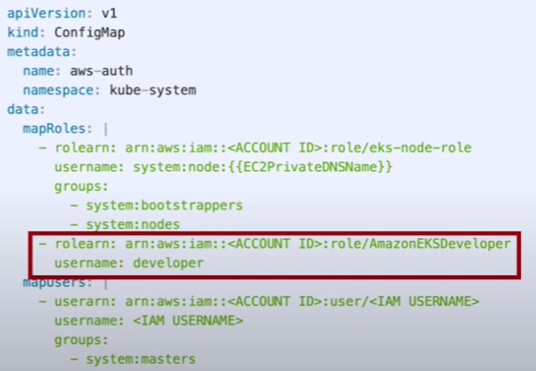
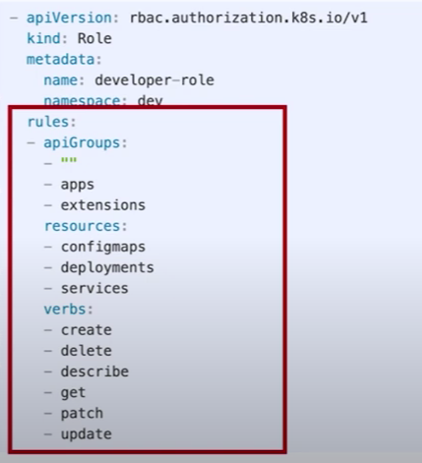
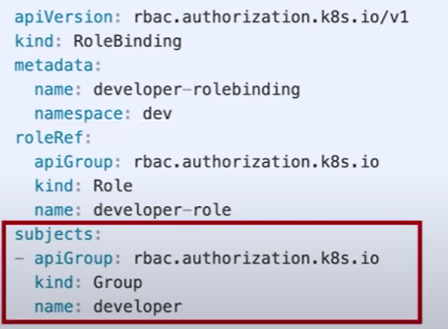
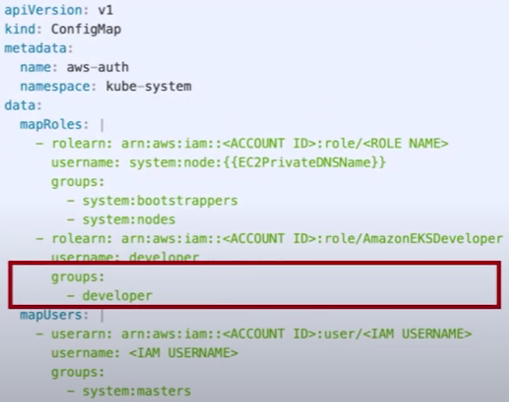
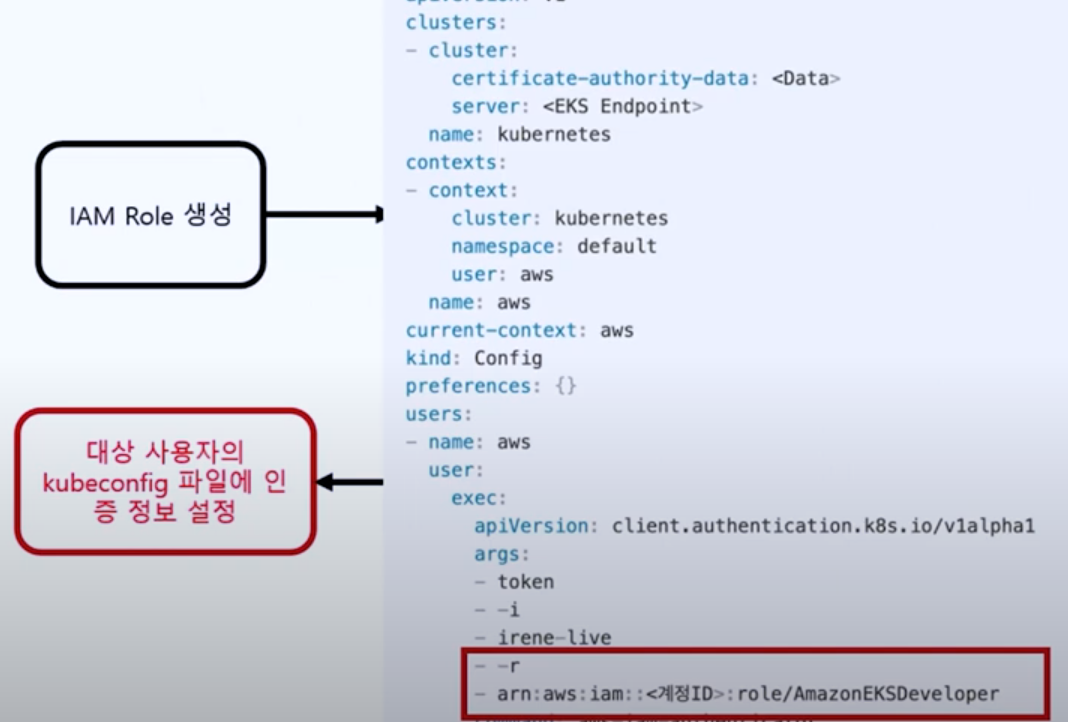
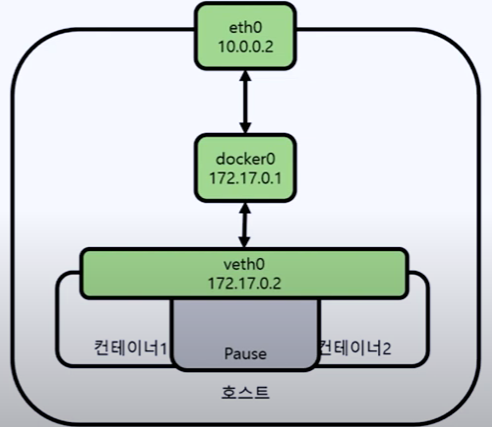
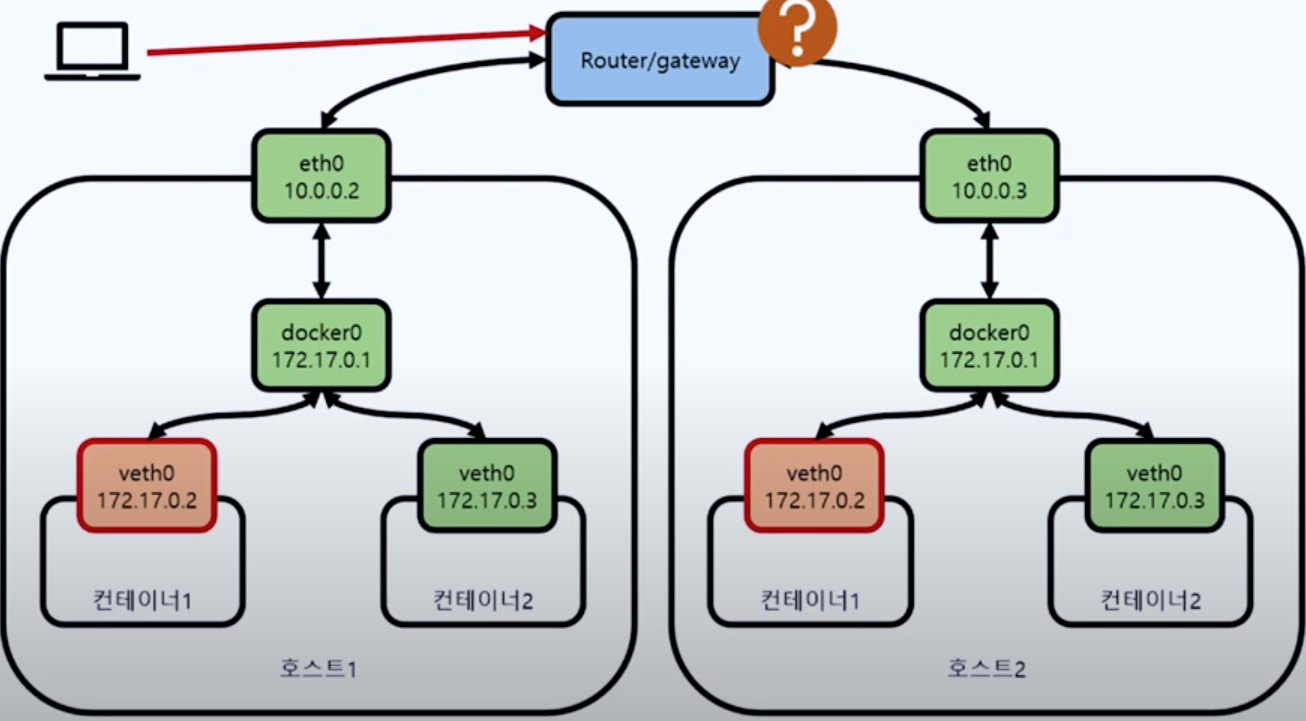
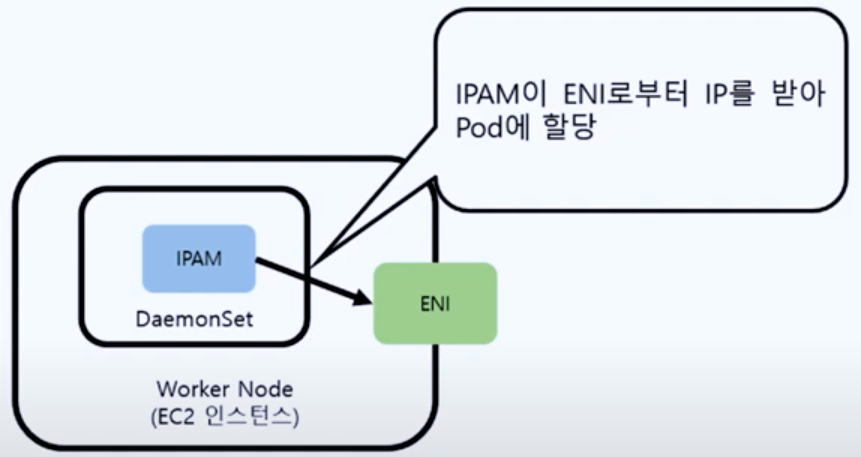
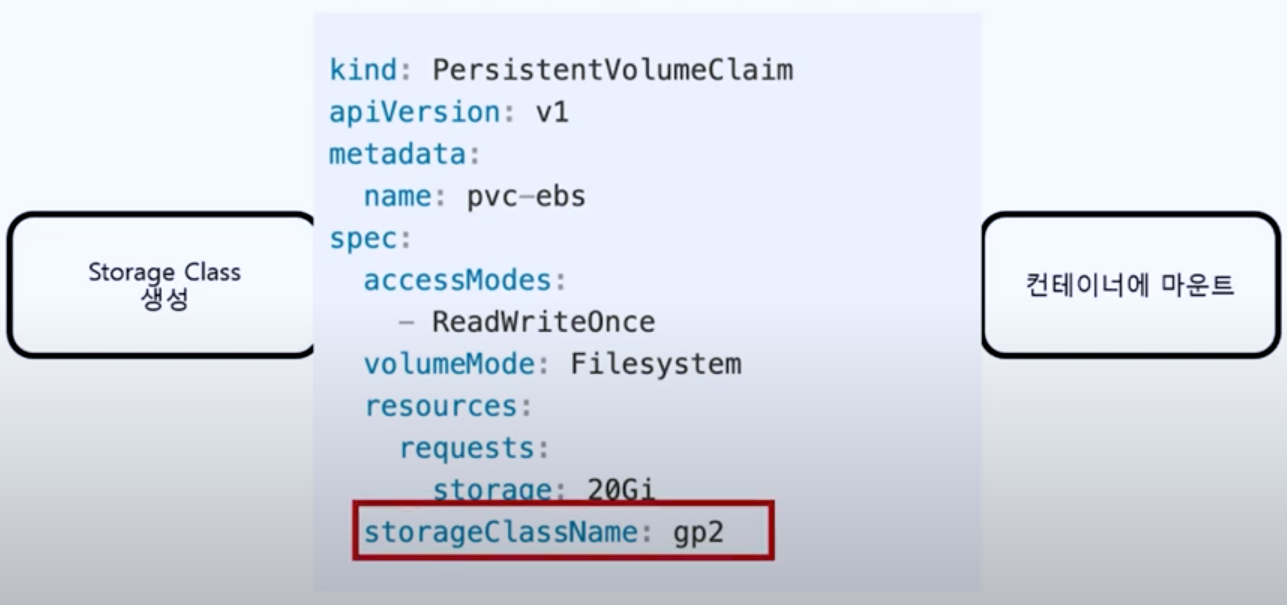
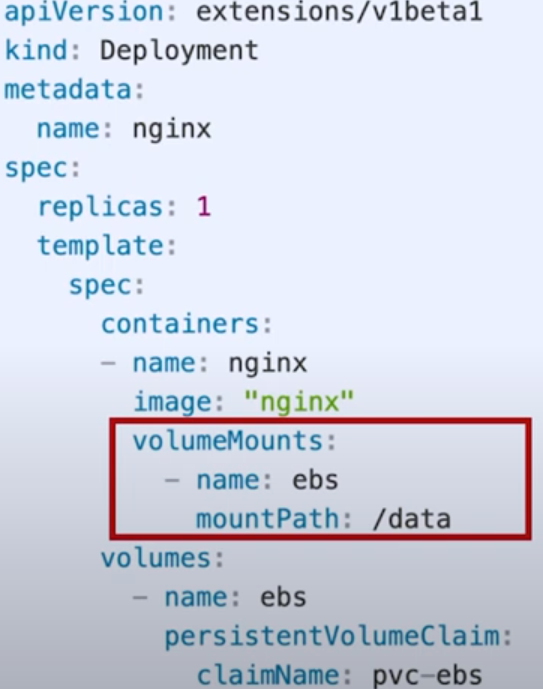
쿠버네티스구조를보면나머지구성정보는 Pod 가재빠르게뜨면 문제가없을수있지만, API 서버와 etcd 는죽으면가용성에문제가생긴다. 그래서 API 서버는 2대, etcd 는 3대가 최소 필요하다. etcd 는 RAFT 라는분산합의알고리즘으로 인해 홀수 개를유지해야 해서 최소 3대가필요하다.
자바8 부터람다를 지원하면서 템플릿 메서드 패턴보다는 전략을 함수 객체 인자 형태로 전달하는 템플릿 콜백 패턴(전략 패턴) 이 모범이 되었다.
템플릿 메서드 패턴
abstract class Car {
// 공통 메서드
public void drive() {
System.out.println("운전 시작");
moving();
System.out.println("운전 완료");
}
// 변화하는 부분
abstract void moving();
}
class Hyundai extends Car {
@override
public void moving() {
...
}
}
상위 클래스의 변하는 부분들을 메서드로 분리해 하위 클래스에 재정의하는 기법을 템플릿 메서드 패턴이라고 한다. 상속을 사용한다.
템플릿 콜백 패턴 (전략 패턴)
// 선언부
class Car {
// 공통 메서드
public void drive(MovingStrategy movingStrategy) {
System.out.println("운전 시작");
movingStrategy.moving();
System.out.println("운전 완료");
}
}
// 사용부
// MovingStrategy 인터페이스에는 moving 이라는 추상 메서드 하나만 존재해야 한다.
Car myCar = new Car();
myCar.drive(() -> System.out.println('100km/h 주행 중'));
이와는 반대로 함수 객체를 사용하는 시점(moving 함수 호출)에 전략 함수 객체를 인자로 받아 실행하는 형태를 템플릿 콜백 패턴. 즉 전략패턴이라고 한다. 함수 생성 시점에 전략 객체를 같이 생성하여 강하게 결합하는 것이 아닌, 사용하는 시점에 전략 객체를 인자로 받아 사용하고 제거하는 형태로 결합해 결합도가 낮아 유연하다는 장점이 있다.
LinkedHashMap 를 커스터마이징해서 더 자세히 알아보자.
LinkedHashMap 의 removeEldestEntry()함수는 맵에 새로운 키를 추가할 때 호출되는put()메서드에 의해 호출되는데, 해당 메서드가true를 반환하면 맵에서 가장 오래된 원소를 제거한다. 이 removeEldestEntry 함수를 오버라이드해서 가장 최신 5 개인 데이터만 유지하는 캐시를 만들어보자.
일단, removeEldestEntry 메서드는 인스턴스 메서드이므로 자기 자신도 함수 객체로 건네주어야 한다. Map<K, V> map
그리고 해당 인터페이스가 함수형 인터페이스임을 알 수 있도록 @FunctionalInterface 어노테이션을 붙여준다.
FunctionalInterface 어노테이션을 붙여주면 아래와 같은 이점이 있다.
해당 클래스의 코드나 문서를 읽을 이에게 인터페이스가 람다용으로 설계된 것임을 알려준다.
해당 인터페이스가 추상 메서드를 오직 하나만 가지고 있어야 컴파일 되게 해준다.
유지보수 과정에서 누군가 실수로 메서드를 추가하지 못하게 막아준다.
하지만 위와 같이 두 개의 인자를 받고 boolean 값을 리턴하는 모양의 인터페이스가 이미 자바 표준 라이브러리에 존재한다. BiPredicate 인터페이스다.
// java.util.function 패키지에 선언되어 있는 BiPredicate 형태
@FunctionalInterface
public interface BiPredicate<T, U> {
boolean test(T t, U u);
}
// 별도로 인터페이스를 만들 필요 없다. BiPredicate 사용
BiPredicate<Map<String, String>, Map.Entry<String, String>> removalFunction
= (map, eldest) -> map.size() > 5;
별도로 인터페이스를 선언할 필요없이 바로 사용하면 된다. "두 개의 인자를 받아 검증한다" 이외에 다른 기능이 존재하지 않는다면 별도로 만들지 않고 표준 라이브러리 기능을 사용하는 것을 권장한다.
아래 코드는 위에서 언급한 3가지 경우의 수를 테스트해볼 수 있는 코드이다.
OverrideLinkedHashMap 이 직접 클래스에 전략을 override 를 한 케이스(템플릿 메서드 패턴)이고, FunctionalLinkedHashMap 과 BiPredicateLinkedHashMap 이 전략을 함수 인자 형태로 전달한 케이스(템플릿 전략 패턴) 이다.
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.function.BiPredicate;
public class MyLinkedHashMap{
@FunctionalInterface
public interface EldestEntryRemovalFunction<K, V> {
boolean remove(Map<K, V> map, Map.Entry<K, V> eldest);
}
public static void main(String[] args) {
// OverrideLinkedHashMap
Map<Integer, Integer> overrideMap = new OverrideLinkedHashMap<>();
for (int i = 0; i < 10; i++){
overrideMap.put(i, i);
}
System.out.println(overrideMap);
// FunctionalLinkedHashMap
Map<Integer, Integer> functionalMap = new FunctionalLinkedHashMap<>((map, eldest) -> map.size() > 5);
for (int i = 0; i < 10; i++){
functionalMap.put(i, i);
}
System.out.println(functionalMap);
// BiPredicateLinkedHashMap
Map<Integer, Integer> functional2Map = new BiPredicateLinkedHashMap<>((map, eldest) -> map.size() > 5);
for (int i = 0; i < 10; i++){
functional2Map.put(i, i);
}
System.out.println(functional2Map);
}
private static class OverrideLinkedHashMap<K, V> extends LinkedHashMap<K, V> {
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > 5;
}
}
private static class FunctionalLinkedHashMap<K, V> extends LinkedHashMap<K, V> {
private final EldestEntryRemovalFunction<K, V> eldestEntryRemovalFunction;
public FunctionalLinkedHashMap(EldestEntryRemovalFunction<K, V> function) {
this.eldestEntryRemovalFunction = function;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return eldestEntryRemovalFunction.remove(this, eldest);
}
}
private static class BiPredicateLinkedHashMap<K, V> extends LinkedHashMap<K, V> {
private final BiPredicate<Map<K, V>, Map.Entry<K, V>> eldestEntryRemovalFunction;
public BiPredicateLinkedHashMap(BiPredicate<Map<K, V>, Map.Entry<K, V>> function) {
this.eldestEntryRemovalFunction = function;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return eldestEntryRemovalFunction.test(this, eldest);
}
}
}
java.util.function 패키지에 43개의 인스턴스가 포함되어 있으며 아래 6개의 인터페이스가 기본적인 인터페이스다. 나머지는 충분히 유추해낼 수 있다.
인터페이스
함수 시그니처
예
UnaryOperator<T>
T apply(T t)
String::toLowerCase
BinaryOperator<T>
T apply(T t1, T t2)
BigInteger::add
Predicate<T>
boolean test(T t)
Collection::isEmpty
Function<T,R>
R apply(T t)
Arrays::asList
Supplier<T>
T get()
Instant::now
Consumer<T>
void accept(T t)
System.out::println
아래의 6개 인터페이스들은 모두 참조 타용이다. 참고로 기본 인터페이스는, 기본 타입인int,long,double용으로 각 3개씩 변형이 생겨난다. 나머지는 코드나 문서를 참고하자.
보통의 경우에는 직접 작성하지 않고 표준 함수형 인터페이스를 사용해야 하지만, 구조적으로 같아도 직접 작성해야 하는 경우가 존재한다. 예를 들어Comparator<T>인터페이스는 구조적으로ToIntBiFunction<T,U>와 동일하다. 하지만Comparator가 독자적인 인터페이스로 남아야 하는 이유는 다음과 같다.
@FunctionalInterface
public interface Comparator<T> {
int compare(T o1, T o2);
}
API에서 자주 사용되며, 이름 자체가 용도를 명확히 설명해준다.
구현하는 쪽에서 반드시 따라야 하는 규약이 있다.
유용한 디폴트 메서드를 여러 개 제공할 필요가 있다. (위 Comparator 예에서는 비교자들을 조합하고 변환하는 메서드를 제공)
마지막으로, 위와 같은 함수형 인터페이스도 주의사항이 있다. 같은 위치의 인수로 받는 메서드들을 다중 정의해서는 안된다. 클라이언트에게 모호함을 안겨줄 뿐만 아니라, 둘 중에 어떤 타입인지 알기 위해 사용하는 쪽에서 타입 형변환을 해야할 수도 있다. "다중정의는 주의해서 사용하라" 라는 아이템 52 조언을 한 번 더 강조한다.
위 코드는 자바 8 때, Map 에 추가된 merge 메서드이다. 키, 값, 함수를 인수로 받으며 주어진 키가 맵에 없다면 주어진 [키, 값] 쌍을 그대로 저장하고, 반대로 키가 있으면 [키, 함수의 결과] 쌍을 저장한다. 깔끔해 보이지만, count 와 incr 가 크게 하는 일 없이 공간만 차지한다. 자바 8이 되면서 Integer 클래스는 이 람다와 같은 기능을 가진 정적 메서드 sum 을 제공했다.
map.merge(key, 1, Integer::sum);
더 간결해진 것을 볼 수 있다. 하지만 메서드 참조는 함수의 이름만 명시하기 때문에 단번에 이해가 되지 않을 수도 있다.
매개변수의 이름 자체가 프로그래머에게 힌트를 준다면 람다가 더 좋은 선택지가 될 수도 있다. (매개변수가 여러 개이고 함수 이름으로 단 번에 파악이 안 된다면)
단 번에 파악할 목적이 아니고 해당 함수의 선언 부분으로 이동하는 수고로움을 감수할 수 있다면, 똑같은 인자 구성으로 함수를 만든 다음, 메서드 참조를 사용하는 것이 더 좋다. 메서드 참조에는 기능을 잘 드러내는 이름을 지어줄 수 있고, 친절한 설명을 문서에도 남길 수 있으니 말이다. 하지만 같은 클래스 안에 있는 기능을 호출하는 것이라면 람다가 더 간결하다.
// 1 번째 방법
service.execute(GoshThisClassNameIsHumongous::action);
// 2 번째 방법
service.execute(() -> action());
메서드 참조에는 아래와 같이 5가지 유형이 있다.
메서드 참조 유형
예
같은 기능을 하는 람다
정적
Integer::parseInt
str -> Integer.parseInt(str)
한정적 (인스턴스)
Instant.now()::isAfter
Instant then = Instant.now(); t -> then.isAfter(t)
비한정적 (인스턴스)
String::toLowerCase
str -> str.toLowerCase()
클래스 생성자
TreeMap<K, V>::new
() -> new TreeMap<K, V>()
배열 생성자
int[]::new
len -> new Int[len]
"메서드 참조 쪽이 짧고 명확하다면 메서드 참조를 사용하고, 그렇지 않을 때만 람다를 사용한다"
Java 8 이전에는 자바에서 함수 타입을 표현할 때 추상 메서드를 하나만 담은 인터페이스를 사용했었다. 이런 인터페이스의 인스턴스를 함수 객체라고 하는데 다른 곳에서 절대 사용하지 않는 가벼운 함수 객체라면 함수 객체를 인자로 받는 공간에 바로 new 연산자를 통해 생성할 수 있었다.
Collections.sort(words, new Comparator<String>() {
public int compare(String s1, String s2) {
return Integer.compare(s1.length(), s2.length());
}
});
이렇게 인터페이스 (위 예제에서는 Comparator 인터페이스) 를 바로 new 연산자를 통해 사용하고, 구체적인 전략은 익명 클래스 내부에 작성함으로써 전략 패턴의 장점도 사용할 수 있다. 하지만 매우 간단한 코드임에도 불구하고 매우 길다.
Java 8 부터는 추상 메서드 하나짜리 인터페이스는 람다식으로 간결하게 작성할 수 있다.
매개변수와 반환값에 대한 타입은 각각 String 과 Int 이지만 생략할 수 있다. 컴파일 타임 때 컴파일러가 맥락을 파악하고 자동으로 타입을 추론해주기 때문에 가능하다. 간혹 컴파일러가 타입을 추론하지 못해 컴파일 오류가 발생할 수도 있지만, 그럴 때 직접 프로그래머가 명시하면 된다. 타입을 명시해야 코드가 명확한 경우를 제외하고 람다의 모든 매개변수 타입은 생략하자.
각 묶음의 카드의 개수가 A, B 라고 주어질 때, 한 번 두 묶음을 합칠 때 A+B 번의 비교를 해야한다. 만약 A, B, C, D 의 카드 개수를 순서대로 하나로 합치려고 할 때, (A+B) + ((A+B)+C) + ((A+B+C)+D) 번 총 비교해야 한다.
카드의 개수가 연속으로 주어질 때, 최소한 몇 번 비교해야 하는지 알아내시오.
2.문제예제
3.문제풀이(수동)
주어진 문제예제를 살펴보면, (10+20) 번 비교하고, 다시 그 묶음을 40 번과 비교해서 (10+20) + (30+40) 번 비교해야 한다. 정렬이 되어 있지 않는 경우도 살펴볼 수 있다. 10, 20, 28, 25 라면, (10+20) 번 비교하고, (28+25) 번 비교한 다음 두 카드비교를 더해 (10+20) + (28+25) + (10+20) + (28+25) 로 최소 166 번 비교할 수도 있다.
4.팩트추출
Fact 1: 한 번 합쳐진 값도 다시 하나의 값으로 인식해서 나머지 다른 값들과 비교해 최소끼리 계속 더해야 한다.
문제풀이(수동) 두 번째 예제를 보면 10+20 번 비교해서 한 번 합쳐진 값이 다른 값들과 비교하는데 나머지 25, 28 숫자보다 커서 25와 28끼리 합쳐야 한 것을 볼 수 있다.
Fact 2: Fact 1 번을 통해 연산한 결과 값들도 나머지 다른 값들과 함께 정렬되어 다시 연산에 쓰여야 된다는 것을 알 수 있다. 다시 말해보면, 삽입하면서 정렬이 되고 그 중 항상 최소값을 가져와야 한다.
5.문제전략
Fact 2 번을 통해 연산한 결과 값이 삽입하면서 정렬이 되어야 하고, 항상 최소값을 가져와야 한다는 점 때문에 우선순위 큐를 사용하면 된다.
5.소스코드
import java.io.*;
import java.util.PriorityQueue;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
int N = Integer.parseInt(br.readLine());
long total = 0;
PriorityQueue<Long> pq = new PriorityQueue<>();
for (int i = 0; i < N; i++) {
long cardValue = Long.parseLong(br.readLine());
pq.add(cardValue);
}
while (pq.size() > 1) {
long first = pq.poll();
long second = pq.poll();
total += first + second;
pq.add(first + second);
}
System.out.println(total);
}
}