낸 값의 타입이 항상 E 이고, E 타입의 값이라면 이 리스트에 넣어도 안전함을 알고 있다. 이상으로 swap 메서드 내부에서는 더 복잡한 제네릭 메서드를 이용했지만, 덕분에 외부에서는 와일드카드 기반의 깔끔한 메서드를 유지할 수 있다는 장점이 있다. 즉, swap 메서드를 호출하는 클라이언트는 복잡한 swapHelper의 존재를 모른 채 그 혜택을 누릴 수 있게 된다.
이 메서드를 제네릭 메서드로 바꾸면 타입 안전해진다. union 메서드는 입력 2개, 출력 1개의 타입이 모두 같아야 한다. 컴파일 타임 때 이미 String 으로 타입을 확정지었기 때문에 안전하게 실행할 수 있다.
불변객체를 여러 타입으로 활용할 수 있게 만들어야 할 때가 있다. 제네릭은 런타임 때 타입 정보가 소거되므로 하나의 객체를 어떤 타입으로 매개변수화 할 수 있는 장점이 있다. 하지만 이렇게 하려면 요청한 매개 타입 변수에 맞게 매번 그 객체의 타입을 바꿔주는 정적 팩토리 메서드가 필요하다.
IDENTITY_FN 을 UnaryOperator<T> 로 형변환하면 비검사 형변환 경고가 발생한다. 제네릭 불공변 원칙에 따라 UnaryOperator<Object> 는 UnaryOperator<T> 가 아니기 때문이다. 하지만 항등함수란 입력 값을 수정 없이 그대로 반환하는 특별한 함수이므로, T가 어떤 타입이든 UnaryOperator<T> 를 사용해도 타입 안전하다. 이를 근거로 @SuppressWarnings 애너테이션을 추가하여 컴파일 경고를 없애줄 수 있다.
재귀적 타입 한정이라는 개념을 이용하면 자기 자신이 들어간 표현식을 사용하여 타입 매개변수의 허용 범위를 한정할 수 있다. 재귀적 타입 한정은 주로 타입의 순서를 정하는 Comparable 인터페이스와 함께 쓰인다.
public interface Comparable<T> {
int compareTo(T o);
}
Comparable 인터페이스의 타입 매개변수 T는 해당 인터페이스를 구현한 타입이 비교할 수 있는 원소의 타입을 정의한다.
public static <E extends Comparable<E>> E max(Collection<E> c) {
if (c.isEmpty())
throw new IllegalArgumentException("컬렉션이 비어 있습니다.");
E result = null;
for (E e : c)
if (result == null || e.compareTo(result) > 0)
result = Object.requireNonNull(e);
return result;
}
재귀적 타입 한정인 <E extends Comparable<E>> 는 "모든 타입 E 는 자신과 비교할 수 있다" 라는 뜻이다. 위의 코드는 컬렉션에 담긴 원소의 자연적 순서를 기준으로 최댓값을 계산하며, 컴파일 오류나 경고는 발생하지 않는다.
"제네릭 타입과 마찬가지로, 입력 매개변수와 반환값을 명시적으로 형변환해야 하는 메서드보다
이전 아이템에서 살펴보았듯이 타입에 대한 자유도 때문에 사용부에서 형변환을 많이 한다면 제네릭을 고려해야 한다.
Item 7 에서 다루었던 Stack 클래스를 제네릭 타입으로 변경해보면서 변환 시 주의할 점과 꿀팁들을 알아보자.
public class Stack {
private Object[] elements;
private int size = 0;
private static final int DEFAULT_INITIAL_CAPACITY = 16;
public Stack() {
elements = new Object[DEFAULT_INITIAL_CAPACITY];
}
public void push(Object e) {
ensureCapacity();
elements[size++] = e;
}
public Object pop() {
if (size == 0)
throw new EmptyStackException();
Object result = elements[--size];
elements[size] = null;
return result;
}
private void ensureCapacity() {
if (elements.length == size)
elements = Arrays.copyOf(elements, 2 * size);
}
}
이 원본 클래스에서는 클라이언트가 스택으로부터 객체를 꺼낼 때 Object 타입이기 때문에 매번 적절히 형변환을 해주어야 한다. 클라이언트에서 실수로 잘못 형변환할 경우 런타임 오류가 날 위험이 있다. 제네릭 타입으로 구현하는 것이 좋다.
먼저 클래스 선언에 타입 매개 변수를 추가해보자.
public class Stack<E> {
private E[] elements;
private int size = 0;
private static final int DEFAULT_INITIAL_CAPACITY = 16;
public Stack() {
elements = new E[DEFAULT_INITIAL_CAPACITY]; // 컴파일 에러
}
public void push(E e) {
ensureCapacity();
elements[size++] = e;
}
public E pop() {
if (size == 0)
throw new EmptyStackException();
E result = elements[--size];
elements[size] = null;
return result;
}
private void ensureCapacity() {
if (elements.length == size)
elements = Arrays.copyOf(elements, 2 * size);
}
}
위 코드에서 컴파일 에러가 나는 이유는 E 와 같은 실체화 불가 타입으로는 배열을 만들 수 없기 때문이다. 이에 대한 해결책으로 두 가지 방법이 있다.
첫 번째는 제네릭 배열 생성을 금지하는 제약을 우회하는 방법이다. Object 배열을 생성한 다음 제네릭 배열로 형변환한다. 컴파일러는 해당 형변환이 타입 안전한지 알 수 없기 때문에 비검사 형변환 경고를 띄운다. 하지만, elements 배열은 private 필드이고, 클라이언트로 반환되거나 다른 메서드에 전달되는 일이 없고,push() 메서드를 통해 배열에 저장되는 원소의 타입이 E 임을 알고 있다. 따라서 비검사 형변환은 확실하게 안전하므로 @SuppressWarnnings 애너테이션으로 해당 경고를 숨기는 것이 좋다.
public class Stack<E> {
private E[] elements;
private int size = 0;
private static final int DEFAULT_INITIAL_CAPACITY = 16;
// 배열 elements는 push(E)로 넘어온 E 인스턴스만 받는다.
// 따라서 타입 안전성을 보장하지만,
// 이 배열의 런타임 타입은 E[]가 아닌, Object[]다.
@SuppressWarnings("unchecked")
public Stack() {
elements = (E[]) new Object[DEFAULT_INITIAL_CAPACITY];
}
public void push(E e) {
ensureCapacity();
elements[size++] = e;
}
public E pop() {
if (size == 0)
throw new EmptyStackException();
E result = elements[--size];
elements[size] = null;
return result;
}
private void ensureCapacity() {
if (elements.length == size)
elements = Arrays.copyOf(elements, 2 * size);
}
}
두 번째 방법은 elements 필드의 타입을 E[] 에서 Object[] 로 되돌리고, 에러가 나오는 구문에서만 형변환한다. pop() 메서드에서 타입 에러가 발생하는데, 해당 원소를 E 로 형변환 합니다. 형변환하면 아까와 마찬가지로 비검사 형변환에 대한 경고가 나타나는데, push() 에서 E 타입만 허용하므로 타입 안전성을 보장할 수 있으므로 @SuppressWarnning 애너테이션으로 경고를 숨겨줄 수 있다. 배열에 삽입하는 메서드들의 타입이 하나 뿐이어야만 가능하다는 점을 상기해야 한다.
import java.util.Arrays;
import java.util.EmptyStackException;
public class Stack<E> {
private Object[] elements;
private int size = 0;
private static final int DEFAULT_INITIAL_CAPACITY = 16;
public Stack() {
elements = new Object[DEFAULT_INITIAL_CAPACITY];
}
public void push(E e) {
ensureCapacity();
elements[size++] = e;
}
public E pop() {
if (size == 0)
throw new EmptyStackException();
// push에서 E 타입만 허용하므로 이 형변환은 안전하다.
@SuppressWarnings("unchecked")
E result = (E) elements[--size];
elements[size] = null;
return result;
}
private void ensureCapacity() {
if (elements.length == size)
elements = Arrays.copyOf(elements, 2 * size);
}
}
두 가지 방법 모두 잘 사용되고 있다. 첫 번째 방법은 배열의 타입을 오직 E 타입의 인스턴스로만 받을 수 있도록 명시하는 효과를 주며 배열 생성 시 한 번만 타입을 정하면 된다. 반면, 두 번째 방법은 배열에서 원소를 읽을 때마다 형변환을 해주어야 한다. 보통 첫 번째 방법을 더 선호한다. 하지만 배열의 런타임 타입과 컴파일타임 타입이 달라 힙 오염을 일으킬 수 있어서 두 번째 방식을 선택할 수 있다.
이전 아이템인 "배열보다는 리스트를 우선하라" 라는 이야기와 모순처럼 보이지만 결국 제네릭 타입도 내부적으로 배열을 사용하기 때문에 (성능 때문에 or 리스트가 기본 타입이 아니므로) 해당 방법을 알 필요가 있다.