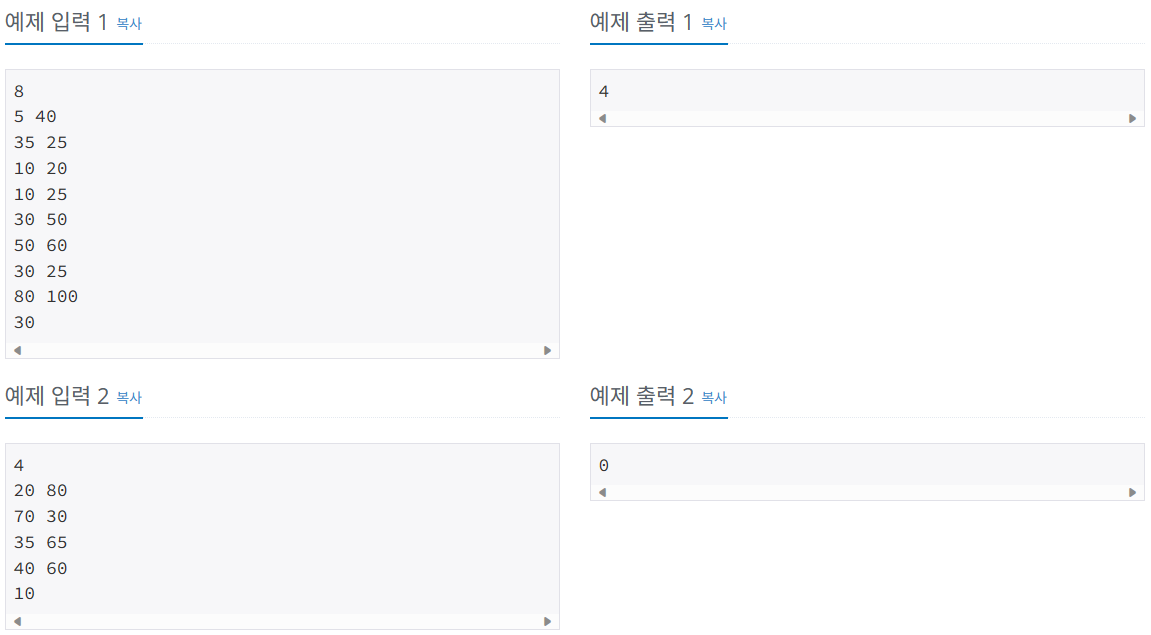
집과 사무실의 시작점, 끝점과 주어진 길이 d 가 주어질 때, 길이 d 에 포함되는 집과 사무실 구간의 개수가 최대인 경우를 구하시오.
2.문제예제
3.문제풀이(수동)
예제들을 문제풀이하면서 아이디어를 얻을 수는 없다. 아래 팩트추출을 통해 모든 경우의 수를 점검해야 한다.
4.팩트추출
Fact 1: 범위가 포함이 되어있는지 확인할 때, 나머지 좌표들을 정렬하면 다른 한 쪽만 대소비교할 수 있어 복잡도를 줄일 수 있다. 아래는 구간들의 오른쪽 끝점을 기준으로 오름차순으로 정렬한 모습이다. 가장 아래쪽부터 1번, 2번, 3번이라고 지칭할 때 다양한 특징들이 발견된다.
먼저 1번을 기준으로 2번이 포함되지 않는다면 3번, 4번에서도 2번은 포함되지 않는다. (오른쪽 끝점이 계속 순차적으로 증가하는 형태이기 때문에) 한 번 제외된 구간은 다른 구간에서 계산할 때도 제외된다는 뜻이다.
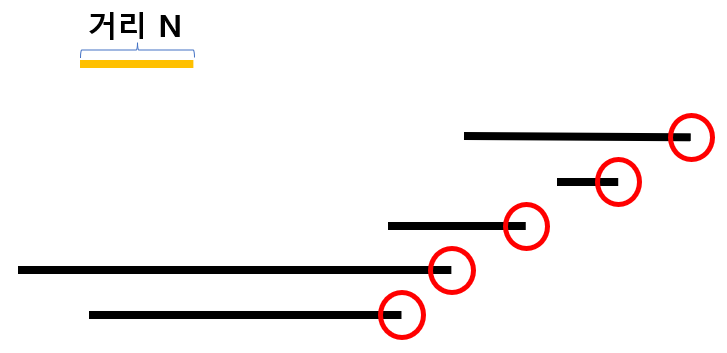
Fact 2 : 거리 N 에 포함되지 않는 구간은 계산할 필요가 없다.
Fact 3: 이전 결과에서는 거리 N 에 포함이 되었더라도 다음에 계산할 때는 오른쪽 끝점이 이동하므로 포함되지 않을 수 있다. 이전 결과를 활용하기 위해 시작점도 정렬이 필요하다. 거리 N 에 포함되면 시작점을 포함했다가 오른쪽 끝점이 이동할 때 정렬되어 있는 시작점들에서 하나씩 꺼내 비교하면 모두 다 비교하지 않아도 된다.
5.문제전략
한 쪽을 정렬해서 이전 결과 값을 재활용해야 한다는 점, 다른 한 쪽도 삽입을 하면서 정렬을 해야한다는 점을 파악해야 한다. 삽입하면서 정렬하는 자료구조는 우선순위큐가 적절하다.
5. 소스코드
private static class Interval implements Comparable<Interval> {
int start, end;
Interval(int startVariable, int endVariable) {
start = startVariable;
end = endVariable;
}
@Override
public int compareTo(Interval o) {
return Integer.compare(this.end, o.end);
}
}
public static void main(String[] args) {
// 거리 N, Interval 은 집과 구간, 오른쪽 끝점으로 정렬
// ... (생략) ...
PriorityQueue<Integer> pq = new PriorityQueue<>();
for (Interval interval : intervals) {
if (interval.start >= interval.end - N) {
count++;
pq.add(interval.start);
}
while (!pq.isEmpty() && pq.peek() < interval.end - N) {
pq.poll();
count--;
}
maximum = Math.max(maximum, count);
}
}
마커 인터페이스란, "아무 메서드도 담고 있지 않고, 단지 자신을 구현하는 클래스가 특정 속성을 가짐을 표시해주는 인터페이스"이다. 예를 들어 아래와 같은 Cloneable 인터페이스나 Serializable 인터페이스 등이 있다.
public interface Cloneable {
}
Serializable 인터페이스를 구현한 클래스의 인스턴스들은 ObjectOutputStream을 통해 write 할 수 있다고, 즉 직렬화(serialization)할 수 있다고 "Serializable" 단어만으로도 바로 알 수 있다. 마커 애너테이션도 같은 역할을 한다. 그렇다면 마커 인터페이스와 마커 애너테이션은 어느 특징을 가지고 있고 언제 사용해야 하는지 확인해보자.
마커 인터페이스가 마커 애너테이션보다 나은 점은 다음과 같다.
1 . 타입으로 사용가능하다.
마커 인터페이스를 구현한 클래스의 인스턴스들은 타입으로 구분할 수 있으나, 마커 애너테이션은 그렇지 않다. 마커 인터페이스는 어엿한 타입이기 때문에, 마커 애너테이션을 사용했다면 런타임에야 발견될 오류를 컴파일타임에 잡을 수 있다.
2 . 마커 인터페이스는 적용 대상을 더 정밀하게 지정할 수 있다.
애너테이션은 @Target 이라는 메타 애너테이션을 통해 TYPE, FIELD, METHOD, PARAMETER, CONSTRUCTOR, LOCAL_VARIABLE 에만 적용할 수 있다. 만약 특정 인터페이스를 구현한 클레스에만 적용하고 싶은 마커가 있을 경우, 애너테이션만으로는 더 세밀하게 제한할 수 없다. 마커 인터페이스를 통해 구현하면 그 인터페이스의 하위 타입임을 보장할 수 있다.
마커 인터페이스가 마커 애너테이션이 마커 인터페이스보다 나은 점은 다음과 같다.
스프링같이 거대한 애너테이션 시스템의 지원을 받아 손쉽게 사용할 수 있다. 애너테이션을 적극 활용하는 프레임워크에서는 마커 애너테이션을 쓰는 쪽이 일관성을 지키는 데 유리하다.
마커 인터페이스를 사용해야 하는 경우
마킹이 된 객체를 매개변수로 받는 메서드를 작성할 필요가 있다면 반드시 인터페이스를 사용해야 한다. 컴파일타임에 오류를 잡을 수 있는 강점이 있다.
마커 애너테이션을 사용해야 하는 경우 클래스와 인터페이스 외 프로그램 요소 (모듈, 패키지, 필드, 지역변수 등)에 마킹해야 할 때는 애너테이션을 쓸 수 밖에 없다. 클래스와 인터페이스만이 인터페이스를 구현하거나 확장할 수 있기 때문이다. 애너테이션을 활발히 활용하는 프레임워크를 사용하는 경우에도 사용할 수 있다.
INSERT INTO Bugs_2010 (..., date_reported, ...)
VALUES (..., '2010-06-01', ...);
INSERT INTO Bugs_2011 (..., date_reported, ...)
VALUES (..., '2011-02-20', ...);
날짜연도에 따라서 테이블을 생성해야 하는데 테이블 생성하는 것을 잊어버렸다면 에러가 발생할 수 있다.
또한, 한 해 동안 버그 개수를 세보려고 하는데 통계 정합성이 맞지 않을 수 있다. 2010 년 관련 값이 Bugs_2009 테이블에 삽입되었던 것이다. 잘못된 어플리케이션의 로직을 방어하기 위해 데이터베이스 기준으로 제약할 수 있는 방법이 있긴 하다. 아래와 같이 CEHCK 조건을 필드에 적용하면 된다.
UPDATE 구문으로 단순히 데이터를 변경하고 싶지만, 테이블을 나눈 기준 열 칼럼의 값이 바뀌면 해당 테이블에서 삭제하고 다른 테이블에 데이터를 옮겨야한다.
INSERT INTO Bugs_2009 (bug_id, date_reported, ...)
SELECT bug_id, date_reported, ...
FROM Bugs_2010
WHERE bug_id = 1234;
DELETE FROM Bugs_2010 WHERE bug_id = 1234;
3 . 유일성 보장
테이블을 나누는 기준인 PK 칼럼은 유일함이 보장되어야 한다. 한 테이블에서 다른 테이블로 행을 옮겼을 때 PK 값이 다른 행과 충돌하지 않는다는 확신이 있어야 한다.
4 . 여러 테이블에 걸쳐 조회
여러 테이블에 걸쳐 조회할 필요가 생길 때 분리된 모든 테이블을 UNION 으로 묶어서 재구성한 다음 쿼리를 실행해야 한다.
SELECT b.status COUNT(*) AS count_per_status FROM (
SELECT * FROM Bugs_2008
UNION ALL
SELECT * FROM Bugs_2009
UNION ALL
SELECT * FROM Bugs_2010 ) AS b
GROUP BY b.status;
5 . 테이블에 새로운 칼럼 추가 시 모두 변경
테이블에 새로운 칼럼 추가 시 모든 분리된 테이블에 똑같은 칼럼을 추가해야 한다.
[해결방법]
수평 분할 사용과 수직 분할 사용을 고려할 수 있다.
1 . 수평 분할
행을 여러 파티션으로 분리하는 규칙과 함께 논리적 테이블을 생성하는 것만으로도 충분하다. 물리적으로는 테이블이 분리되었지만, 논리적으로는 하나의 테이블처럼 사용할 수 있다.
CREATE TABLE Bugs (
bug_id SERIAL PRIMARY KEY,
...
date_reported DATE
) PARTITION BY HASH (YEAR(date_reported))
PARTITIONS 4;
테이블을 직접 분리했을 때랑 다르게 잘못된 데이터가 분리된 테이블로 들어갈 위험이 없다는 장점이 있다. 분리 기준이 되었던 칼럼의 값을 업데이트해도 문제가 없고 분리 테이블을 모두 접근해서 쿼리를 할 필요도 없다.
다만, 위 예제에서 4년 이상이 된 데이터가 있다면, 파티션 중 하나에는 두 연도의 데이터가 들어갈 수 있다.
2 . 수직 분할
수직 분할은 테이블에 있는 칼럼 중 크기가 아주 큰 칼럼이거나 거의 사용되지 않는 칼럼이 있을 경우 고려할 수 있는 방법이다. BLOB 이나 TEXT 칼럼은 크기가 가변적이고 매우 커질 수 있는 칼럼이라서 같은 테이블에서 조회 & 수정 & 삭제 시 성능 저하를 초래한다. 거의 사용되지 않는 칼럼도 리소스 낭비가 있을 뿐이다. 이렇게 가변적이거나 크기가 아주 크거나 자주 사용되지 않는 칼럼들만 모아서 별도의 종속 테이블로 분리하는 것이 좋다.
// 고정 크기의 타입만 정의
CREATE TABLE Bugs (
bug_id SERIAL PRIMARY KEY,
summary CHAR(80),
date_reported DATE,
reported_by BIGINT UNSIGNED,
FOREIGN KEY (reported_by) REFERENCES Accounts(account_id)
)
// 가변 크기의 타입만 정의
CREATE TABLE BugDescriptions (
bug_id BIGINT UNSIGNED PRIMARY KEY,
description VARCHAR(1000),
resolution VARCHAR(1000),
FOREIGN KEY (bug_id) REFERENCES Bugs(bug_id)
)
@Override 애너테이션은 해당 메서드가 상위 타입의 메서드를 재정의한다는 애너테이션이다.
메서드 선언에만 사용할 수 있고, 꼭 붙이지 않아도 되지만 재정의를 하려고 한다면 붙이는 것을 권장한다. 컴파일 타임 단계에서 자칫 오버로딩(Overloading) 으로 메서드를 선언하는 실수를 방지해준다.
public class Bigram {
private final char first;
private final char second;
public Bigram(char first, char second) {
this.first = first;
this.second = second;
}
public boolean equals(Bigram b) {
return b.first == first && b.second == second;
}
public int hashCode() {
return 31 * first + second;
}
public static void main(String[] args) {
Set<Bigram> s = new HashSet<>();
for (int i = 0; i < 10; i++)
for (char ch = 'a'; ch <= 'z'; ch++)
s.add(new Bigram(ch, ch));
System.out.println(s.size());
}
}
위와 같이 equals 메서드를 작성했을 때 HashSet 은 중복을 허용하지 않는 자료구조이기에 26 이라는 값이 출력될 것이라고 예상하지만, 260 이 출력된다. HashSet 에서 사용하는 실제 Object 클래스의 equals 메서드의 원형은 다음과 같다.
public boolean equals(Objecto)
하지만 예제에서는 Bigram 을 인자로 받는 equals 메서드를 오버로딩 하게 되었고, Object 의 equals 메서드의 기본 형태인 == 를 통해 객체의 식별성만 확인하다 보니 260 이라는 잘못된 값이 나오게 된 것이다. 이처럼 @Override 애너테이션을 붙이지 않고 직접 작성하면 타입을 잘못 작성하는 실수를 하게 된다.
만약 @Override 라는 애너테이션을 붙이고 위와 같이 타입을 잘못 작성하게 되면 아래와 같이 컴파일 오류가 발생하기 때문에 올바르게 바로 수정할 수 있다.
method does not override or implement a method from a supertype
↓ (올바르게 수정되었을 때 모습)
@Override
public boolean equals(Object o) {
if (!(o instanceof Biagram)) {
return false;
}
Biagram b = (Biagram) o;
return b.first == first && b.second == second;
}
위 예제처럼 살펴보았듯이 가급적 상위 클래스의 메서드를 재정의하려는 모든 메서드에 @Override 애너네이션을 다는 것을 권장한다. 구체 클래스에서 상위 클래스의 추상 메서드를 재정의한 경우에는 애너테이션을 달지 않아도 되지만 달아도 해로울 것은 없다. (구체 클래스인데 아직 구현하지 않은 추상 메서드가 남아 있다면 컴파일러가 바로 그 사실을 알려주긴 한다.)
어떤 사람에 대한 정보를 DB 에 저장할 때 취미가 여러 개라면 아래와 같이 여러 칼럼에 나누어 저장하는 안티패턴을 생각할 수 있다.
CREATE TABLE Person (
person_number INT PRIMARY KEY,
name VARCHAR(10),
hobby1 VARCHAR(20),
hobby2 VARCHAR(20),
hobby3 VARCHAR(20),
)
해당 구조는 아래와 같이 여러 단점을 가지고 있다.
1 . 검색 문제
원하는 정보가 어느 칼럼에 있는지 모르기 때문에 모든 필드들을 확인해야 한다.
hobby1, hobby2, hobby3 이 모두 null 로 초기화되어 있는 상태에서 하나씩 hobby 를 추가하기 때문에 찾으려고 하는 값이 어느 위치에 있는지 확인하기 어렵다.
SELECT *
FROM Person
WHERE hobby1 = 'soccer'
OR hobby2 = 'soccer'
OR hobby3 = 'soccer';
취미가 축구인 사람을 찾기 위해 모든 다중 속성 칼럼들에 대해 찾는 것을 볼 수 있다.
2 . 수정 문제
마찬가지로 여러 칼럼 중 어떤 칼럼을 수정해야 할지 먼저 검색을 해야한다는 것이 단점이다. 그런데 이마저도 동시성 문제가 존재하여 둘 중 하나는 충돌로 인해 업데이트에 실패하거나 변경 내용을 덮어쓸 수 있다. 그래서 아래와 같이 NULLIF 함수를 통해 칼럼 값이 특정 값과 같으면 NULL 로 만드는 작업을 해야해서 번거롭다.
먼저 삭제 코드는 다음과 같다.
UPDATE Person
SET hobby1 = NULLIF(hobby1, 'soccer'),
hobby2 = NULLIF(hobby2, 'soccer'),
hobby3 = NULLIF(hobby3, 'soccer')
WHERE person_number = '~';
만약에 첫 번째 NULL 인 칼럼에 추가하는 작업을 하는 코드를 만들어 본다고 생각해보자. 각 칼럼마다 NULL 이 아니면 아무런 변경도 가하지 않고 새 태그 값은 기록하지 않는 과정을 해야할 것이다.
3 . 일관성 문제
일관성도 문제다. 여러 칼럼에 중복되는 값이 입력될 수 있다.
4 . 확장 문제
취미가 하나 더 필요하다면, 해당 테이블 칼럼을 확장해야 하는데 이 때 테이블 전체를 잠금 설정하고 모든 클라이언트의 접근을 차단하는 과정이 필요하게 된다. 예전 구조의 데이터들을 마이그레이션해야하고, 그 양도 많다면 작업 시간이 많이 걸릴 수 있다. 또한 해당 테이블을 사용하는 모든 애플리케이션의 SQL 구문을 변경해야 한다.
[해결방법]
다중 속성 칼럼들을 종속 테이블로 변환 생성해서 사용하면 된다.
CREATE TABLE person (
person_number INT PRIMARY KEY,
name VARCHAR(10),
);
CREATE TABLE Hobby (
person_number INT FOREIGN KEY REFERENCES person(person_number)
hobby_name VARCHAR(10)
);
모든 문제를 해결할 수 있다.
1 . 검색 해결
SELECT *
FROM Person JOIN Hobby USING (hobby_id)
WHERE hobby_name = 'soccer';
두 개의 취미를 가진 사람도 손쉽게 찾을 수 있다.
SELECT * FROM Person
JOIN Hobby AS h1 USING (hobby_id)
JOIN Hobby AS h2 USING (hobby_id)
WHERE h1.hobby_name = 'soccer' AND h2.hobby_name = 'sing';
2 . 수정 해결
수정 문제도 쉽게 해결 할 수 있다. 단순히 종속 테이블에 행을 추가하거나 삭제하면 된다.
--- 수정
INSERT INTO Hobby (member_id, hobby_name) VALUES (1, 'soccer');
--- 삭제
DELETE FROM Hobby WHERE member_id = 1 AND hobby_name = 'soccer';
예전 프레임워크들을 살펴보면 이름을 통해 제약을 하는 경우가 있다. 예를 들어 Junit 버전 3까지는 테스트 메서드 이름을 무조건 test 로 시작했어야 했다. 이런 경우를 명명 패턴이라고 하는데 이번 절에서는 이런 명명 패턴을 사용하는 것보다 애너테이션을 사용하도록 권장하고 있다.
명명 패턴을 사용하면 오타가 나면 절대 안 된다. test 로 시작해야 하는데 tset 으로 오타를 치면 Junit3 에서는 그냥 무시하고 지나가기 때문에 통과했다고 오해할 수 있다.
또한, 올바른 프로그램 요소에 사용되라라 보장할 방법이 없다. Junit3 의 테스트 단위는 메서드인데 클래스만 test 로 이름을 짓고 넘겼다고 가정해보자. 개발자는 테스트가 수행되었을 것이라고 기대했겠지만, Junit 의 테스트 대상이 아니어서 통과된다.
프로그램 요소를 매개변수로 전달할 방법이 없다는 것도 문제이다. 특정 예외를 전달해야만 성공하는 테스트가 있다고 가정해보자. 기대하는 예외 타입을 매개변수로 전달해야 하는데 명명패턴이다보니 제약할 방법이 없다. 예외 이름을 테스트 메서드 이름에 덧붙이는 방식으로 할 수도 있지만 이 방법은 보기도 나쁘고 깨지기도 쉽다.
애너테이션은 이런 모든 문제점을 해결해준다. 애너테이션을 활용해서 테스트 프로그램(예외가 발생하면 테스트 실패)을 작성해보자.
/**
* 테스트 메서드임을 선언하는 애너테이션이다.
* 매개변수 없는 정적 메서드 전용이다.
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface Test {
}
Target : 어떤 프로그램 요소에 사용되어야 하는지 알려주는 애너테이션이다. (예제에서는 메서드에만 적용 가능)
아쉽게도 매개변수가 없다는 제약을 줄 수는 없는데 이를 컴파일러가 강제하게 하려면 javax.annotation.processing API 문서처럼 직접 구현해야 한다. 구현하지 않는다면 컴파일은 잘 되겠지만, 테스트 할 때 문제가 생긴다.
이렇게 구현해두면 마킹을 하듯이 애너테이션을 붙일 수 있어 원래 클래스에 직접적인 영향을 주지 않으면서 테스트할 범위를 정할 수 있다는 장점이 있다. 해당 애너테이션을 사용하는 구현부를 작성해보자.
public class RunTests {
public static void main(String[] args) throws Exception {
int tests = 0;
int passed = 0;
Class<?> testClass = Class.forName(args[0]);
for (Method m : testClass.getDeclaredMethods()) {
if (m.isAnnotationPresent(Test.class)) {
tests++;
try {
m.invoke(null);
passed++;
} catch (InvocationTargetException wrappedExc) {
Throwable exc = wrappedExc.getCause();
System.out.println(m + " 실패: " + exc);
} catch (Exception exc) {
System.out.println("잘못 사용한 @Test: " + m);
}
}
}
System.out.printf("성공: %d, 실패: %d%n",
passed, tests - passed);
}
}
리플렉션과 클래스 이름을 활용해서, @Test 애너테이션이 달린 메서드를 차례로 호출하는 것을 볼 수 있다. 테스트 메서드가 예외를 던지면, 리플렉션 메커니즘이 InvocationTargetException 으로 감싸서 예외를 다시 던진다. 이 프로그램은 해당 예외를 잡아 실패 정보를 추출해 출력한다. InvocationTargetException 외 다른 예외가 발생했다면 @Test 애너테이션을 잘못 사용한 것이다.
Class<? extends Throwable> 타입으로 인자를 받기 때문에 모든 예외와 오류 타입을 수용할 수 있다. 사용부는 다음과 같다.
public class Sample2 {
@ExceptionTest(ArithmeticException.class)
public static void m1() { // 성공해야 한다.
int i = 0;
i = i / i;
}
@ExceptionTest(ArithmeticException.class)
public static void m2() { // 실패해야 한다. (다른 예외 발생)
int[] a = new int[0];
int i = a[1];
}
@ExceptionTest(ArithmeticException.class)
public static void m3() { } // 실패해야 한다. (예외가 발생하지 않음)
}
더 나아가 여러 개의 예외를 인자로 전달해서 그 중 하나가 발생하면 성공하게 만들 수도 있다.
/**
* 배열 매개변수를 받는 애너테이션
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface ExceptionTest {
Class<? extends Throwable>[] value();
}
[] 배열이 추가되었다. Class 타입들을 배열로 인자를 받아 처리하는데 기존 한 개 매개변수도 처리할 수 있다는 장점이 있다. 수정없이 사용 가능하다. 원소가 여럿인 배열들을 지정할 때 아래와 같이 원소들을 중괄호로 감싸고 쉼표로 구분하면 된다.
@ExceptionTest({IndexOutOfBoundsException.class, NullPointerException.class})
public static void doublyBad() { // 성공해야 한다.
List<String> list = new ArrayList<>();
// 자바 API 명세에 따르면 다음 메서드는 IndexOutOfBoundsException이나
// NullPointerException을 던질 수 있다.
list.addAll(5, null);
}
(... 생략 동일 ...)
int oldPassed = passed;
Class<? extends Throwable>[] excTypes =
m.getAnnotation(ExceptionTest.class).value();
for (Class<? extends Throwable> excType : excTypes) {
if (excType.isInstance(exc)) {
passed++;
break;
}
}
if (passed == oldPassed) {
System.out.printf("테스트 %s 실패: %s %n", m, exc);
}
(... 생략 동일 ...)
3) (자바 8 방식)여러 개의 예외를 인자로 전달
자바 8 부터는 위 방식 대신 @Repeatable 메타애너테이션을 사용하여 하나의 프로그램 요소에 여러 번 달 수 있다.
단 주의할 점이 있다. 아래 3가지 주의사항을 만족하지 않는다면 컴파일되지 않는다.
첫 째. @Repeatable 을 단 애너테이션을 반환하는 '컨테이너 애너테이션'을 하나 더 정의하고, @Repeatable 에 이 컨테이너 애너테이션의 Class 객체를 매개변수로 전달해야 한다.
둘 째. 컨테이너 애너테이션은 내부 애너테이션 타입의 배열을 반환하는 value 메서드를 정의해야 한다.
처리할 때도 주의가 필요하다. getAnnotaionByType 메서드는 컨테이너 애너테이션과 반복 가능 어노테이션을 구분하지 못 하는데, isAnnotationPresent 메서드는 명확하게 구분한다. 하지만 여러 번 달린 애너테이션은 구분하기가 힘들어 컨터이너 쪽과 반복 가능 어노테이션 쪽 모두를 검증해야 한다.
if (m.isAnnotationPresent(ExceptionTest.class) || m.isAnnotationPresent(ExceptionTestContainer.class))
{
...
}
enum 열거 타입은 확장할 수 없다. 확장이 가능하다면 기반이 되는 타입과 확장이 되는 타입들의 원소 모두를 순회하는 방법이 있어야 하는데 방법이 마땅치 않다.
그런데도 확장이 가능한 enum 타입이 필요할 때가 있는데 대표적인 예가 연산코드이다. 연산코드 같이 명령어들을 열거타입으로 만들 때 보통 사용자가 확장 연산을 추가할 수 있도록 열어주기 때문에 확장이 용이해야 한다.
다행히 enum 타입이 인터페이스를 구현할 수 있어, 행위 자체를 인터페이스에 명명하고 그 인터페이스를 구현하면 된다.
public interface Operation {
double apply(double x, double y);
}
public enum BasicOperation implements Operation {
PLUS("+") {
@Override
public double apply(double x, double y) {
return x + y;
}
},
MINUS("-") {
@Override
public double apply(double x, double y) {
return x - y;
}
},
TIMES("*") {
@Override
public double apply(double x, double y) {
return x * y;
}
},
DIVIDE("/") {
@Override
public double apply(double x, double y) {
return x / y;
}
};
private final String symbol;
BasicOperation(String symbol) {
this.symbol = symbol;
}
@Override
public String toString() {
return symbol;
}
}
위와 같이 구현하면 BasicOperation Enum 자체는 확장할 수 없지만, 인터페이스인 Operation 은 확장할 수 있기 때문에, 이 인터페이스를 타입으로 사용하면 된다. 사칙연산에 이어서 지수 곱, 나머지 연산자를 추가하고 싶다면 아래와 같이 만들 수 있다.
public enum ExtendedOperation implements Operation {
EXP("^") {
@Override
public double apply(double x, double y) {
return Math.pow(x, y);
}
},
REMAINDER("%") {
@Override
public double apply(double x, double y) {
return x % y;
}
};
private final String symbol;
ExtendedOperation(String symbol) {
this.symbol = symbol;
}
@Override
public String toString() {
return symbol;
}
}
사용부에서 인터페이스를 사용하도록 작성되어 있다면, BasicOperation Enum 을 ExtendedOperation Enum 으로 교체할 수도 있다. 이미 인터페이스 내부에 메서드들이 명명되어 있어 열거 타입에 따로 추상 메서드를 선언하지 않아도 된다. (Enum 상수별 메서드 구현)
사용할 때는 아래 두 가지 방법이 존재한다.
1) 클래스 타입을 인자로 전달
public enum ExtendedOperation implements Operation {
public static void main(String[] args) {
double x = Double.parseDouble(args[0]);
double y = Double.parseDouble(args[1]);
test(ExtendedOperation.class, x, y);
}
private static <T extends Enum<T> & Operation> void test(Class<T> opEnumType, double x, double y) {
for (Operation operation : opEnumType.getEnumConstants()) {
System.out.printf("%f %s %f = %f%n", x, operation, y, operation.apply(x, y));
}
}
}
한정적 타입 토큰 역할을 하는 Class 리터럴을 전달하고, 그 리터럴의 getEnumConstants() 함수를 사용해서 접근한다.
Class 객체가 열거 타입인 동시에 Operation 의 하위 타입어야 하기 때문에 함수의 타입은 <T extends Enum<T> & Operation> 이어야 한다. 열거 타입이어야 원소를 순회할 수 있고, Operation 이어야 원소가 뜻하는 연산을 할 수 있기 때문이다.
2) 한정적 와일드카드 타입을 인자로 전달
public enum ExtendedOperation implements Operation {
public static void main(String[] args) {
double x = Double.parseDouble(args[0]);
double y = Double.parseDouble(args[1]);
test(Arrays.asList(ExtendedOperation.values()), x, y);
}
private static void test(Collection<? extends Operation> operations, double x, double y) {
for (Operation operation : operations) {
System.out.printf("%f %s %f = %f%n", x, operation, y, operation.apply(x, y));
}
}
}
enum 타입의 값들을 컬렉션 형태로 전달하면 여러 구현 타입의 연산을 조합해 호출할 수 있다는 장점이 있다.
다만 특정 연산(EnumSet, EnumMap) 은 사용하지 못 한다.
인터페이스를 이용해 확장 가능한 열거 타입을 흉내내는 이 방식에도 아래와 같은 문제점이 존재한다.
열거 타입끼리는 구현을 상속할 수 없다.
아무 상태에도 의존하지 않는 경우라면, 인터페이스를 구현한 enum 타입들에 직접 로직들을 작성해야 한다. (중복되는 로직이 많아진다면 정적 도우미 메서드나 클래스로 분리해야 한다.)
useState 를 구현해보면 위와 같다. 초기값을 인자로 받아 내부 변수에 세팅하고, 그 변수를 활용한 함수들을 리턴하는 것을 볼 수 있다. 내부 상태 값을 반환하는 함수와 갱신하는 함수를 배열 형태로 리턴하면 React 에서 흔히 사용하는 useState 와 유사하다.
하지만 hook 을 여러 번 사용한다면 위와 같은 구조는 정상적으로 동작하지 않게 된다. 위 React 모듈에 있는 값은 _val 하나이기 때문이다. 갱신하는 함수를 호출할 때마다 _val 변수가 덮어씌워져 호출이 되지 않는 것이다.
이를 방지하기 위해 배열에 hook 함수들을 배치하고 인덱스를 활용하여 사용해 접근하도록 개선했다.