ITEM 1 "생성자 대신 정적 팩토리 메서드를 고려하라"
이 ITEM 을 확인하기 전에 위 백기선님의 Effective Java 1편 해설 영상을 보는 것을 추천한다.
열심히 문어체로 정리하고 작성하지만, 구어체를 따라 올 전달력은 없는 것 같다. 열심히 예를 들어 설명해주셔서 덕분에 이해가 잘 됐다.
이번 장에서는 생성자 대신 정적 팩토리 메서드를 사용하는 것을 권장하고 있다.
public class Point {
double x, y;
// 생성자
public Point(double x, double y) {
this.x = x;
this.y = y;
}
// 정적 팩토리 메서드
public static Point asPolar(double rho, double phi) {
double x = rho * Math.cos(phi);
double y = rho * Math.sin(phi);
return new Point(x, y);
}
// 이렇게 생성할 수 없음. 위 생성자와 타입과 인자의 갯수가 같으므로
public static Point(double rho, double phi) {
this.x = rho * Math.cos(phi);
this.y = rho * Math.sin(phi);
}
}
여기 위와 같이 직교좌표나 극좌표에서 하나의 점을 표시하는 클래스가 있다.
클래스 이름과 같은 함수를 생성자라고 하고, "public static" 키워드가 붙고 클래스 객체를 생성하는 함수를 정적 팩터리 메서드라고 한다. 생김새만 다를 뿐 생성자와 같은 역할을 하는데 정적 팩터리 메서드를 권장하고 있다.
정적 팩터리 메서드는 아래와 같은 장단점을 가지고 있다.
장점 1 이름을 가질 수 있다.
생성자는 클래스 이름과 동일하게 함수 이름을 작성해야 한다는 규칙이 있다. 그래서 매개변수와 생성자의 이름만으로 반환될 객체의 특성을 제대로 설명하지 못 한다는 특징이 있다. 하지만 정적 팩토리 메서드는 위 예제와 같이 극좌표계에서 쓰일 객체를 "asPolar" 라는 이름으로 잘 설명해주고 있다.
또 타입의 순서와 갯수가 같은 동일한 생성자를 만들 수 없다. 자바에서는 오버로딩을 지원하고 있지만 어디까지나 매개변수 타입의 순서와 갯수가 같아야 한다. 위 코드에서 극좌표계 생성자를 만들다가 실패한 코드가 그 예제이다.
장점 2 새로운 객체를 생성할 필요는 없다.
생성자는 이름 그대로 반드시 하나의 객체를 생성해야 한다. 그렇지만 정적 팩토리 메서드는 프로그래머가 임의로 작성한 메서드이기 때문에 제약이 없다. 불변한 객체를 미리 만들어 놓고 그 객체를 재사용하는 식으로 코드를 작성할 수 있다. 객체가 불변함이 보장된다면 굳이 하나의 객체를 생성해야 하는 생성자는 메모리 비용이 많이 드는 나쁜 선택이다.
public class Point {
private static Point pointInstance;
private static final Point SINGLE_POINT_OBJECT = new Point();
public static Point getPoint() {
return SINGLE_POINT_OBJECT;
}
public static Point getPointWithSingleTon() {
if (pointInstance == null) {
pointInstance = new Point();
}
return pointInstance;
}
}
이렇게 객체 생성을 컨트롤 할 수 있어 인스턴스 통제 클래스라고 부르며 언제, 어디까지 인스턴스를 살게 할 수 있을지 결정할 수 있다. 싱글톤 패턴을 만들 때에도 유용하고 불변 클래스를 만들 때에도 사용된다.
장점 3 반환 타입의 하위 타입 객체를 반환할 수 있다.
말 그대로 상속받은 자식 클래스의 객체를 반환할 수 있다는 뜻이다. 자식 클래스의 객체를 반환할 수 있게 해준다면 그 자식 클래스를 공개하지 않고도 객체를 사용할 수 있다는 것이다. 명시한 인터페이스만 다른 시스템에 노출시키고 구현체는 숨김으로써 객체지향의 OCP 원칙을 잘 지키며 설계할 수 있다. 이를 인터페이스 기반 프레임워크라고 부른다.
다른 시스템에 노출 시키려면 모두 public 으로 제한자를 풀어야 되는데 구현체는 private 로 숨기고 API 만 public 으로 만들고 그 인터페이스 정적 팩토리 메서드에서 구현체들을 반환만 해주는 것이다.
자바 8 이전에는 인터페이스에서 정적 메서드를 만들 수가 없었다고 한다. 그래서 인스턴스화가 불가한 동반 클래스로 만들어 그 안에 정의했다고 한다.
장점 4 입력 매개변수에 따라 매번 다른 클래스의 객체를 반환할 수 있다.
장점 3의 연장선 상의 개념이다. 조건에 따라 하위 타입의 객체를 반환할 수 있게 설계가 가능하다.
이 책에서는 EnumSet 클래스를 예로 들며 이 클래스는 public 생성자가 없고 원소의 갯수에 따라 객체를 반환하는 메서드만 있다고 한다. 원소가 64개 이하면 RegularEnumSet 객체를, 65개 이상이라면 JumboEnumSet 객체를 반환한다.
Intellij 에서 직접 확인해봤다.
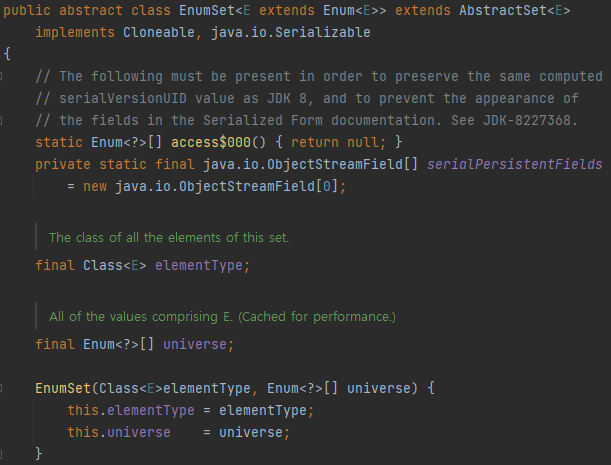
맨 마지막 EnumSet 생성자 보면 접근 제한자가 없다. 같은 패키지 내에서만 호출될 수 있다.
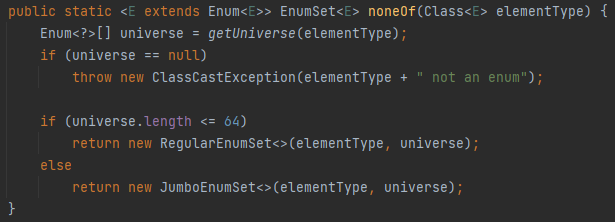
그리고, noneOf 이라는 정적 팩토리 메서드에서 원소의 개수에 따라 하위 클래스의 객체를 반환하는 것을 볼 수 있다.
이 클래스를 사용하는 프로그래머 입장에서는 저런 세세한 구현을 알지 못하더라도 공통적인 기능의 EnumSet 을 사용할 수 있게 된다. 장점 3에서 이야기 하였듯이 실제 구현은 공개하지 않았는데도 명세서만 보고 개발이 가능하다.
장점 5 정적 팩토리 메서드를 작성할 때 반환할 객체의 클래스가 존재하지 않아도 된다.
책에서는 서비스 프로바이더 프레임워크를 예시로 들면서 설명하고 있는데 그 개념을 모르는 사람은 어렵기도 하고 이해가 가지 않을 수 있다. 쉽게 설명하면 "구현"과 "정의" 그리고 "사용" 관점에서 나누어 설계되어 있는 프레임워크라고 보면 된다. 정의부는 이 시스템에서 제공하고자 하는 명세서를 작성하는 담당을 하고, 구현부는 실제 그 기능을 만드는 구현체이다. 사용부는 사용자가 이 시스템에 접근해서 서비스를 요청하는 담당을 한다. 여기서 사용부는 어떻게 구현되었는지 알 필요가 없다. 무엇을 요청할지만 알면 된다. 그래서 사용부의 API 는 정의 인터페이스만 반환할 뿐이다.
정의 인터페이스와 연결만 되어 있으니 반환할 객체의 클래스가 존재하지 않아도 개발이 가능하다.
단점 1 상속이 불가능하다. == 하위 클래스를 만들지 못 한다.
상속을 하려면 public 이나 protected 생성자가 필요한데 정적 팩토리 메서드가 구현된 클래스는 생성자가 불필요하기 때문에 private 으로 보통 선언한다. 따라서 상속이 불가능하며 하위 클래스를 만들지 못한다.
나중에 "상속보다 합성", "불변 클래스" 라는 말을 많이 듣게 될텐데 상속이 불가능하다는 것은 단점이라기 보다는 장점으로 보일 수 있다.
단점 2 프로그래머가 정적 팩터리 메서드를 찾기가 어렵다.
단점이라기 보다는 불친절에 가깝다. 자바독을 보면, 생성자는 설명을 잘 해두지만 정적 팩터리 메서드는 직접 개발자가 소스코드를 뒤지며 찾아야 한다. 안 써있다. 앞으로 개발자들이 생성자와 같은 역할을 하는 정적 팩터리 메서드도 잘 문서화하면 문제가 없을 것이다. 그 이전에 작성해두었던 정적 팩토리 메서드는 어떻게 찾아야 될까?
흔히 사용되는 정적 팩터리 메서드 명명 방식들을 눈에 익혀두고 생각이 안 나면 이 접두사들을 보고 찾자.
| from | 매개변수가 하나일 때 사용 |
| of | 여러 매개변수를 받을 때 사용 |
| valueOf | from 과 of 의 더 자세한 버전 |
| getInstance / instance | 매개변수로 명시한 인스턴스 반환 |
| newInstance / create | getInstance/instance 와 기능은 같지만, 매번 새로운 인스턴스를 생성해서 반환 |
| getType | 여기서 Type 은 다른 클래스 이름. 다른 클래스의 객체를 반환 |
| newType | newInstance 와 같지만, 다른 클래스의 객체를 반환 |
| type | getType 과 newType 의 간결한 버전 |
"정적 팩토리 메서드를 고려하고 항상 문서화하자."
'독후감 > Effective JAVA' 카테고리의 다른 글
| [Effective JAVA] 6 "불필요한 객체 생성을 피하라" (0) | 2022.04.28 |
|---|---|
| [Effective JAVA] 5 "자원을 직접 명시하지 말고 의존 객체 주입을 사용하라" (0) | 2022.04.27 |
| [Effective JAVA] 4 "인스턴스화를 막으려거든 private 생성자를 사용하라" (0) | 2022.04.26 |
| [Effective JAVA] 3 "private 생성자나 열거 타입으로 싱글턴임을 보증하라" (0) | 2022.04.26 |
| [Effective JAVA] 2 "생성자에 매개변수가 많다면 빌더를 고려하라" (0) | 2022.04.21 |