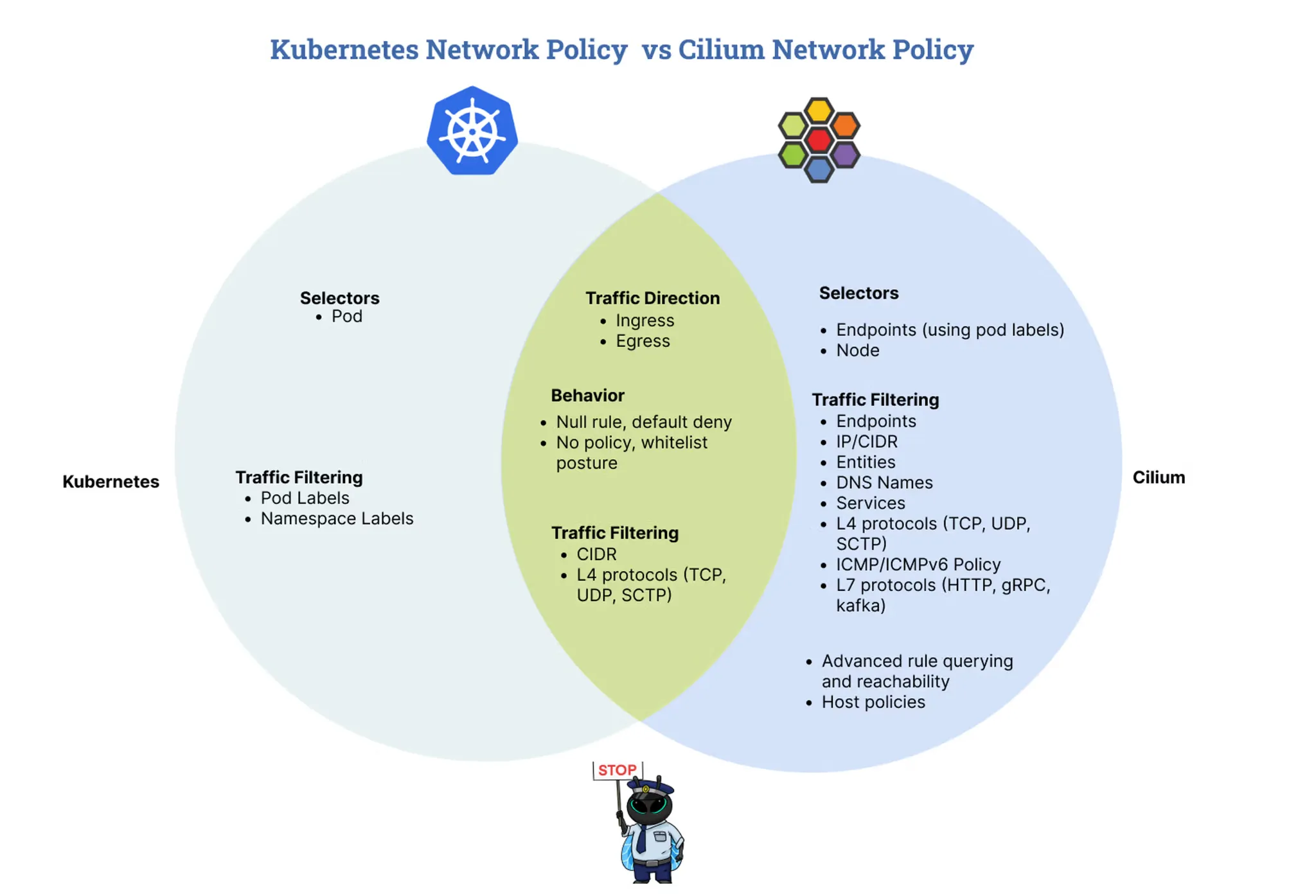
Cilium 은 네트워크의 다양한 계층에서 보안 기능을 제공합니다. Layer 3에서는 Identity-Based 보안을 제공하고, Layer 4에서는 Port Level 보안을, Layer 7에서는 Application protocol Level 보안을 지원합니다.
Layer 3 Identity-Based
Security-ID
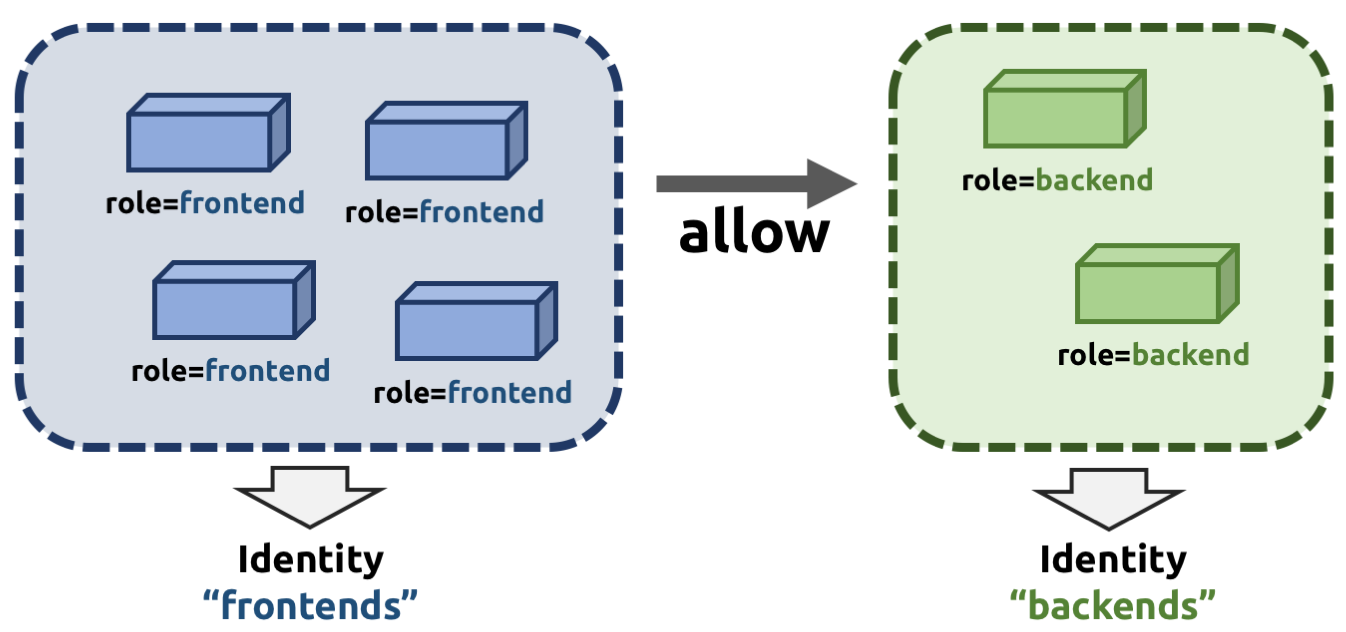
저번 시간에 공유드렸듯이, 쿠버네티스 환경에서 파드들의 IP 가 수시로 변하기 때문에 ip 기반 접근 통제 보다는 id 기반 접근 정책을 통해 파드들의 통신을 제어합니다. Cilium 에서는 모든 엔드포인트에 대해 고유한 ID 가 할당됩니다. 이 ID 는 클러스터 내에서 유일한 ID 로 구성되며, 동일한 Security 정책을 사용하는 엔드포인트들은 동일한 ID 를 공유하게 됩니다.
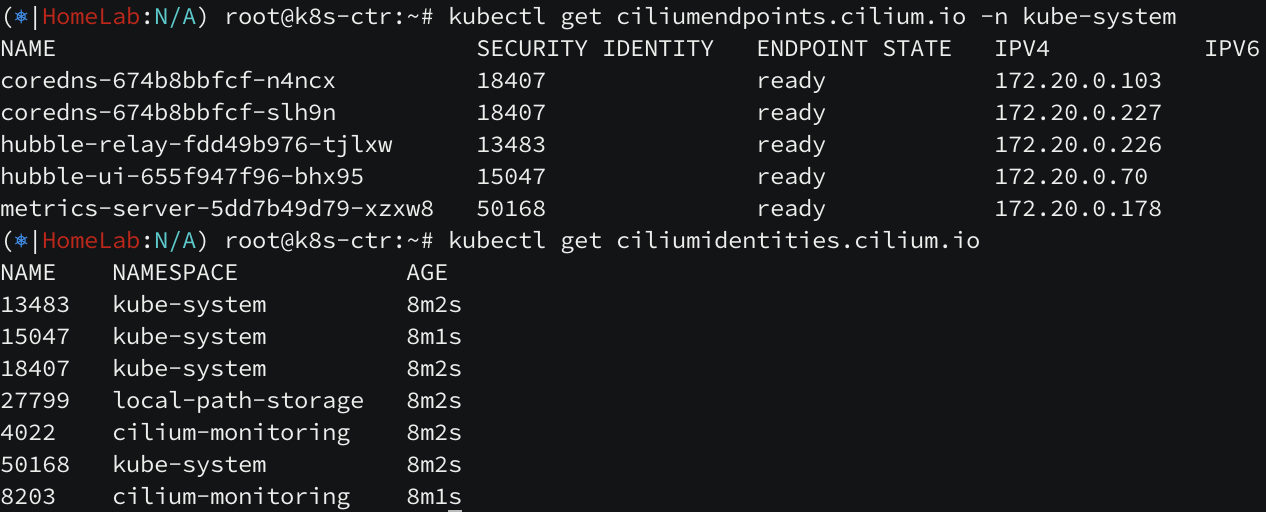
위와 같이 ciliumendpoint 들을 조회했을 때, 동일한 보안 정책을 부여받는 엔드포인트끼리 동일한 security ID 값을 부여받는 것을 알 수 있습니다.
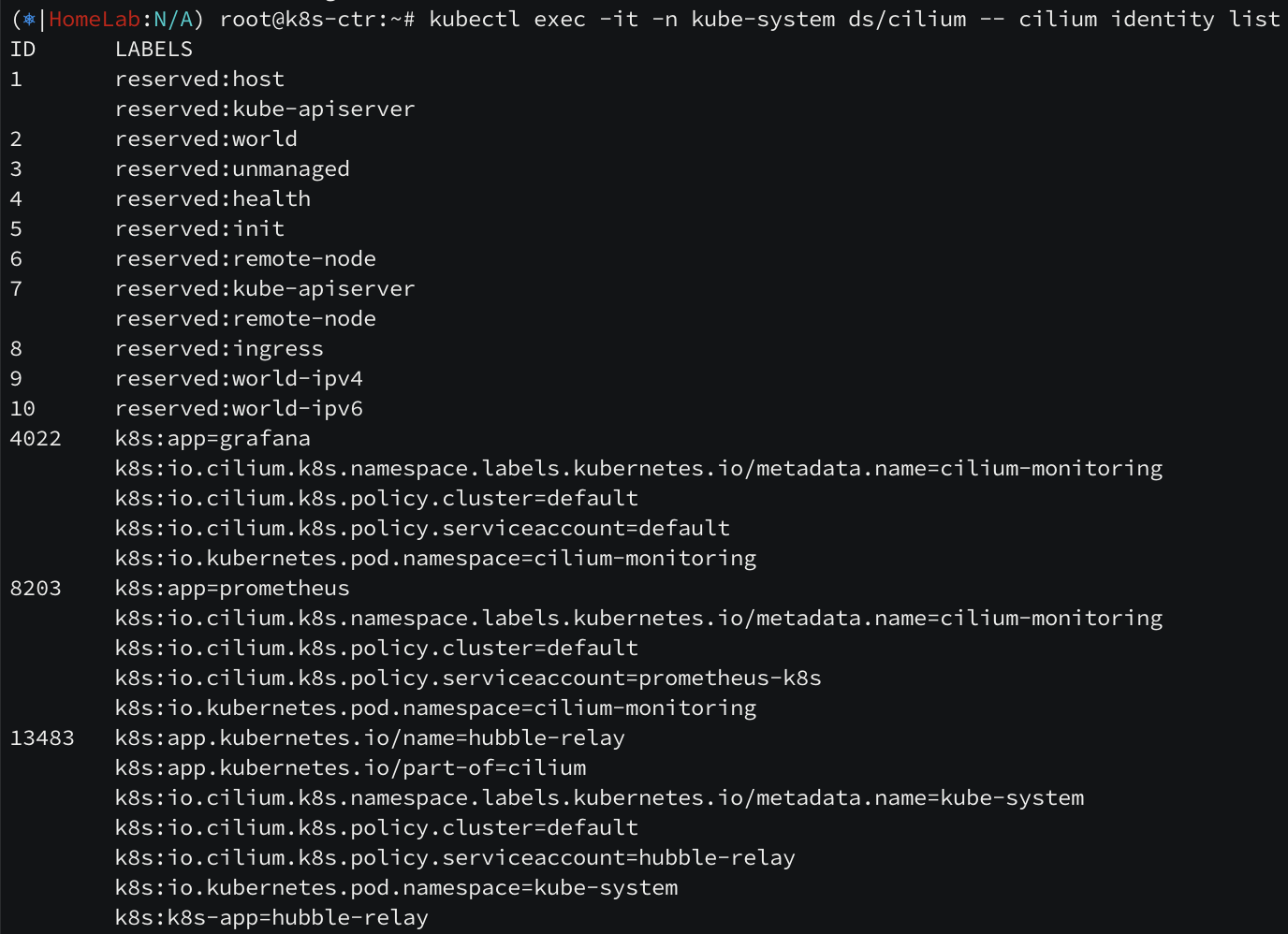
파드 또는 컨테이너가 시작되면 Cilium 은 컨테이너 런타임에서 수신한 이벤트를 기반으로 엔드포인트를 생성합니다. 다음 단계로 Cilium 은 생성된 엔드포인트의 ID 를 확인하며, 포드나 컨테이너의 Labels가 변경될 때마다 ID 가 재확인되고 필요에 따라 자동으로 수정됩니다. Labels 변경 시 endpoint가 waiting-for-identity 상태로 전환되어 새로운 identity 를 할당받게 됩니다. 이로 인해 security labels 와 관련된 네트워크 정책도 자동으로 재적용됩니다. 예를 들어 간단한 pod을 생성하면 초기 security identity 가 할당되고, kubectl label 명령으로 labels 를 변경하면 새로운 identity 값으로 업데이트되는 것을 확인할 수 있습니다.
참고로 security label 중 reserved 문자열 접두사가 붙은 라벨들은 Cilium 에서 관리하지 않는 네트워크 엔드포인트와의 통신을 허용하기 위해 예약된 라벨들입니다.
엔드포인트 기반 정책
두 엔드포인트가 Cilium에 의해 관리되고 레이블이 할당되어 있는 경우 유용합니다. 이 방법의 장점은 IP 주소가 정책에 하드코딩되지 않고 유연하게 대처가 가능하다는 점입니다.
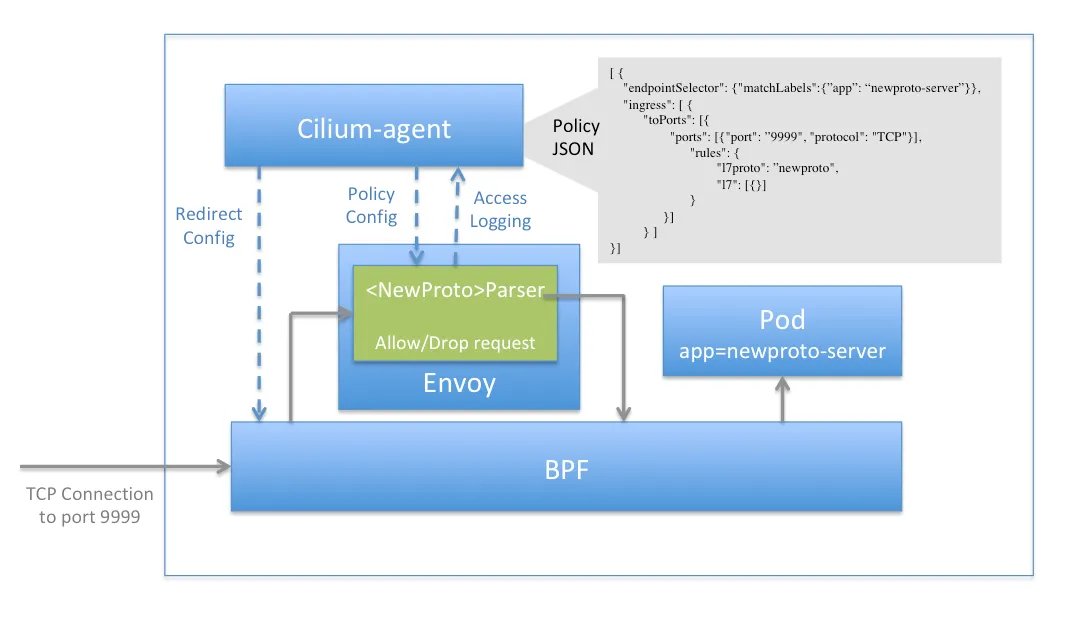
cilium 에서 아래에 해당하는 프로토콜 중 L7 정책을 통해 L7 어플리케이션 트래픽들을 제어할 수 있습니다.
// L7Rules is a union of port level rule types. Mixing of different port
// level rule types is disallowed, so exactly one of the following must be set.
// If none are specified, then no additional port level rules are applied.
type L7Rules struct {
// HTTP specific rules.
//
// +optional
HTTP []PortRuleHTTP `json:"http,omitempty"`
// Kafka-specific rules.
//
// +optional
Kafka []PortRuleKafka `json:"kafka,omitempty"`
// DNS-specific rules.
//
// +optional
DNS []PortRuleDNS `json:"dns,omitempty"`
}
3계층 및 4계층 정책과 달리 7계층 규칙 위반 시 패킷을 드랍하지 않고 애플리케이션 프로토콜별 접근 거부 메시지를 제공합니다. 예를 들어, HTTP 의 경우 403 Forbidden 을, DNS 의 경우, DNS 거부 응답을 보냅니다. 7 계층 정책은 Envoy 프록시를 통해 트래픽을 검사 후 처리를 진행합니다.
HTTP 정책의 경우 Path, Method, Hosts, Headers 를 정책의 구성요소로 사용합니다.
참고로 쿠버네티스에서 DNS 정책을 적용할 때, service.namespace.svc.cluster.local에 대한 쿼리는 명시적으로 허용되어야 합니다. (matchPattern: *.*.svc.cluster.local.) 마찬가지로, FQDN을 완성하기 위해 DNS 검색 목록에 의존하는 쿼리는 전체가 허용되어야 합니다. 예를 들어, servicename로 성공하는 쿼리는 또는 servicename.namespace.svc.cluster.local.로 허용되어야 합니다.
Cilium NetworkPolicy
Cilium 은 표준 Kubernetes 의 Network Policy 보다 더 많은 기능을 제공합니다.
Cilium Network Policy 정책은 statefull 하며 응답 패킷은 자동으로 허용됩니다. 보안 정책은 수신 또는 송신 시점에 적용되어 네트워크 트래픽을 제어합니다. 정책이 로드되지 않은 경우 모든 통신을 기본으로 허용합니다. 하지만 첫 번째 정책 규칙이 로드되는 즉시 정책 적용이 자동으로 활성화되며, 이후부터는 허용 목록 방식으로 동작하여 명시적으로 허용되지 않은 패킷은 드랍됩니다. 마찬가지로 L4 정책이 적용되지 않은 엔드포인트는 모든 포트와의 통신이 허용되지만, 하나 이상의 L4 정책이 연결되면 명시적으로 허용하지 않는 한 모든 연결이 차단됩니다.
마찬가지로, 2개의 레플리카를 10번에 걸쳐 생성하므로 20 개의 오브젝트를 생성 요청하는데 10 개의 bust 만 쓸 수 있으므로 1초씩 진행됩니다. jobIterations: 20, qps: 2, burst:20, objects.replicas: 2
같은 원리로 처음에 조건이 부합하여 한 번에 처리가 진행이 되다가 슬슬 처리가 늦어지는 것을 알 수 있습니다.
시나리오 2: 노드 1대에 최대 파드 배포 (150개)
jobIterations: 100, qps: 300, burst: 300, replicas: 1로 설정하여 최대 150개 파드 배포 테스트 해보겠습니다.
5개의 노드가 아직 pending 상태로 남아있습니다. 원인 파악을 위해 99번 파드에 대해 자세히 살펴보겠습니다.
"Too many pods. preemption: 0/1 nodes are availale:" 라는 메세지를 볼 수 있고, node 의 상태를 확인해보니
모든 가용영역을 다 사용한 것을 볼 수 있습니다.
기본적으로 쿠버네티스는 노드당 110개의 파드만 허용합니다. 더 많은 파드를 배포하려면 다음과 같이 설정을 변경해야 합니다.
# 현재 설정 확인
kubectl get cm -n kube-system kubelet-config -o yaml
# maxPods 설정 변경
docker exec -it myk8s-control-plane bash
cat /var/lib/kubelet/config.yaml
apt update && apt install vim -y
vim /var/lib/kubelet/config.yaml
# maxPods: 150 추가
systemctl restart kubelet
systemctl status kubelet
exit
시나리오 3: 파드 300개 배포 시도
jobIterations: 300, qps: 300, burst: 300 objects.replicas: 1로 설정하여 최대 300개 파드 배포 테스트를 해보겠습니다.
파드 배포하기 전, 넉넉하게 400 개의 maxPod 를 설정하고 테스트를 수행합니다.
# maxPods 설정 변경
docker exec -it myk8s-control-plane bash
cat /var/lib/kubelet/config.yaml
apt update && apt install vim -y
vim /var/lib/kubelet/config.yaml
# maxPods: 400 추가
systemctl restart kubelet
systemctl status kubelet
exit
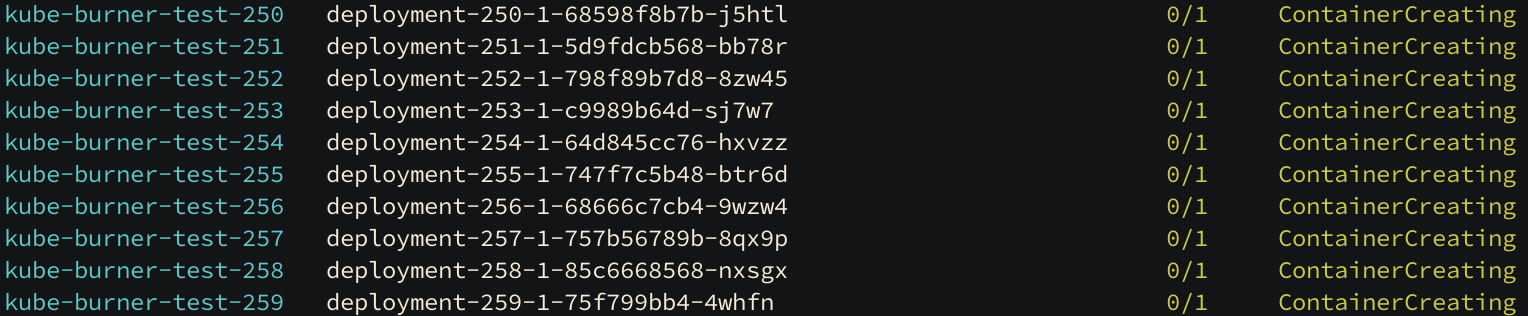
maxPod 를 최대치까지 늘렸는데 containerCreating 된 상태의 pod 들이 존재합니다. pod 로그들을 통해 원인을 파악해보면,
배포 시에 PodCIDR 대역 문제가 발생하는 것을 볼 수 있습니다.("no IP addresses available in range set") 현재 PodCIDR 이 /24 대역(252개 IP)이므로 300개 파드를 생성할 수 없습니다.
K8S Performance
최대 수용 규모와 내부 구조
쿠버네티스의 퍼포먼스를 이해하려면, 쿠버네티스의 내부 구조와 처리 절차들을 이해하고 있어야 합니다.
먼저 쿠버네티스 v1.33 기준 단일 클러스터 최대 수용 규모와 절차들은 다음과 같습니다.
노드 수: 5,000대 이하
노드당 파드 수: 110개 이하
총 파드 수: 150,000개 이하
총 컨테이너 수: 300,000개 이하
Kubernetes는 실제 사용자의 워크로드를 실행하는 Data Plane과 클러스터 전체를 관리하는 Control Plane으로 구성됩니다. Control Plane은 주로 kube-apiserver와 etcd로 구성되며, 이 두 컴포넌트에서 문제가 발생하면 리소스 관리에 심각한 영향을 미칩니다.
etcd 는 데이터 일관성을 위해 Range 요청 처리 중 Store 에 Lock을 걸고 해당 데이터를 복제합니다. 이 과정에서 대량의 메모리가 필요하며, Zero Copy 로 구현할 경우 성능 저하가 심각합니다. 심지어 etcd 관련 api 제약사항이 아래와 같습니다.
etcd 에는 Range API 만 존재하여 대용량 데이터를 한 번에 처리해야 함
kube-apiserver 도 이를 처리할 대안이 제한적
2초간 100건의 동일한 요청이 들어오면 메모리 급증 불가피
문제 발생 조건들을 살펴보면 한 번에 조회 가능한 리소스 개수가 매우 많고, 해당 리소스를 조회하는 요청이 매우 많았습니다.
kube-apiserver는 spec.nodeName에 대한 인덱싱이 없어 etcd에서 모든 Pod를 검색해야 하므로, 결국 전체 데이터를 로드하게 됩니다.
해결 방안
1. API Limit/Continue 활용
limit 과 continue 를 활용해서 한 번에 조회하는 양을 제한하여 메모리 사용량을 덜 사용합니다.
# kubectl의 실제 요청 예시
kubectl get po -v6
# GET /api/v1/namespaces/default/pods?limit=500
# GET /api/v1/namespaces/default/pods?continue=eyJ2IjoibWV0YS5rOHMuaW8vdjEiLCJydiI6MzkzNDcsInN0YXJ0IjoidGVzdC01NzQ2ZDRjNTlmLTJuNTUyXHUwMDAwIn0&limit=500
2. ResourceVersion/ResourceVersionMatch 활용
Strong Consistency 가 필요하지 않은 경우 etcd 에 요청하지 않고 api server 에 존재하는 캐시된 데이터를 사용합니다.
# resourceVersion="0"으로 요청하면 kube-apiserver 캐시에서 데이터 반환
curl "127.0.0.1:8001/api/v1/pods?resourceVersion=0"
이 방법을 사용하면 etcd 부하는 완전히 제거되지만, kube-apiserver 의 OOM은 여전히 발생할 수 있습니다.
100 개의 네임스페이스에 각각 Deployment, ConfigMap, Secret, Service 를 QPS 100 으로 대량 생성하고 생성된 리소스들을 패치하여 API 서버의 UPDATE 성능을 측정합니다. 이후 모든 리소스를 순차적으로 삭제하여 DELETE API 성능까지 종합적으로 테스트하는 예제입니다.
모니터링
다른 클라이언트로부터 받는 kube-apiserver 요청의 개수를 모니터링하고 싶다면, API 서버 QPS를 리소스별, 요청 타입별, 응답 코드별 모니터링을 진행하면 됩니다.
최근 5분간 Kubernetes API 서버가 처리한 요청에 대한 집계
# 응답 코드별 집계
sum by(verb) (irate(apiserver_request_total{job="apiserver"}[5m]))
# 리소스, 응답 코드, verb 별 집계
sum by(resource, code, verb) (irate(apiserver_request_total{job="apiserver"}[5m]))
# 최종
sum by(resource, code, verb) (rate(apiserver_request_total{resource=~".+"}[5m]))
or
sum by(resource, code, verb) (irate(apiserver_request_total{resource=~".+"}[5m]))
Cilium Performance
cilium 의 퍼포먼스를 이해하려면, cilium 의 내부 구조와 처리 절차들을 이해하고 있어야 합니다.
Cilium 내부 구조
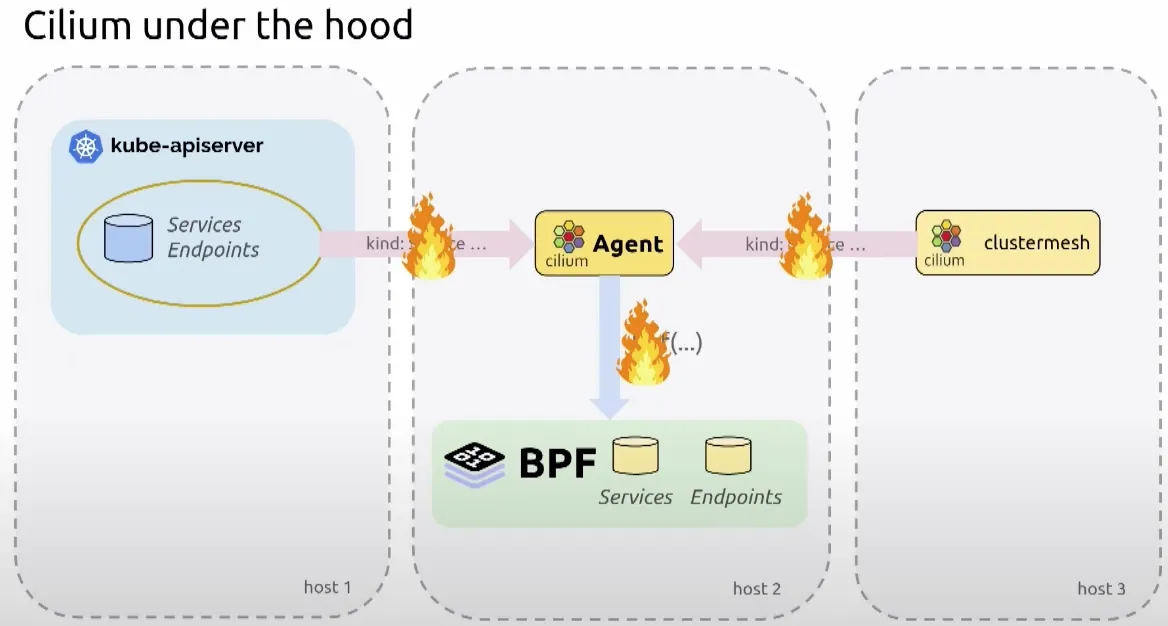
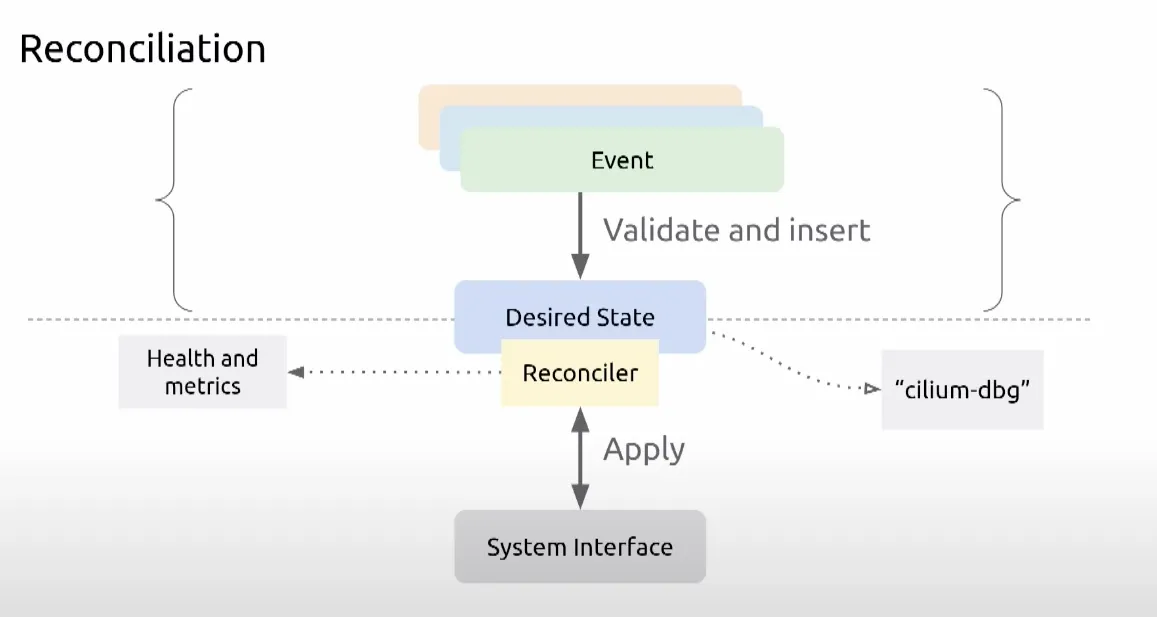
cilium 개발자들은 kube-apiserver 나 clustermesh 에서 이벤트를 받아 ebpf 프로그램으로 처리하는데, 각 구간마다 장애가 발생한다면 어떻게 처리해야 할지 고민이 되었습니다.
이벤트가 적절한지 검증이 필요했고, 장애가 발생할 경우 재시도 로직이 필요했고, 상태를 저장할 필요가 있었습니다.
stateDB 와 효율적인 업데이트를 위한 Reconciler 컴포넌트를 중간에 두어 처리할 수 있게 하였습니다.
그래서 위와 같이 상태를 저장하는 StateDB 와 안정적인 운영을 위한 reconciler 컴포넌트(재시도 로직 및 헬스, 메트릭 체크) 를 도입하게 되었습니다.
cilium 을 설치하기 위해 disableDefaultCNI: true 옵션과 kubeProxyMode: none 옵션을 사용해서 CNI 없이 클러스터 구성을 하고 이후 cilium CNI 플러그인을 설치해서 네트워킹을 활성화합니다. 모니터링을 위한 prometheus 와 grafana 도 설치합니다.
참고로 control-plane 을 3개를 띄우면 HA Proxy 를 구성할 수 있다고 합니다.
# Prometheus Target connection refused bind-address 설정 : kube-controller-manager , kube-scheduler , etcd , kube-proxy
kind create cluster --name myk8s --image kindest/node:v1.33.2 --config - <<EOF
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: control-plane
- role: control-plane
networking:
apiServerAddress: "127.0.0.1"
apiServerPort: 6443
disableDefaultCNI: true
kubeProxyMode: none
EOF
#
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3e0a95aff7a6 kindest/haproxy:v20230606-42a2262b "haproxy -W -db -f /…" 12 minutes ago Up 12 minutes 127.0.0.1:6443->6443/tcp myk8s-external-load-balancer
981cf7c18ac6 kindest/node:v1.33.2 "/usr/local/bin/entr…" 12 minutes ago Up 12 minutes 127.0.0.1:49776->6443/tcp myk8s-control-plane2
40b5b2ebe5bf kindest/node:v1.33.2 "/usr/local/bin/entr…" 12 minutes ago Up 12 minutes 127.0.0.1:49775->6443/tcp myk8s-control-plane
6aa3d5b5b1ab kindest/node:v1.33.2 "/usr/local/bin/entr…" 12 minutes ago Up 12 minutes 127.0.0.1:49777->6443/tcp myk8s-control-plane3
Cilium 테스트
cilium 에서는 네트워크 관련 성능 및 기능 테스트 도구를 제공합니다. cilium connectivity -h 명령어로 테스트 관련 명령어를 확인할 수 있습니다.
cilium connectivity -h
Connectivity troubleshooting
Available Commands:
perf Test network performance
test Validate connectivity in cluster
test 명령어 같은 경우에는 네트워크 정책이 없을 때 outside 로 통신이 되는지 여부, 모든 ingress deny 하고 나서 통신이 되는지 여부 등 통신 pass / fail 의 점검을 할 수 있습니다. perf 명령어는 같은 노드 내부에서 통신 성능 테스트를 하거나, host to pod 경유 흐름에서 통신 성능 테스트를 수행합니다.
ciliumEndpointSlice.enabled=true 옵션으로 CES 를 사용할 수 있으며, kubectl get ciliumendpointslices.cilium.io -A 명령어로 watch 대상을 확인할 수 있습니다. 해당 옵션의 활성화 여부에 따라 차이가 많이 나는 것을 확인할 수 있습니다.
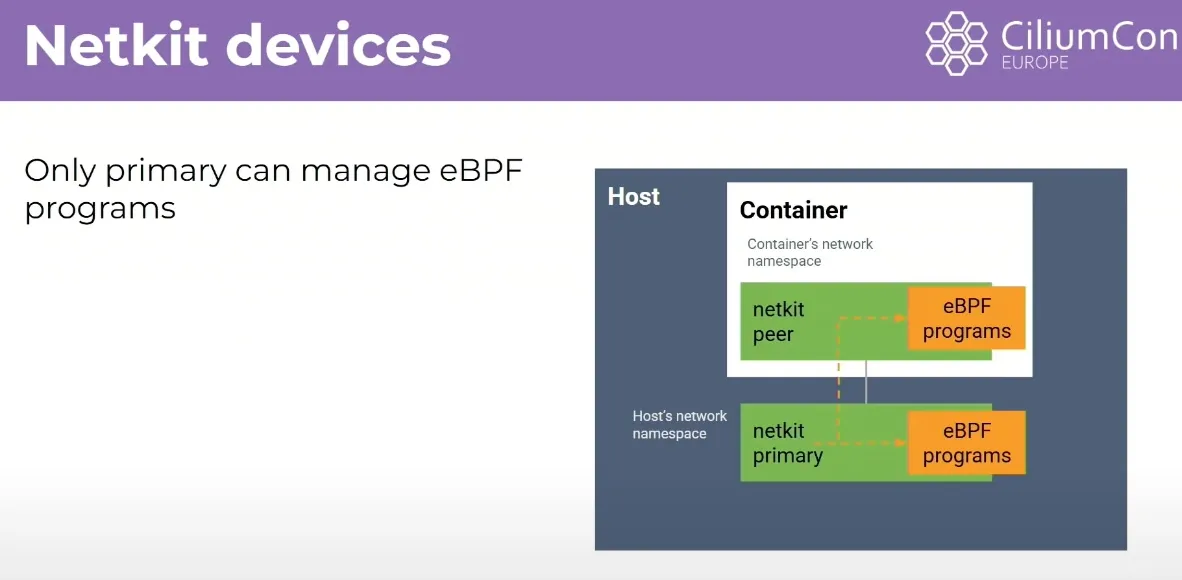
eBPF Host Routing , Netkit
cilium 은 ebpf 를 통해 네트워크 스택을 우회하고 host routing 을 지원하고 있습니다. ingress 의 경우 cpu 의 큐잉을 거치지 않지만, egress 의 경우 어쩔 수 없이 cpu 의 큐잉을 사용하고 있습니다.
netkit 디바이스를 사용하면 veth 가 쌍으로 존재해 egress 의 경우에도 ebpf 로 처리할 수 있어 컨테이너 네트워크의 오버헤드가 사라졌다라고 홍보하고 있습니다. (?)
위 명령어로 netkit 을 사용할 수 있지만 kernel 이 6.7 이상이어야 하고, CONFIG_NETKIT 옵션 활성화가 필요합니다.
cilium 성능 모니터링 메트릭
Cilium 상태 확인
# Cilium 상태 점검
cilium status
# BPF 맵 상태 확인
cilium bpf map list
# 메트릭 엔드포인트 확인
cilium metrics
주요 성능 메트릭
# BPF Map 연산 모니터링
cilium_bpf_map_ops_total
# 데이터패스 패킷 처리
cilium_datapath_packets_total
# 정책 계산 시간
cilium_policy_regeneration_time_stats_seconds
# 엔드포인트 상태 변화
cilium_endpoint_state_count
요약 : 이번 편은 ingress / gateway API 는 일반적인 Kubernetes 의 과정과 유사합니다. cilium 에서 해당 리소스를 ebpf 로 처리해준다는 내용입니다.
Service Mesh (서비스 메시) 란?
분산 애플리케이션 환경은 다양한 마이크로 애플리케이션들이 서로 데이터를 공유하고 클라우드와 온프레미스 경계를 넘나들며 네트워크 통신을 한다. 전통적인 IP 기반 통신을 넘어서 애플리케이션 프로토콜까지 이해해야만 진정한 가시성을 확보할 수 있게 되었다. 서비스 메시는 이러한 환경에서 관측가능성(observability)을 지원하는 인프라스트럭처다. 참고로 네트워크가 메시(mesh) 형태로 구성되어 있어 'mesh' 라고 명명되었다고 한다.
- L7 트래픽 (HTTP, REST, gRPC, WebSocket 등) 을 인식할 수 있어야 한다. - 네트워크 식별자에 의존하지 않고, 신원을 기반으로 하여 서로를 인증할 수 있다. - tracing 이나 metric 형태로 어플리케이션 모니터링(관측 가능성)이 가능해야 한다. - 어플리케이션 코드 변경 없이 사용 가능해야 한다.
cilium 에서는 service mesh 도 자체적으로 지원합니다.
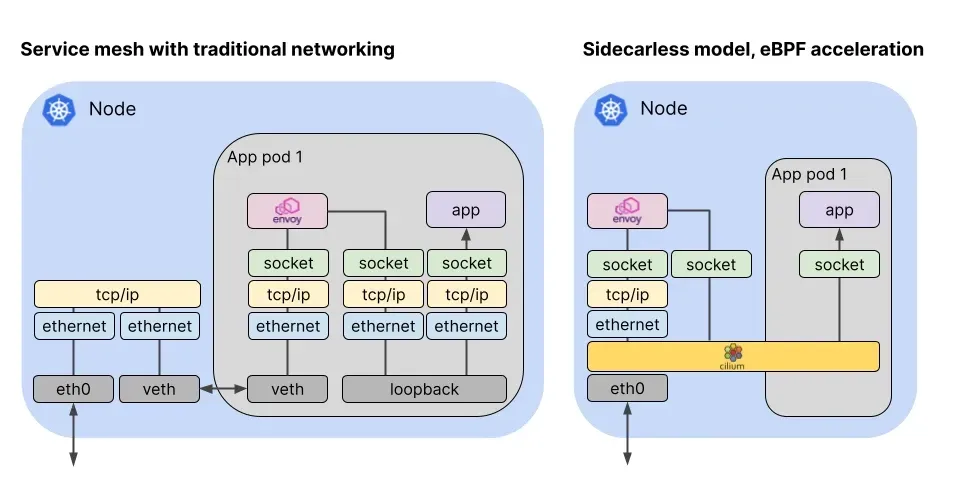
(좌측) 전통적인 서비스 메시의 경우(ambient 모드 X) envoy 사이드카 패턴으로 한 번의 네트워크 스택을 거쳐야 했습니다.
그림을 자세히 보면 envoy 로 트래픽을 가로채서 다시 application 으로 트래픽을 보낸다. 하지만 (우측) cilium 은 ambient 모드와 유사하게 노드마다 공통의 cilium envoy 를 두고 트래픽을 처리합니다. L3/L4 트래픽의 경우, cilium 의 eBPF 로 직접 처리하지만 L7 트래픽은 공통의 envoy 가 처리 후 socket 레벨 단으로 바로 전송합니다.
더 자세하게 실제로 구현한 내용을 보면,
보통 트래픽을 가로채기할 경우 iptables 의 REDIRECT 방법을 이용하긴 하지만, 패킷을 직접 수정하여 목적지 IP 주소가 변경되는 이슈가 존재합니다. 원래 목적지 주소를 유지한 채 패킷을 transparent 하게 전달하려면(NAT 처리하지 않고) TPROXY 를 사용합니다. cilium 은 트래픽이 도착하면 ebpf 코드가 먼저 처리하고 TPROXY 커널 기능을 사용하여 Envoy 로 투명하게 전달합니다.
kubernetes ingress support, gateway api support, GAMMA support 세 가지 방법을 지원하고 있습니다.
Kubernetes Ingress Support
Cilium Ingress 는 Kubernetes Ingress 의 기능을 서포트하며 dedicated 모드와 shared 모드를 제공합니다. 모드를 변경할 수 있으나, 새로운 로드밸런서의 ip 를 부여받기 때문에 ingress backend 와 활성화 되어 있는 연결이 종료될 수 있습니다.
모드
설명
dedicated
각 Ingress 리소스마다 별도의 LoadBalancer 를 생성
shared
클러스터 내 모든 Ingress 리소스가 하나의 LoadBalancer 를 공유
ingress 모드를 사용하려면 nodePort.enabled=true 옵션을 통해 nodePort 를 활성화하고, kubeProxyReplacement=true 옵션을 통해 kube-proxy 를 교체하여 활성화해야 합니다. 만약 L7 Proxy 를 사용하고자 한다면 l7Proxy=true 옵션을 활성화해야 합니다. (default 옵션)
참고로 cilium network policy 가 적용될 때는 ingress 서비스에 들어오기 전과 후 두 번 평가를 하게 됩니다.
설치
# helm 으로 설치 시 아래 옵션 활성화
--set ingressController.enabled=true
--set ingressController.loadbalancerMode=shared
# deploy, daemonset 활성화
$ kubectl -n kube-system rollout restart deployment/cilium-operator
$ kubectl -n kube-system rollout restart ds/cilium
설치 확인은 cilium config view 로 간단히 확인할 수 있습니다.
cilium config view | grep -E '^loadbalancer|l7'
실습
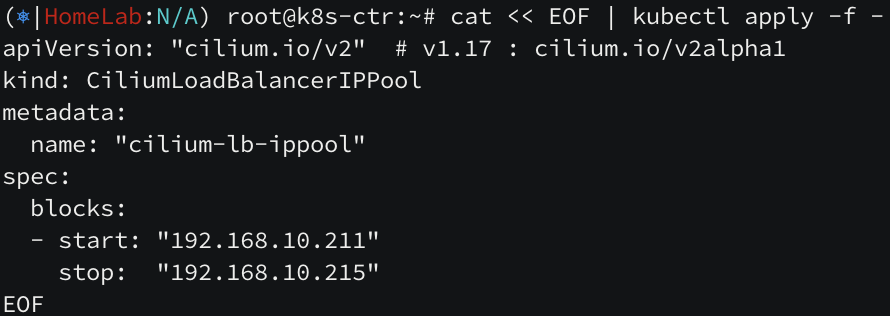
간단하게, external IP 를 발급 받고 외부에서 접근 가능하도록 L2 Announcement 를 사용하겠습니다.
"/" 경로로 올 경우 productpage 서비스로, "/details" 경로로 올 경우 details 서비스로 가도록 ingress 설정하였습니다.
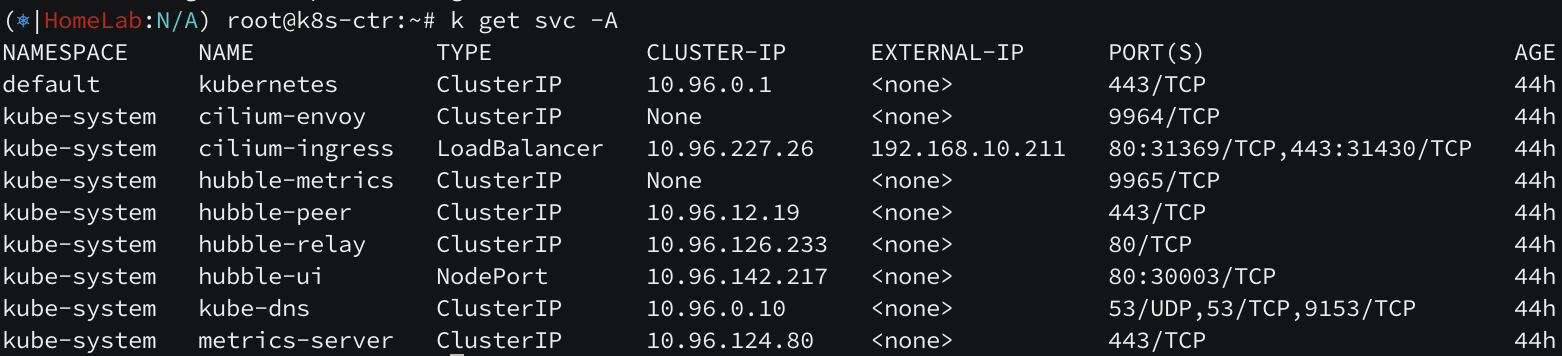
참고로, 생성된 ingress 를 확인해보면 ingress support 를 shared 모드로 설정해두었기 때문에 external-ip 가 ingress ip 와 같다는 것을 볼 수 있습니다.
해당 경로들로 통신을 해보겠습니다. 먼저 내부에서 접근해보겠습니다.
LBIP=$(kubectl get svc -n kube-system cilium-ingress -o jsonpath='{.status.loadBalancer.ingress[0].ip}')
echo $LBIP
# / 로 통신 -> 성공
curl -so /dev/null -w "%{http_code}\n" http://$LBIP/
# /details 로 통신 -> 성공
curl -so /dev/null -w "%{http_code}\n" http://$LBIP/details/1
# /ratings 로 통신 -> 실패
curl -so /dev/null -w "%{http_code}\n" http://$LBIP/ratings
정상적으로 ingress 정책에 따라 통신이 되고 있습니다. -v 옵션을 주어서 자세히 보면 envoy 서버를 경유해서 x-envoy-upstream-service-time 이라는 특정 헤더가 세팅되는 것을 확인할 수 있습니다. (외부에서 접근하면 x-forwarded-for 헤더로 source-ip 를 기재하게 됩니다.)
현재 전역적으로 로드밸런서 모드를 shared 모드로 사용하고 있어, ingress.cilium.io/loadbalancer-mode: dedicated 애너테이션을 통해 dedicated 모드로 로드밸런서를 생성합니다.
cilium 클래스로 igress ip 가 하나 더 생긴 것을 볼 수 있습니다. 위에서 마찬가지로 접속하는 클라이언트의 ip 를 x-forwarded-for 헤더에 담아서 통신하게 됩니다.
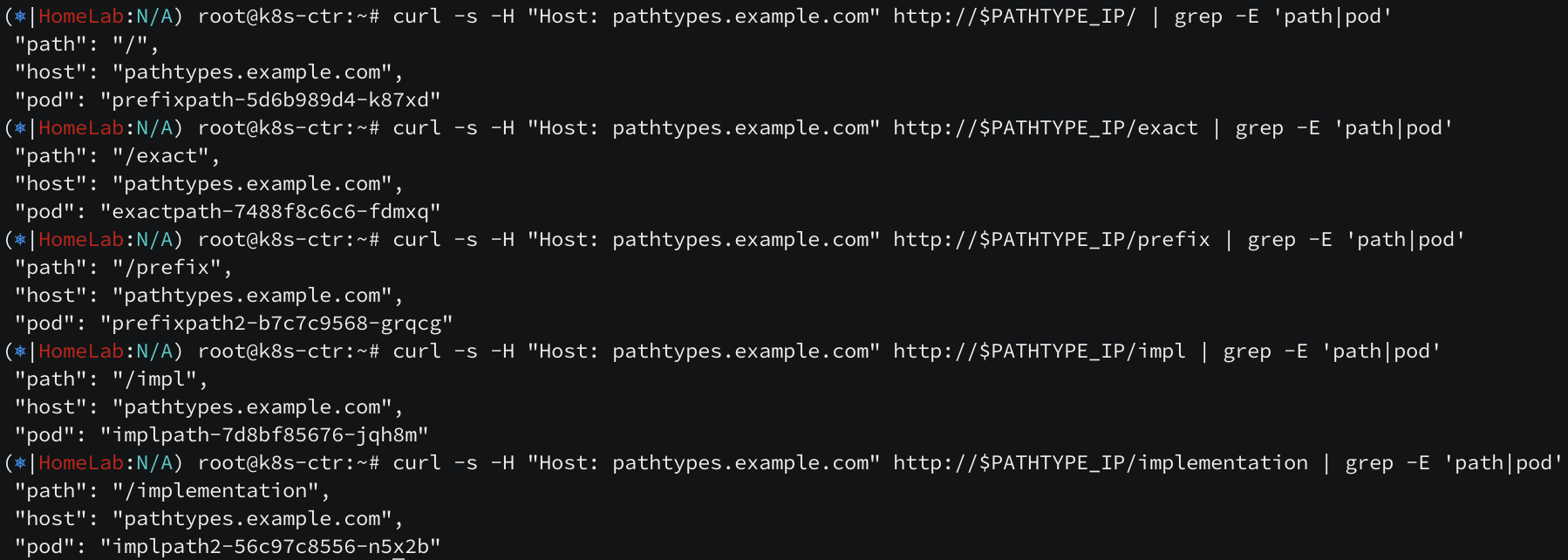
ingress path type
cilium ingress path type 은 Exact, Prefix, ImplementationSpecific 세 가지를 지원합니다.
Exact 는 정확히 일치할 경우, Prefix 는 접두사처럼 앞에만 일치하는 경우, ImplementationSpecific 는 IngressClass에 따라 달라집니다. 별도 pathType 으로 처리하거나, Prefix 또는 Exact 경로 유형과 같이 동일하게 처리할 수 있습니다.
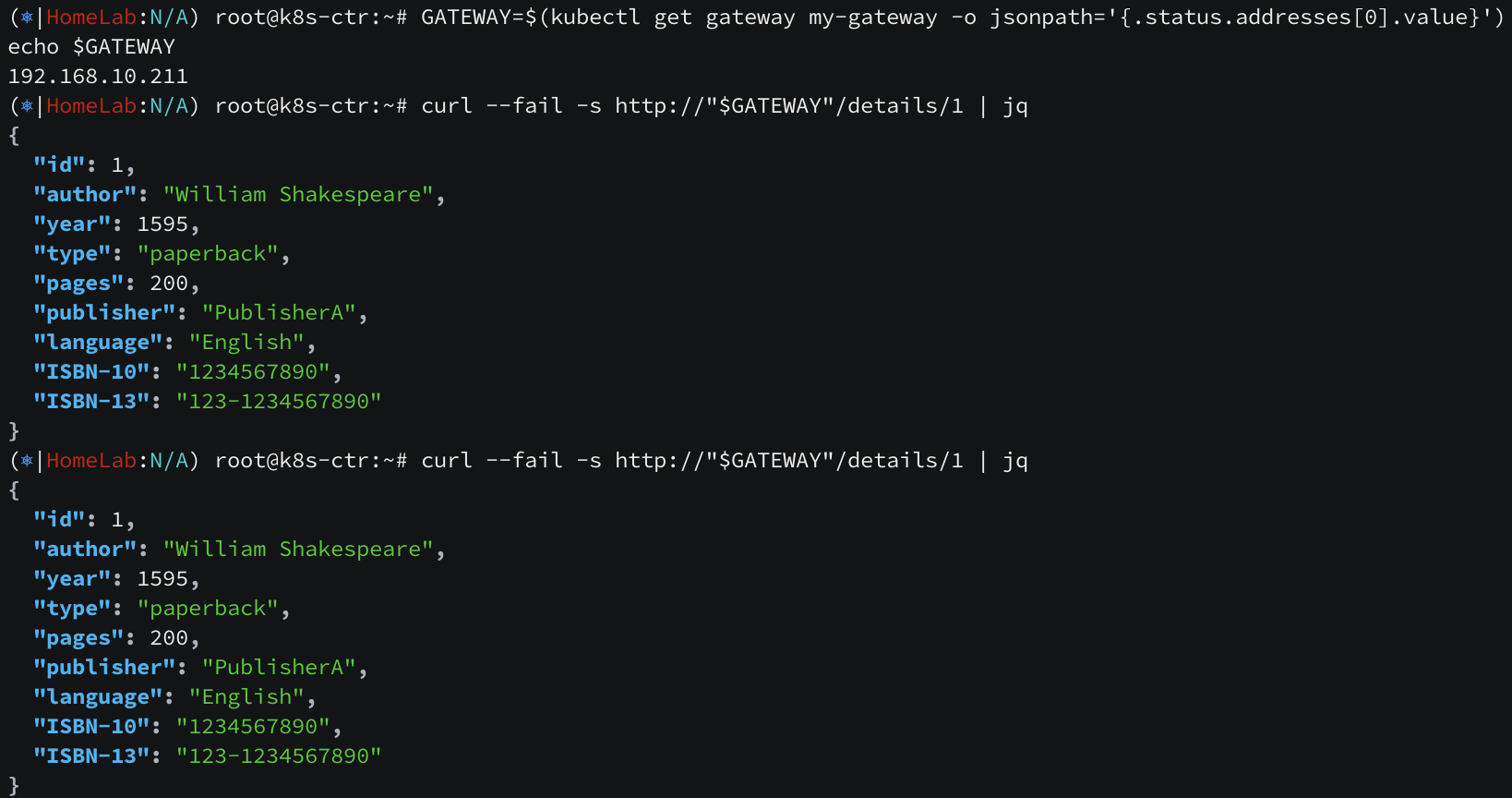
같은 네임스페이스로 들어오는 80 트래픽에 대해서, /details URL 은 details 서비스 9080 포트로, /?great=example&magic=foo URL 은 productpage 서비스 9080 포트로 가는 Gateway API 를 설정합니다.
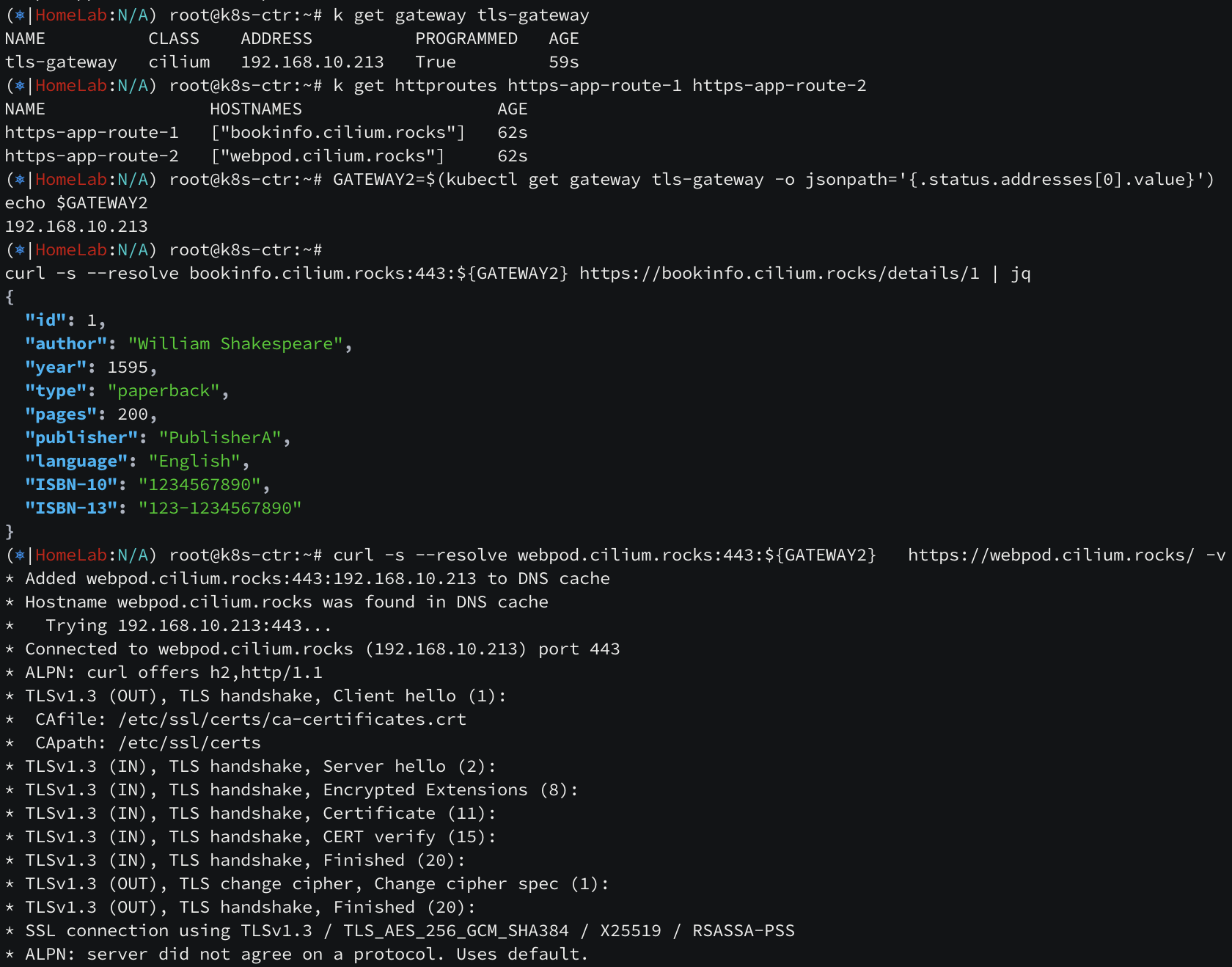
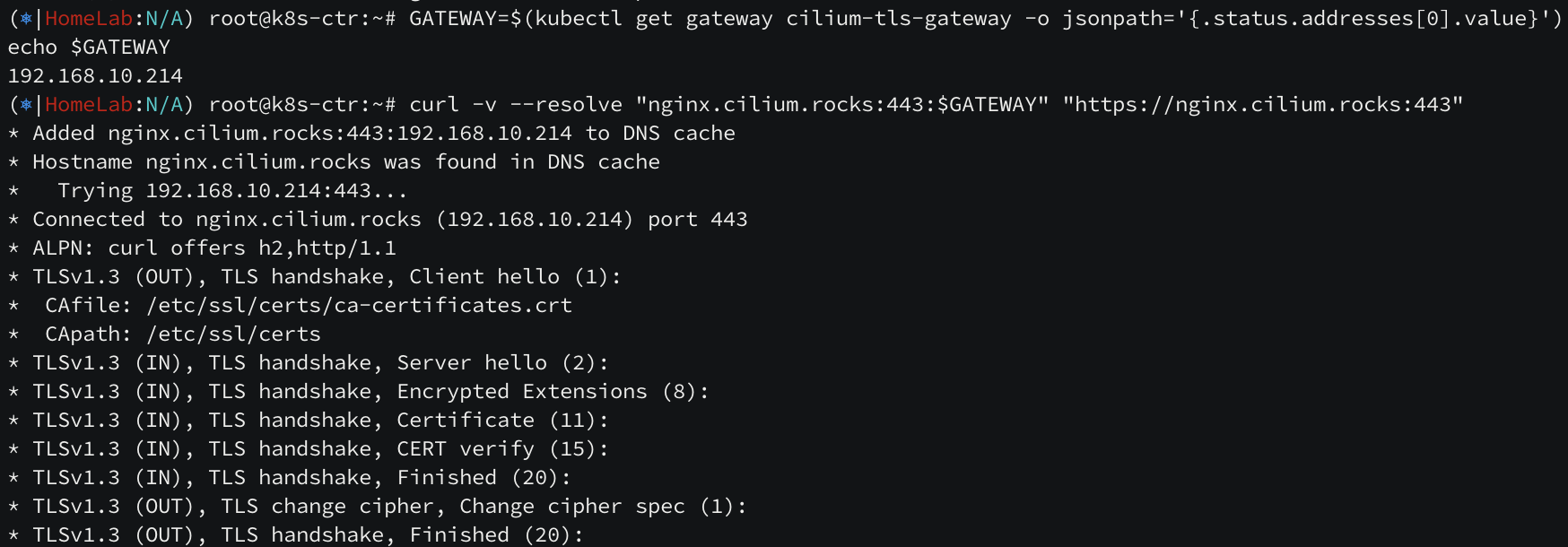
조건에 부합하도록 페이로드를 작성해보니 정상 통신되고 있습니다. https 도 테스트해보겠습니다.
1. 로컬 CA(자체 루트 인증기관) 생성
내 로컬에서 만든 인증서를 시스템이 신뢰하도록 설정해주고, 로컬 CA 를 생성한 다음 시스템에 등록하겠습니다.
## mkcert 설치
apt install -y mkcert
## *.cilium.rocks 도메인에 대한 CA 생성
mkcert '*.cilium.rocks'
## 로컬 인증서 신뢰
mkcert -install
## CA 저장 위치 확인
# CA 파일은 $(mkcert -CAROOT)가 가리키는 사용자 데이터 디렉터리에 저장되고 (예: rootCA.pem, rootCA-key.pem) "mkcert -CAROOT" 명령어로 확인합니다.
mkcert -CAROOT
Cluster 객체를 통해 control-plane 노드와 worker 노드를 생성합니다. 아래 클러스터 주소 지정 요구사항을 참고하여 노드를 생성 시, podCIDR 대역과 serviceSubnet 이 겹치지 않도록 설정해야 합니다.
클러스터 주소 지정 요구 사항 - 모든 클러스터는 동일한 데이터 경로 모드를 설정해야 합니다. (캡슐화 또는 네이티브 라우팅 모드) - 모든 클러스터의 PodCIDR 범위는 충돌하지 않고 고유한 IP 주소여야 합니다. - 모든 클러스터의 노드는 각 노드에 구성된 InternalIP를 사용하여 서로 IP 연결을 유지해야 합니다. - 클러스터 간 네트워크는 클러스터 간 통신을 허용해야 합니다.
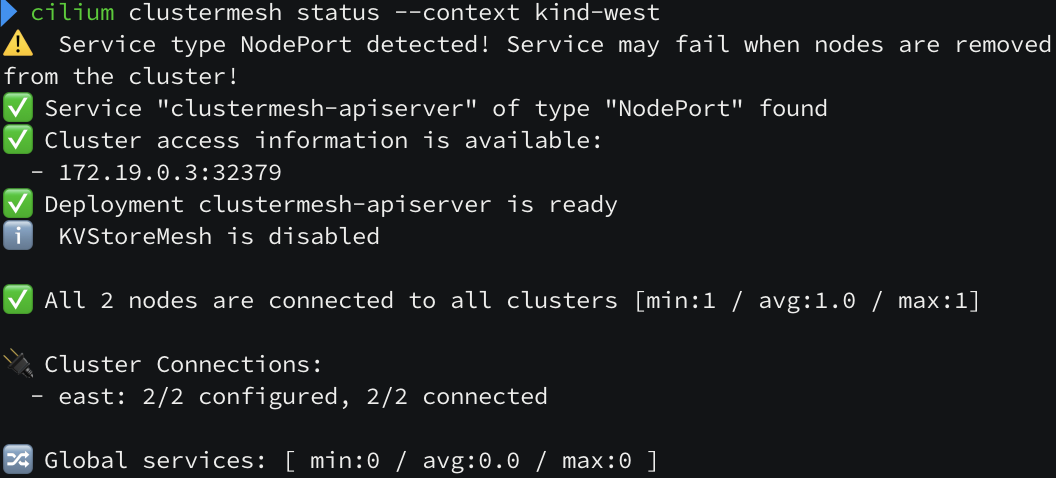
cluster mesh 로 각각의 클러스터들을 묶기 위해서 cluster.name 옵션곽 cluster.id 값을 유니크하게 지정해주어야 합니다.
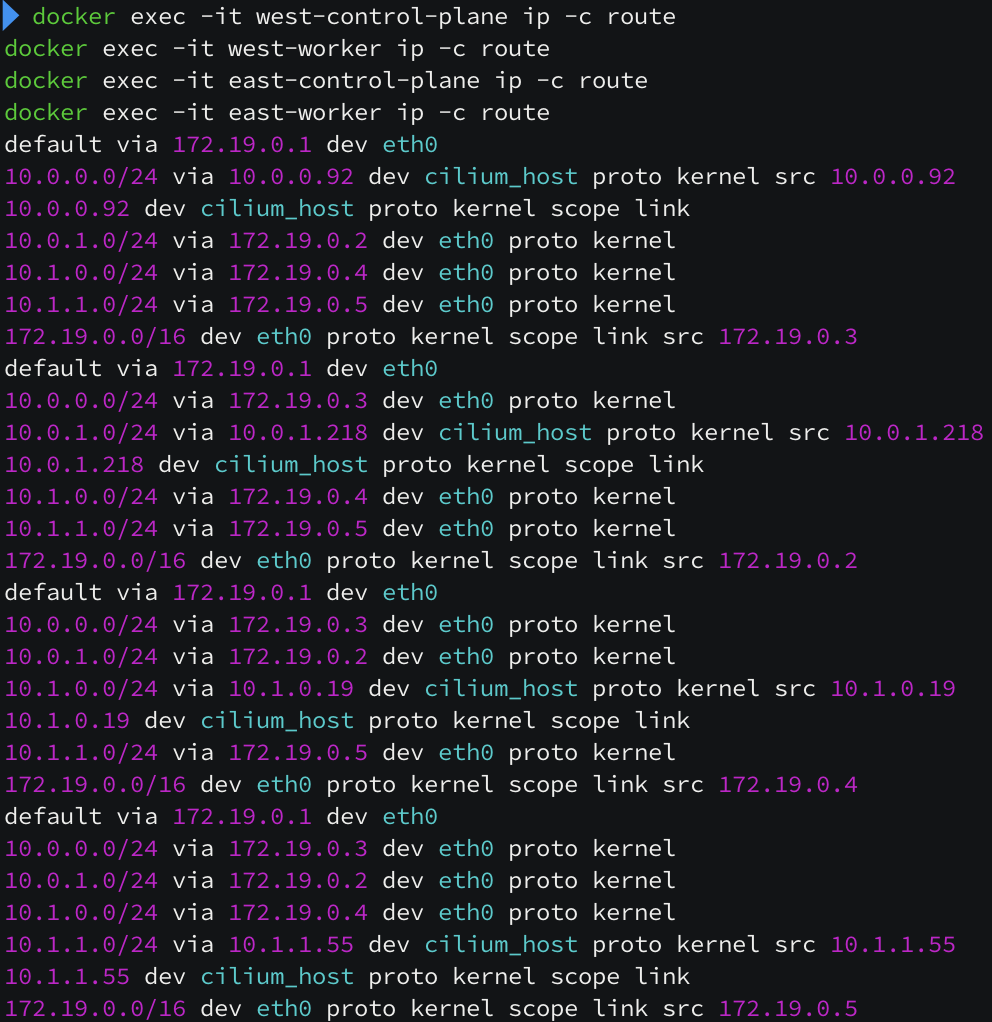
네트워크 설정 시, 보통은 podCIDR 대역을 노드의 라우팅 테이블에 넣어주어야 하는데 native routing 모드이고 cluster mesh 를 구성할 때 자동으로 라우팅을 주입해줍니다. 노드 OS 라우팅 테이블에 라우팅이 되어 있지 않은데도 통신이 정상적으로 됩니다.
하지만 하나 체크할 것이 있습니다. cilium 에서 내부 통신할 때, 인증서 기반으로 통신을 하는데 지금 개별 설치를 진행했기 때문에 한 쪽에 있는 인증서 정보로 맞춰주는 작업이 필요합니다.
# east 에 있는 ca 정보를 삭제하고,
keast delete secret -n kube-system cilium-ca
# west 에 있는 ca 정보를 복사해서 east ca 에 복사합니다.
kubectl --context kind-west get secret -n kube-system cilium-ca -o yaml | \
kubectl --context kind-east create -f -
cluster mesh 구성
일단 cluster mesh 로 서로 간의 정보를 주고 받는 컨트롤 플레인의 역할을 설정해주어야 합니다. 여기서는 간단한 실습 환경을 구성하기 위해 서비스 타입을 NodePort 로 진행합니다.
특징:nodeSelector 를 통해 특정 노드들을 선택하여 광고 가능 (일관된 BGP 설정 관리)
CiliumBGPPeerConfig
역할: CiliumBGPClusterConfig 에 등록된 클러스터 내 bgp 인스턴스의 BGP 피어링 설정
특징: neighbor 설정과 peering 상세 설정을 분리하여 여러 피어에서 동일한 설정 공유 가능
CiliumBGPAdvertisement
역할: BGP 라우팅 테이블에 주입할 광고 유형 정의 (Pod CIDR, Service IP 등 다양한 타입 지원)
65000 AS 인 192.168.1.200 라우터와 neighboor 설정하고 ipv4의 podCIDR 대역을 홍보하는 설정입니다.
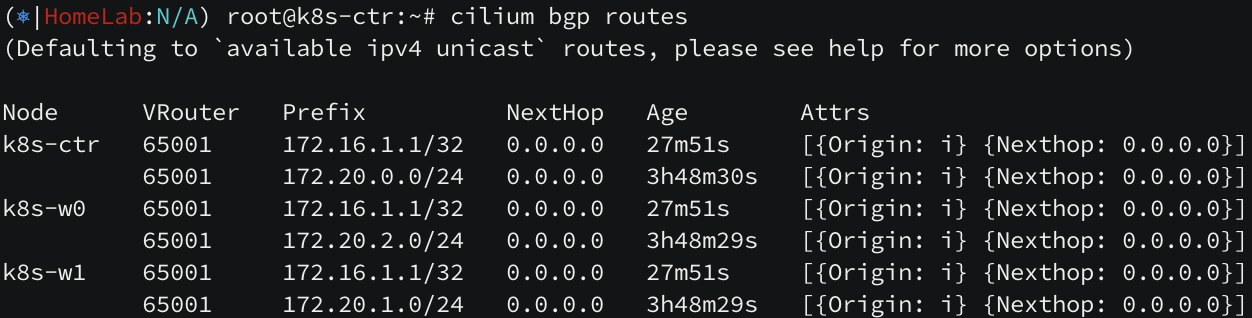
모든 설정이 완료되면, k8s control plane 노드에서 bgp peers 설정을 확인할 수 있습니다.
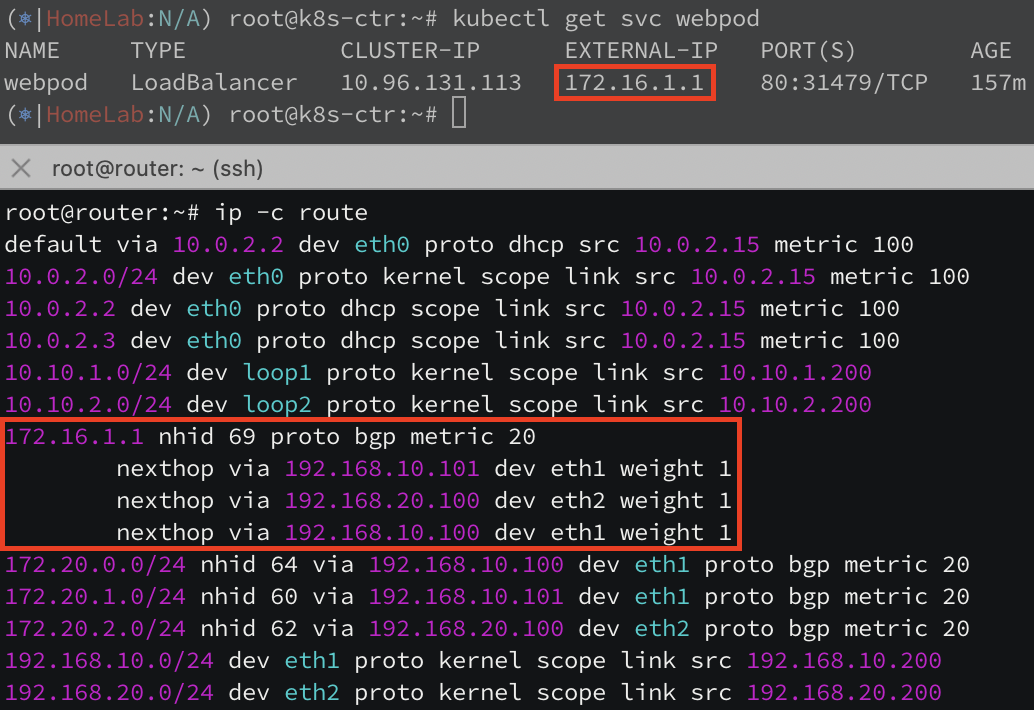
라우터 노드에서도 k8s 의 podCIDR 대역이 라우팅 된 것을 확인할 수 있습니다.
하지만 아직도 다른 네트워크 간 통신이 되지 않고 있습니다. BGP 프로토콜로 인해 다른 neighbor 에 있는 podCIDR 대역을 받아왔지만,
커널 라우팅 테이블에는 자동으로 올라가지 않았습니다. 여전히 라우팅 테이블에 podCIDR 대역이 보이지 않네요.
Cilium의 BGP는 GoBGP 기반으로 구성되어 있는데 기본적으로 disable-telemetry, disable-fib 상태로 빌드가 되기 때문에, 수신한 경로를 Linux 커널(FIB) 에 바로 주입하지 않는 것으로 추정됩니다. 여러 개의 podCIDR 대역들을 네트워크 장비에 전달하면 그 장비가 직접 라우팅을 진행하면 되기 때문에 Cilium 입장에서는 받을 필요가 없을 수도 있을 것 같습니다.
실무 환경에서는 default gateway 가 존재할 것이기 때문에 통신은 무난히 진행될 것으로 생각됩니다. 다만, 실습 환경에서는 k8s 대역을 eth1 인터페이스로, 인터넷을 eth0 인터페이스로 사용하고 있기 때문에 podCIDR 대역을 eth1 통해서 라우팅 될 수 있도록 조정이 필요합니다.
# k8s 파드 사용 대역 통신 전체는 eth1을 통해서 라우팅 설정
ip route add 172.20.0.0/16 via 192.168.10.200
sshpass -p 'vagrant' ssh vagrant@k8s-w1 sudo ip route add 172.20.0.0/16 via 192.168.10.200
sshpass -p 'vagrant' ssh vagrant@k8s-w0 sudo ip route add 172.20.0.0/16 via 192.168.20.200
이제 정상적으로 통신이 되고 있습니다.
Service IP BGP 설정
지금까지 알아본 BGP 설정은 podCIDR 대역을 홍보한 설정이지만, 저번 시간에 알아본 Service IP (External IP) 는 어떻게 설정해야 할까요?
위에서 BGP peering 설정은 완료했으니 "metadata.labels.advertise: bgp" 라벨만 고정으로 해서 Service 유형의 CiliumBGPAdvertisement 를 통해 서비스 IP 를 광고해주면 됩니다.
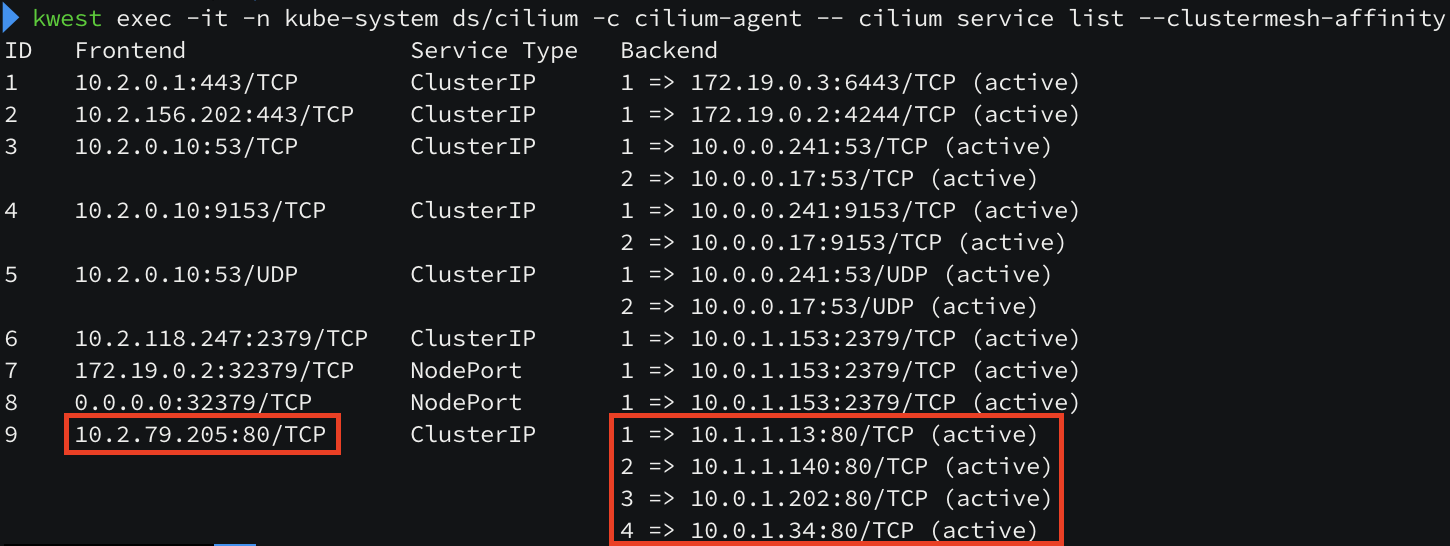
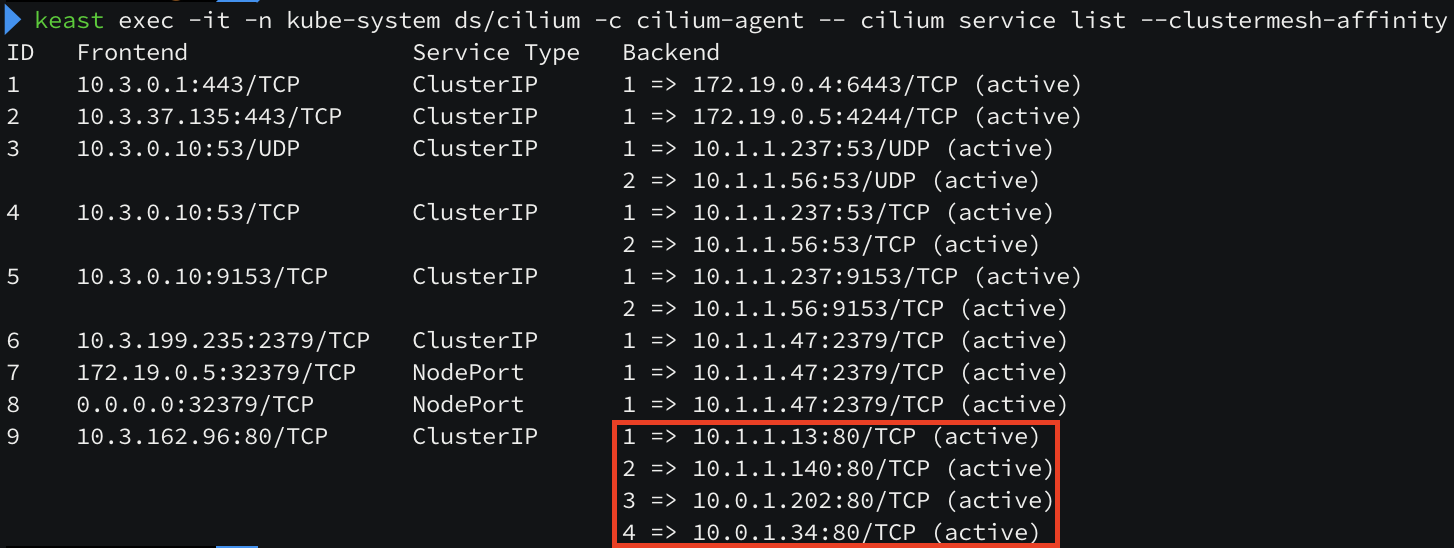
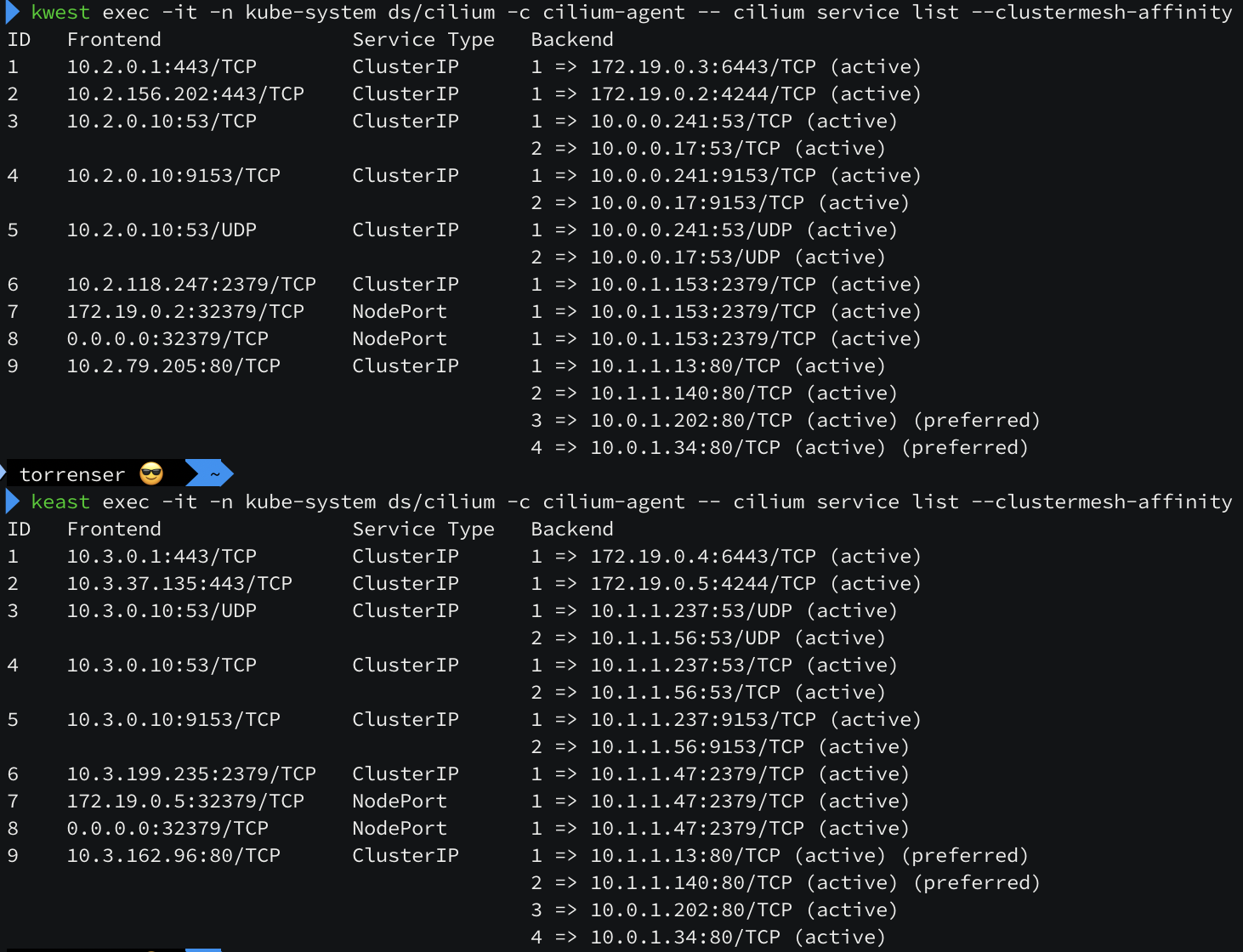
정상적으로 router 노드에 Service IP 가 라우팅 되는 것을 확인할 수 있습니다. 로드밸런싱도 정상적으로 수행이 될까요?
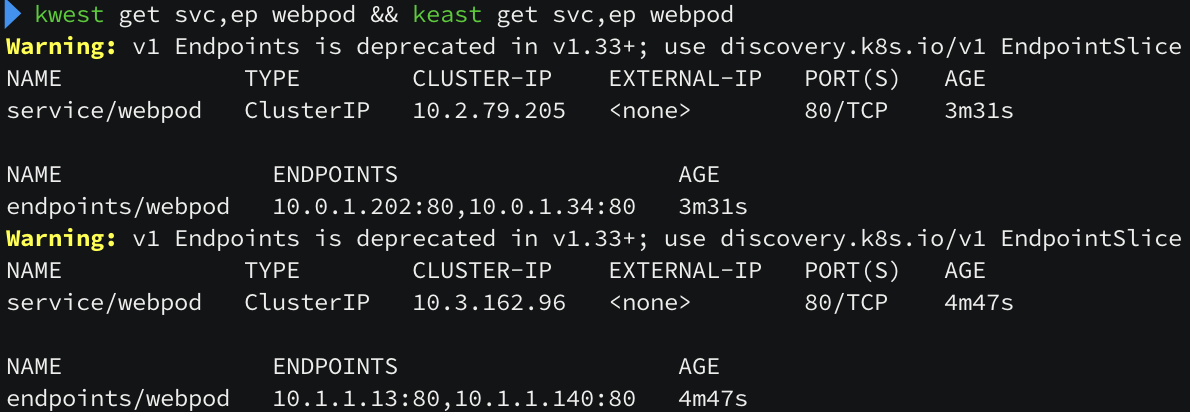
router 노드에서 서비스로 통신 시도 시 트래픽이 골고루 분산되는 것처럼 보입니다. 현재 3개의 replica 구성을 2개의 replica 구성으로 변경해보았습니다.
2개의 replica 로 줄어들면서 k8s-ctr 노드와 k8s-w0 노드에만 webpod 가 세팅이 되어 있지만, bgp 라우팅에는 3개의 노드가 아직 구성되어 있습니다. 이유는 Service 의 externalTrafficPolicy 속성이 cluster(default) 이기 때문입니다. cluster 타입을 local 로 변경하면 pod 를 가지고 있는 노드만 광고하게 됩니다. (아래 정보에서 2번 방식에서 1번 방식으로 변경된 것입니다.)
1. Router 에서 BGP ECMP MultiPath 로 인해 Cilium BGP Peer 중 하나의 노드로 전달 2. 해당 트래픽의 원래 목적지인 k8s-ctr 의 파드로 요청을 전달 3. 해당 노드의 파드가 요청을 처리하고 응답 리턴을 위해서, NAT 를 수행했던 노드(k8s-w1) 로 다시 전달 4. NAT 를 수행했던 연결 정보를 확인해서, Reverse NAT 를 수행해서 최종 응답을 리턴
1. Router 에서 BGP ECMP MultiPath 로 인해 Cilium BGP Peer 중 하나의 노드로 전달 2. 해당 트래픽의 원래 목적지인 k8s-ctr 의 파드로 요청을 전달
이 때, Router 로 바로 리턴하기 위해서(DSR) 최초 접속했던 클라이언트의 정보를 GENEVE 헤더에 감싸 전달
(클라이언트의 세션에 대한 유지를 위해서 Maglev 알고리즘을 사용)
3. 해당 노드의 파드가 요청을 처리하고 GEVEVE 헤더 정보를 활용하여 Reverse NAT 을 수행해서 응답을 바로 리턴
kubectl patch service webpod -p '{"spec":{"externalTrafficPolicy":"Local"}}'
pod 가 있는 노드만 라우팅 설정된 것을 볼 수 있습니다. 하지만, 아직도 부하 분산이 되지 않고 있습니다. 한 쪽에 있는 pod 에만 트래픽이 몰리고 있는데요. 이는 리눅스에서 네트워크 분산을 책임지는 ECMP Hash 정책이 기본적으로 L3(목적지 IP 기반) 해시를 사용하기 때문입니다.
Kubernetes 의 NodePort 서비스는 각 서비스마다 고유한 IP 를 가질 수 있지만, 클라이언트가 어느 호스트로 트래픽을 보낼지 결정해야 하는 단점이 있습니다. 또한 노드가 다운되면 IP + Port 조합 사용이 불가합니다. LoadBalncer 서비스 타입은 이러한 단점을 해결하고자 외부에서 IP 를 할당해주고, 어떤 IP 로 트래픽을 보내야 할지 알려줍니다. 클라이언트는 LoadBalancer 서비스 타입의 IP 만 알고 있으면 됩니다. 아래와 같이 Kubernetes에서 LoadBalancer 타입 서비스를 만들면,
클라우드에서는 AWS, GCP, Azure 같은 클라우드 제공업체가 자동으로 로드밸런서를 만들어주고 IP를 할당해주지만, 온프레미스 환경에서는 아무도 IP 를 할당해주지 않아서 아래처럼 계속 <pending> 상태로 남아있게 됩니다.
NAME TYPE EXTERNAL-IP PORT(S)
my-app LoadBalancer <pending> 80:30080/TCP
Cilium 에서는 이러한 역할을 LoadBalancer IPAM 이 담당합니다. LoadBalancer 서비스 유형에서 IP 를 할당하고, 로드밸런싱 역할을 수행합니다. 하지만 IP 를 각 노드에 할당을 해준다고 해서 통신이 가능할까요? 자신의 주소는 받았지만, 경로는 설정되지 않아서 도달할 수 없습니다. 누군가(라우터 or 스위치)가 경로를 안내해주어야 하지만, 자신이 어디있다고 말하지 않으면 네트워크 관리자가 매번 라우터 or 스위치에 수동적으로 경로 테이블을 변경해야 할 것입니다. 따라서 어떻게 자신의 주소를 홍보할 것인지 방법이 필요합니다.
같은 네트워크 대역이라면 ARP 프로토콜을 통해 자신의 주소를 알려줄 수 있고, 다른 네트워크 대역이라면 BGP 프로토콜을 통해 자신의 주소를 홍보할 수 있습니다. cilium 에서 어떻게 설정할 수 있는지 아래에서 살펴보겠습니다.
Cilium LoadBalncer IPAM (서비스의 IP 분배 방법)
Cilium 에서 LoadBalancer IPAM 은 IP 를 Pool 형태로 관리하고, 필요 시 Pool 에서 할당하고 해제 시 Pool 에 반납합니다.
cidrs 문법 형태로 서브넷 마스크를 활용하여 CIDR 대역을 지정할 수도 있습니다. 혼용하여 사용도 가능합니다.
보통 blocks 문법은 불연속적인 IP 범위를 각각 지정하여 정확한 IP 를 분배할 때 사용하며, CIDR 문법은 CIDR 대역으로 유연하게 관리할 때 사용합니다.
위와 같은 환경에서 아래와 같이 ip pool 을 생성 후, LoadBalancer 타입의 서비스를 생성해보면,
ippool 중 하나의 ip 가 할당되는 것을 볼 수 있습니다.
내부 클러스터끼리도 정상 통신하고 있습니다.
하지만 k8s 클러스터 외부인 라우터에서 접속하면 아래와 같이 통신이 되지 않는 것을 볼 수 있습니다.
앞서 살펴보았듯이, 다른 네트워크 대역과 통신하려면 서비스의 IP 를 홍보해야 합니다.
Cilium 의 IP 홍보방법
cilium 의 LoadBalancer IPAM 에서 Cilium BGP Control Plane 사용하여 BGP 프로토콜을 통해 IP 를 홍보하고, L2 Announcements/L2 Aware LB(베타)를 통해 로컬에 자신의 주소를 홍보합니다.
Cilium L2 Announcement
로컬 영역 네트워크(LAN) 에서 External IP 나 LoadBalancer 유형의 IP 요청이 왔을 때 자신의 ARP 주소를 응답 쿼리로 보냄으로써 통신이 수행됩니다. 가장 빠르게 ARP 요청을 보낸 노드가 리더 노드가 되어 라우팅 역할을 수행하게 됩니다. 나머지 노드는 백업 상태로 유지되다가 리더 노드가 죽으면 다시 빠르게 ARP 요청을 보낸 노드를 리더로 선출합니다. 이처럼 항상 리더 노드를 거쳐 트래픽이 이동해야 된다는 단점이 있다는 것을 알 수 있습니다.
webpod 서비스를 노출하는 externalIP 와 loadbalncerIP 유형들에 대해 k8s-w0 을 제외한 노드가 ARP 응답을 보낼 수 있도록 정책을 구성하였습니다. 앞서 본 테스트 환경에서 k8s-w0 노드는 k8s 클러스터 내에 있지 않고 같은 네트워크 영역에 있지 않으므로 ARP 를 광고할 수 있는 노드에서 배제해야 합니다.
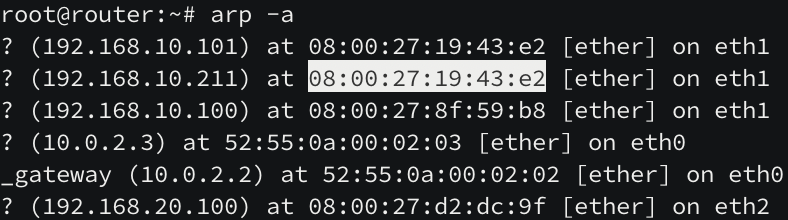
정책을 적용하고 나서 현재 상태를 확인해보니 k8s-w1 노드가 리더로 선출된 것을 확인할 수 있습니다.
cilium-dbg shell -- db/show l2-announce 명령어를 통해서도 현재 서비스 IP 가 어떤 노드에게 할당되어 있는지 확인 가능합니다.
아까와 다르게 router 노드와 k8s-cluster 간 통신이 정상적으로 수행되는 것을 볼 수 있습니다.
router 노드의 ARP 테이블도 확인해보면 서비스(192.168.10.211)의 ARP 가 현재 리더 노드(192.168.10.101)의 ARP 와 같습니다.
리더 노드가 모든 트래픽을 받아 원래 도착지 주소로 보냄으로써 통신한게 됩니다.
Cilium LoadBalncer IPAM 추가 기능
cilium <-> router 간 노드가 정상적으로 통신된 상태에서 cilium LoadBalancer IPAM 의 추가 기능을 살펴보겠습니다.
추가 기능을 살펴보기 앞서 netshoot 을 개량하여 만든 웹 서비스를 하나 더 띄워 보겠습니다.
autoDirectNodeRoutes 옵션은 같은 네트워크 대역 노드 간에 pod CIDR 대역을 static routing 방식으로 자동으로 추가해주는 옵션입니다. 다른 네트워크 대역의 경우, 중간에 네트워크 장비가 pod CIDR 대역을 라우팅 안 해주면 의미가 없기 때문에 라우팅 추가를 하지 않습니다.
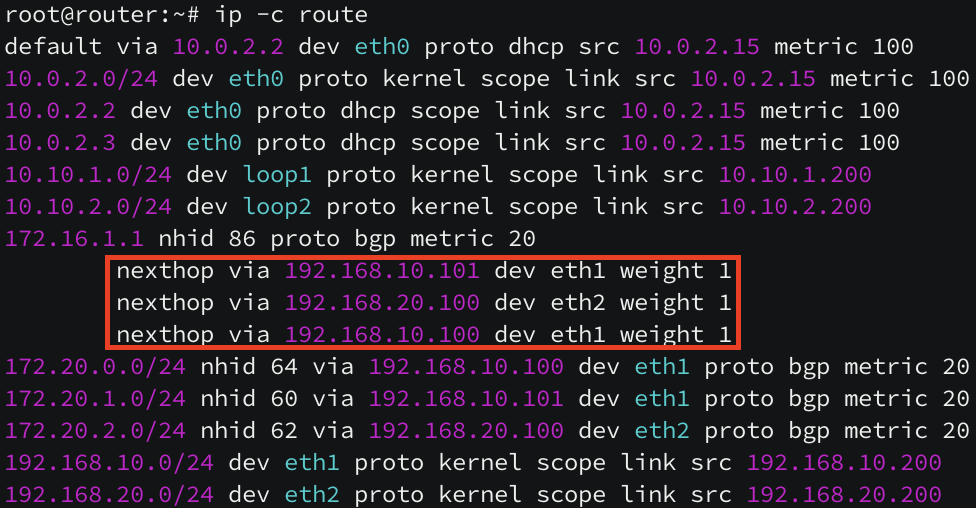
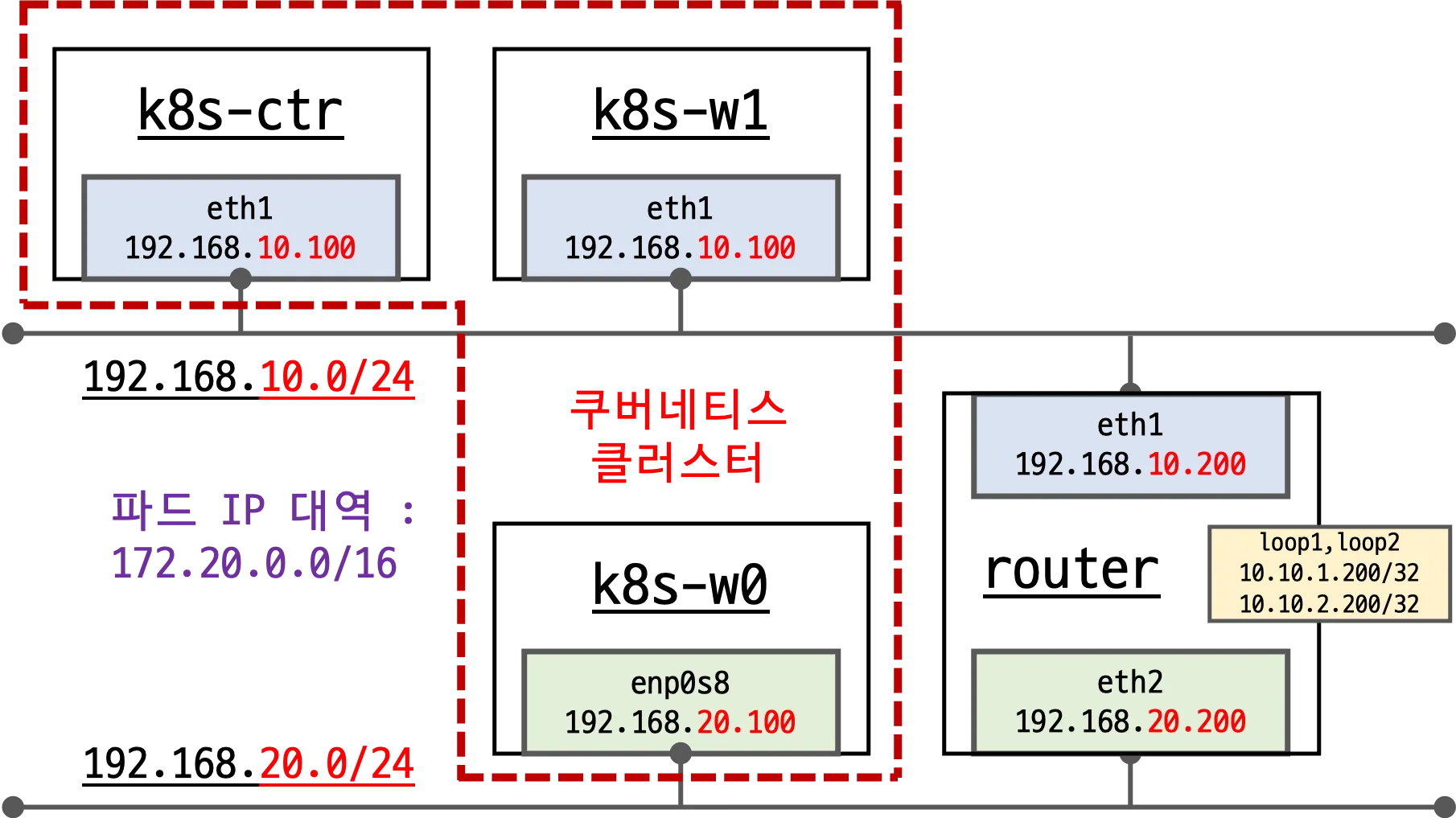
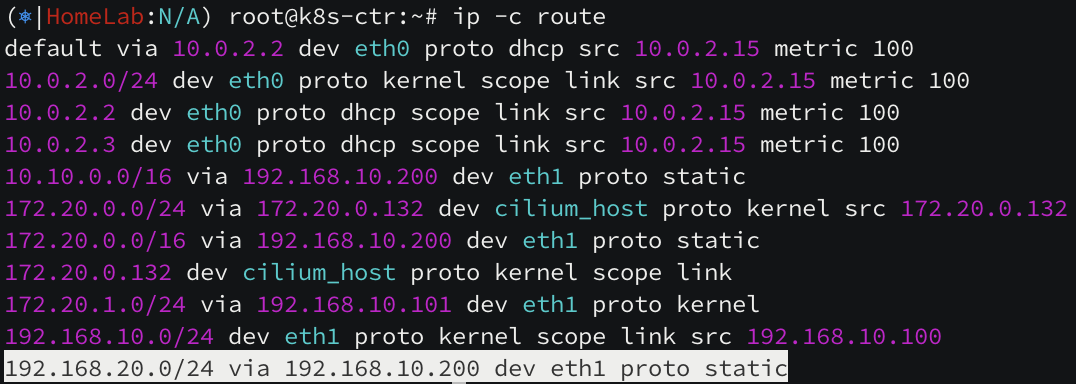
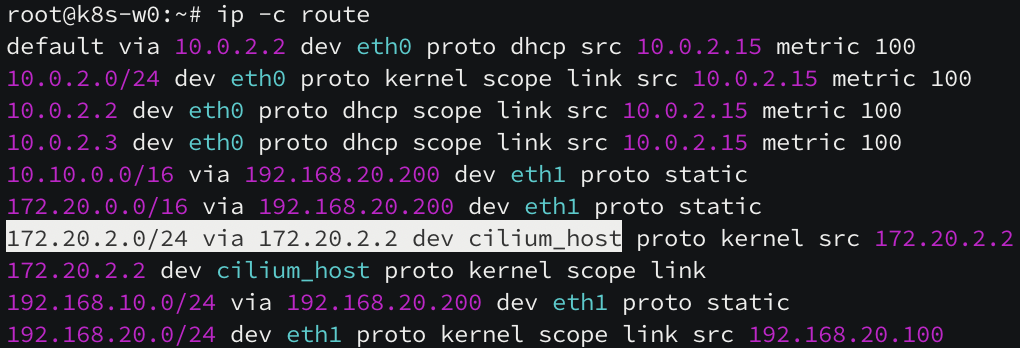
[ k8s-ctr 노드의 라우팅 테이블 ]
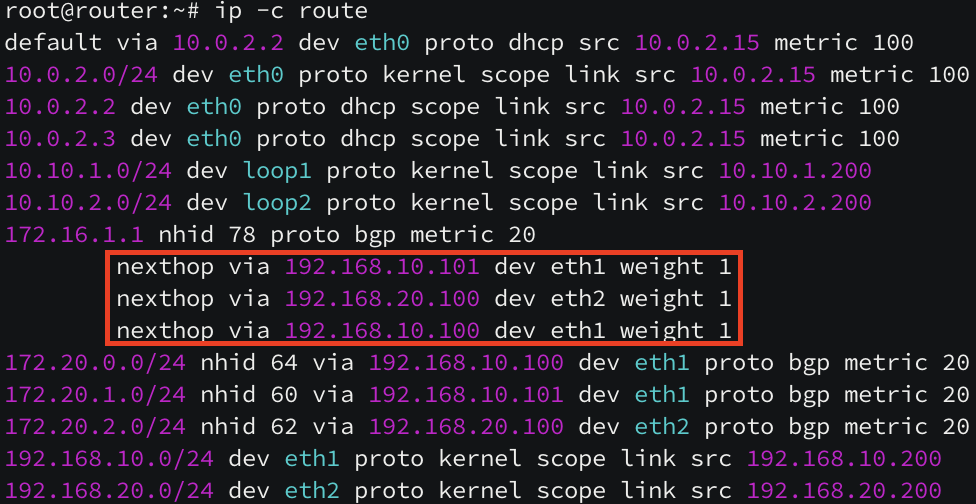
172.20.0.0/16 pod CIDR 대역 중 172.20.1.0/24 pod 네트워크만 k8s-w1(192.168.10.101) 노드로 라우팅이 되어 있지만, 172.20.2.0/24 pod CIDR 대역 대의 라우팅(k8s-w0 노드)이 보이지 않습니다.
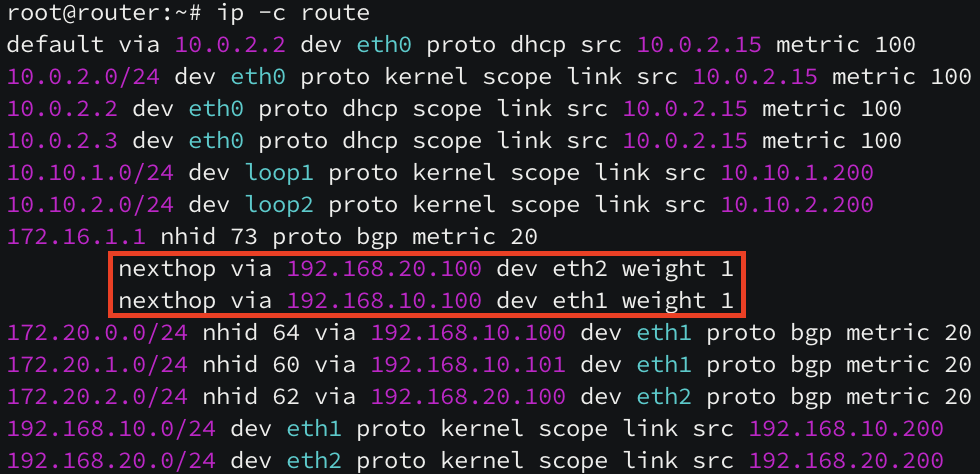
[ k8s-w1 노드의 라우팅 테이블 ]
172.20.0.0/16 pod CIDR 대역 중 172.20.0.0/24 pod 네트워크만 k8s-ctr(192.168.10.100) 노드로 라우팅이 되어 있지만, 172.20.2.0/24 pod CIDR 대역 대의 라우팅(k8s-w0 노드)이 보이지 않습니다.
[ k8s-w0 노드의 라우팅 테이블 ]
172.20.2.0/24 pod CIDR 자신의 네트워크 대역은 cilium 이 활성화되어 있지만, k8s-ctr 노드와 k8s-w1 노드로 라우팅되어 있지 않습니다. 실제 패킷 캡처를 통해 네트워크 통신 여부도 살펴보겠습니다.
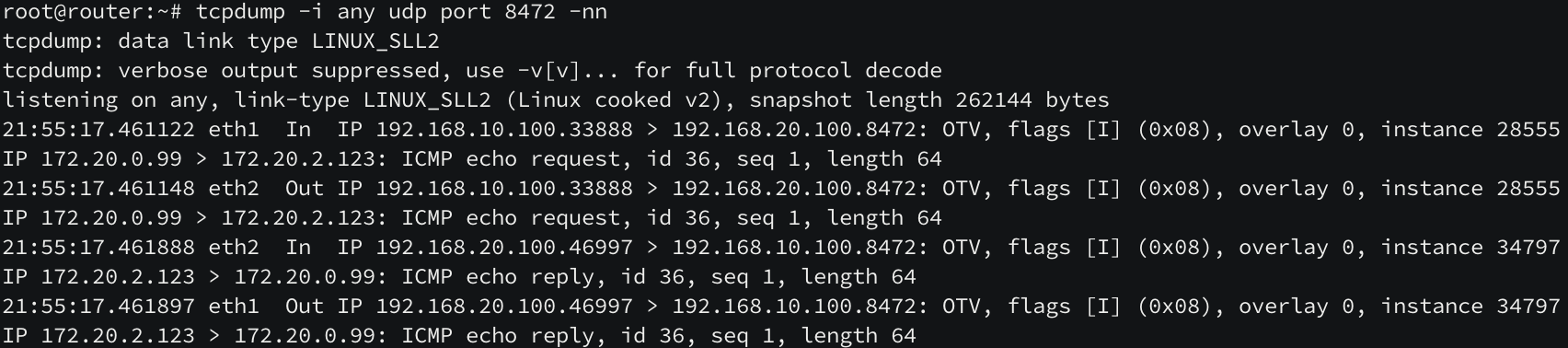
다른 네트워크 대역으로 통신 시 router 를 지나가니, router 노드에서 tcpdump 로 패킷을 스니핑합니다. k8s-ctr 서버에 위치한 curl-pod 로 k8s-w0 에 위치한 webpod 로 통신 시, 정상적으로 통신이 되지 않는 현상을 볼 수 있습니다.
아래 캡쳐된 네트워크 패킷들을 보면, eth1 로 들어왔는데 인터넷 전용 인터페이스인 eth0 으로 빠져나갔습니다. (eth0 인터페이스는 외부에서 쿠버네티스에 접근하기 위한 용도로 k8s 클러스터에서 접근할 일이 없습니다!)
통신 불가의 문제를 해결하려면 static routing 을 노드가 생성될 때마다 추가할 수 있지만 수동 처리에는 한계가 있습니다.
BGP, Encapsulation (Overlay Network) 방법들을 통해 문제를 해결합니다.
Encapsulation (Overlay Network)
설령 pod 대역 대의 IP 주소를 알지 못 하더라도 라우터는 노드의 IP 주소를 알고 라우팅을 할 수 있기 때문에, 노드의 IP 주소로 한 번 감싸 패킷을 보내면 통신이 가능해집니다.
여타 다른 CNI 플러그인과 같이 VXLAN 모드, GENEVE 모드를 통해 원본 패킷을 감싸 보낼 수 있습니다. 다른 네트워크 플러그인에서는 Overlay Network 라고 부르는데 Cilium 에서는 encapsulation 이라고 부릅니다.
Encapsulation 설정
VXLAN 과 GENEVE 를 활성화하려면 CONFIG_VXLAN 과 CONFIG_GENEVE 커널 설정을 활성화 해야 합니다.
아래와 같이 커널 옵션을 살펴보면 'm' 모듈로 컴파일되어 있어 직접 커널에 로드해서 사용합니다. modprobe 지시자로 원하는 모드를 선택하여 Overlay Network 를 활성화합니다.
나머지 두 노드에도 똑같이 설정을 해줍니다.
커널 설정 완료 후 helm routingMode=tunnel 옵션과 tunnelProtocol 옵션을 활성화 하여 cilium 을 rollout 해주면 모든 세팅이 완료됩니다.
cilium 의 속성을 확인해보면 routing 모드가 tunnel 유형으로 바뀌고 tunnel 프로토콜이 vxlan 으로 변경된 것을 확인할 수 있습니다.
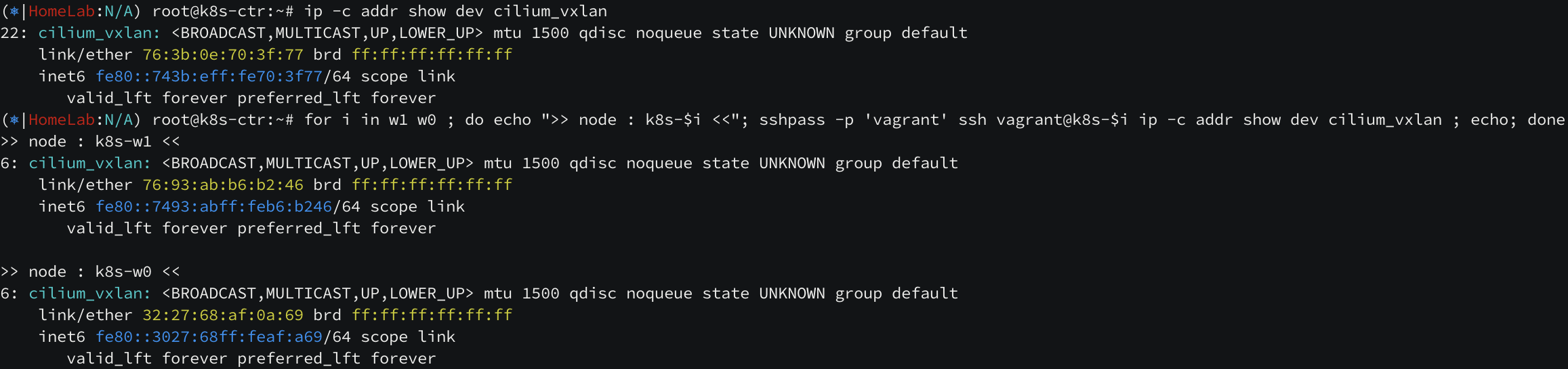
완료 후 변화된 점들을 하나씩 알아보겠습니다. 클러스터에 존재하는 서버들에 cilium_vxlan 인터페이스가 새롭게 생성되었습니다.
라우팅 테이블도 클러스터의 pod CIDR 대역들이 모두 올라온 것을 확인할 수 있습니다.
k8s-ctr 서버에서는 podCIDR 대역이 172.20.0.98 로 라우팅 되고, k8s-w1 서버에서는 podCIDR 대역이 172.20.1.11 로 라우팅 되고, k8s-w0 서버에서는 podCIDR 대역이 172.20.2.71 로 라우팅 되는데 이 세 IP 가 cilium 에서 라우팅을 위해 만든 IP 입니다.
# cilium 파드 이름 지정
export CILIUMPOD0=$(kubectl get -l k8s-app=cilium pods -n kube-system --field-selector spec.nodeName=k8s-ctr -o jsonpath='{.items[0].metadata.name}')
export CILIUMPOD1=$(kubectl get -l k8s-app=cilium pods -n kube-system --field-selector spec.nodeName=k8s-w1 -o jsonpath='{.items[0].metadata.name}')
export CILIUMPOD2=$(kubectl get -l k8s-app=cilium pods -n kube-system --field-selector spec.nodeName=k8s-w0 -o jsonpath='{.items[0].metadata.name}')
echo $CILIUMPOD0 $CILIUMPOD1 $CILIUMPOD2
# router 역할 IP 확인
kubectl exec -it $CILIUMPOD0 -n kube-system -c cilium-agent -- cilium status --all-addresses | grep router
kubectl exec -it $CILIUMPOD1 -n kube-system -c cilium-agent -- cilium status --all-addresses | grep router
kubectl exec -it $CILIUMPOD2 -n kube-system -c cilium-agent -- cilium status --all-addresses | grep router
Encapsulation 통신 과정
샘플 애플리케이션을 활용하여 통신 과정을 살펴보겠습니다.
자기 자신이 누구인지 알려주는 3 개의 webpod 와 컨트롤 노드에만 배치할 curl-pod 를 배포하고, router 노드에서 패킷들을 확인해봅니다.
cilium 라우팅 방식을 설명하기 앞서, 쿠버네티스의 파드 IP 통신 규약을 잠시 살펴봅니다.
쿠버네티스 네트워크 모델은 아래 4가지 요구사항을 만족해야 합니다.
파드와 파드 간 통신 시 NAT 없이 통신이 가능해야함
노드의 에이전트(예. kubelet, 시스템 데몬)는 파드와 통신이 가능해야함
호스트 네트워크를 사용하는 파드는 NAT 없이 파드와 통신이 가능해야함
서비스 클러스터 IP 대역과 파드가 사용하는 IP 대역은 중복되지 않아야함
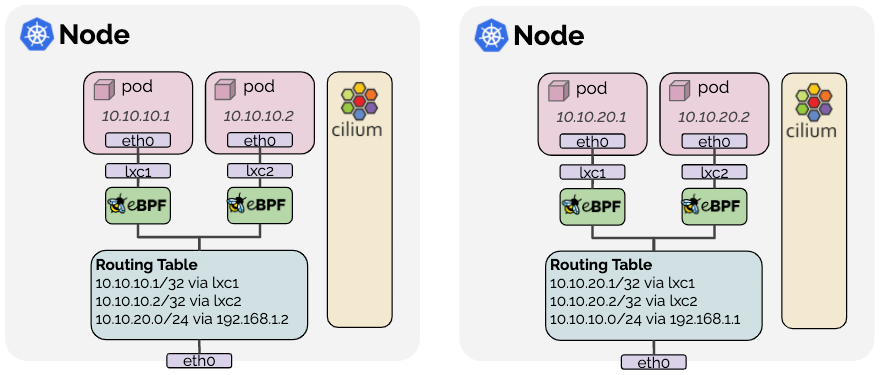
이 중 첫 번째 "NAT 없이 통신" 이라는 표현이 헷갈릴 수 있는데, 파드들은 서로의 IP 만 보고 통신할 수 있다는 의미입니다. 예를 들어, 파드 A(10.244.1.5)에서 파드 B(10.244.2.10)로 패킷을 보낼 때 파드 B가 받는 패킷의 source IP는 10.244.1.5 그대로 유지됩니다. 이렇게 하기 위해서는 CNI 가 IP 를 변환해주어야 한다는 것입니다. 이러한 방식을 지원하기 위해 cilium 라우팅은 캡슐화 방식과 네이티브 라우팅 방식이 존재합니다.
1. 캡슐화(Encapsulation) 방식
특징
기본 동작 모드로 VXLAN(8472/UDP) 또는 Geneve(6081/UDP) 사용
모든 노드가 터널 메시를 구성하여 트래픽 캡슐화
기본 네트워크가 PodCIDR 을 인식할 필요 없음
장점
단순성: 네트워크 토폴로지와 무관하게 동작 (네트워크가 podCIDR 을 인식할 필요 없고 서로 도달만 가능하다면 기본 네트워크 토폴리지는 중요하지 않음)
주소 공간: 더 큰 주소 공간 활용 가능 (새로운 IP로 캡슐화 하기 때문에 기본 네트워킹 주소 크기에 의존하지 않음)
자동 구성: 새 노드 자동 메시 통합 (Kubernetes 와 같은 오케스트레이션 시스템과 함께 실행될 때, 할당 관련 접두사를 포함한 클러스터의 모든 노드 목록이 각 에이전트에 자동으로 제공)
신원 컨텍스트: 메타데이터와 보안 관련 Identifier 전송 가능 (캡슐화 프로토콜은 네트워크 패킷과 함께 메타데이터를 전달 가능)
단점
MTU 오버헤드: 패킷당 50바이트 오버헤드로 처리량 감소 (점보 프레임으로 완화 가능)
캡슐화 방식은 Cilium 노드들이 서로 연결될 수 있고, 네트워크와 방화벽 정책에서 캡슐화된 패킷을 허용한다면 라우팅 요구사항이 충족됩니다. 하지만 IPv4 기반 터널링은 완전히 지원하지만, IPv6 기반 터널링은 아직 완전히 지원되지 않습니다. 캡슐화로 인한 성능 오버헤드도 존재합니다. 하지만 대부분의 환경에서 안정적으로 동작하며 복잡한 네트워크 토폴로지에서도 문제없이 사용할 수 있습니다.
BGP 데몬이 실행 중이지만, 클러스터 네트워크에 기본 서브넷이 있는 경우 트래픽을 항상 BGP 라우터에 라우팅할 필요는 없습니다.
각 노드에 L2 연결을 보장하기 위해 아래와 같이 옵션을 추가할 수 있습니다.
direct-routing-skip-unreachable: true (auto-direct-node-routes 옵션과 함께 사용)
네트워크 요구사항
네이티브 라우팅은 네이티브 패킷 포워딩 모드를 활성화하여 Cilium 이 직접 네트워크의 라우팅을 수행합니다. 즉, 클러스터 노드를 연결하는 네트워크는 podCIDR 를 라우팅할 수 있어야 합니다.
즉 노드의 Linux 커널은 Cilium 을 실행하는 모든 노드의 Pod 또는 기타 워크로드 패킷을 전달하는 방법을 알고 있어야 합니다. 이는 두 가지 방법으로 달성할 수 있습니다.
다른 모든 pod 에 전달할 수 있는 라우터에 위임 (Linux 노드는 해당 라우터를 가리키는 기본 경로를 포함) => 해당 모델은 주로 클라우드 공급자 네트워크 통합에 사용
각 노드가 다른 모든 파드의 IP 들을 인식 (Linux 커널 라우팅 테이블에 삽입) (auto-direct-node-routes: true) 모든 노드가 L2 에 존재한다면 옵션을 활성화하여 처리 가능하지만, 그렇지 않은 경우 BGP 데몬을 활용하여 경로 전파 필요
네이티브 라우팅은 캡슐화 오버헤드 없이 최고 성능을 제공하여 클라우드 환경이나 BGP를 지원하는 네트워크에서 주로 사용됩니다.
3. AWS ENI 방식
설정
ipam: eni
enable-endpoint-routes: "true"
auto-create-cilium-node-resource: "true"
egress-masquerade-interfaces: eth+
AWS ENI 방식을 사용하려면 ipam 을 eni 모드로 변경해야 합니다. (ipam: eni)
enable-endpoint-routes: "true" 옵션은 ENI veth 쌍으로 직접 라우팅 (cilium_host 인터페이스로 라우팅 불필요)
auto-create-cilium-node-resource: "true" 옵션은 모든 필수 ENI 매개변수를 세팅하는 CiliumNode 리소스를 자동 생성
(이 기능을 비활성화하고 사용자가 리소스를 수동으로 제공할 수도 있습니다.) egress-masquerade-interfaces: eth+ 옵션은 마스커레이딩 대상을 지정할 수 있는 인터페이스 선택자 (enable-ipv4-masquerade: "false" 옵션을 통해 마스커레이딩을 완전히 비활성화할 수 있습니다)
장점
라우팅 불필요 (AWS VPC 에서 직접 라우팅 가능한 ENI IP 를 할당. VPC 내 포드 트래픽 통신이 간소화되고 SNAT 불필요)
보안 그룹 생성 가능 (pod의 보안 그룹은 노드별로 구성. 노드 풀을 생성하고 각 pod에 서로 다른 보안 그룹을 할당할 수 있음)
단점
IP 제한 (EC2 인스턴스당 ENI IP 수가 제한되어 있음)
IP 할당 지연 (ENI 및 ENI IP 할당에는 속도 제한이 적용되는 EC2 API 와 상호작용하여 속도 제한됨)
구성
ingress: ENI 인터페이스(ethN)에서 트래픽 수신 후 veth 쌍으로 전달
egress: 파드에서 기본 경로를 통해 ENI 별 라우팅 테이블 사용
AWS ENI 방식은 AWS 네이티브 네트워킹의 장점을 최대한 활용하면서 파드에 직접 VPC IP를 할당합니다. 하지만 인스턴스 타입에 따른 ENI 제한과 EC2 API 의존성을 고려해야 합니다.
4. Google Cloud 방식
설정
gke.enabled: true # 다음 옵션들 자동 활성화:
# ipam: kubernetes
# routing-mode: native
# enable-endpoint-routes: true
ipv4-native-routing-cidr: x.x.x.x/y
gke.enabled: true 옵션으로 google cloud 방식을 사용할 수 있으며, 아래 옵션들이 자동 활성화된다.
ipam: kubernetes: Kubernetes 호스트 범위 IPAM 활성화
routing-mode: native: 네이티브 라우팅 모드 활성화
enable-endpoint-routes: true: 노드에서 엔드포인트별 라우팅 활성화(로컬 노드 경로를 자동으로 비활성화)
라우팅 불필요 (Cilium 이 특정 쿠버네티스 노드에 할당된 PodCIDR을 기반으로 파드에 별칭 IP 를 할당하면 Google Cloud 네트워크에서 라우팅)
Masquerading 지원 (Cluster CIDR 외부 영역으로 트래픽 이동 시 자동으로 라우팅 가능한 IP 주소로 Masquerading 변환)
eBPF 기반 로드밸런싱 (ClusterIP 로드 밸런싱을 eBPF 기반으로 지원. GKE v1.15 이상 또는 Linux 커널 4.19 이상을 실행하는 경우, 모든 NodePort/ExternalIP/HostPort 서비스 타입도 eBPF 기반으로 처리)
네트워크 정책 및 가시성 지원 (eBPF 기반 NetworkPolicy 및 가시성 지원)
Google Cloud에서 Cilium을 실행할 경우, 네이티브 라우팅 구성 으로 실행되는 Cilium과 함께 Google Cloud의 네트워킹 계층을 활용할 수 있습니다. Alias IP를 통해 캡슐화 오버헤드 없이 파드 간 직접 통신이 가능하며, eBPF 기반으로 모든 네트워킹 기능이 처리됩니다.
Cilium Masquerading
pod IP 들은 사설 주소이기 때문에 공개적으로 라우팅 불가합니다. 이런 상황에서 클러스터 외부로 나가려면 모든 트래픽의 출발지 IP 들을 노드의 IP 로 변경할 필요가 있습니다. (노드 IP 는 네트워크에서 라우팅이 가능한 주소이기 때문) SNAT 의 한 형태라고 볼 수 있습니다.
Q. SNAT 과 Masquerading 의 차이점은? A. 두 가지 방식 모두 출발지 주소를 변경하는 것은 동일하지만, SNAT 은 정적으로 고정 IP 로 변경하고 Masquerading 은 인터페이스에 들어오는 패킷의 IP 를 동적으로 확인하여 변경합니다. IP 주소를 변경하는 시점이 다릅니다. 고정 IP 환경에서는 SNAT 가 더 효율적이고, 동적 IP 환경에서는 Masquerading 이 필수적입니다.
필수적으로 보이지만, pod IP 까지 라우팅이 가능한 경우 아래와 같이 Masquerading 을 비활성화 할 수 있습니다.
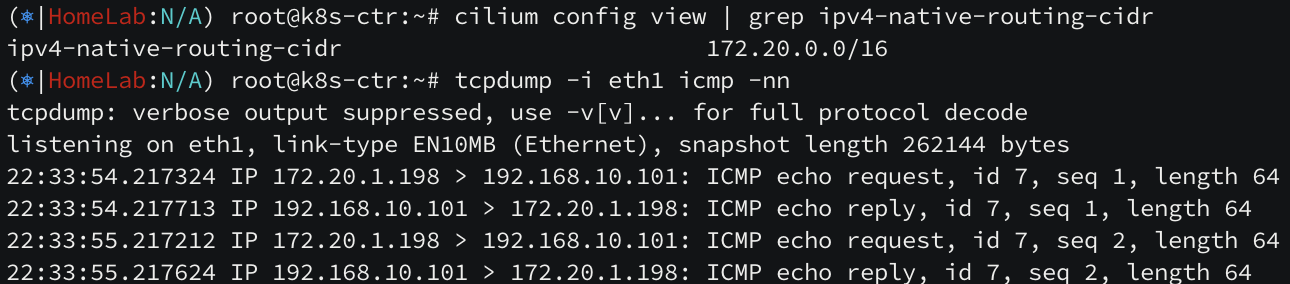
앞서 설명했듯이 "파드와 파드 간 통신 시 NAT 없이 통신이 가능해야한다" CNI 요구사항에 따라 pod 대역대는 Masquerading 하지 않습니다. 따라서 pod 대역대는 ip?-native-routing-cidr 옵션을 통해 변환 제외합니다.
예를 들어, Pod 들이 10.244.1.0/24 범위의 IP를 사용한다면, 같은 범위 내의 다른 Pod 들로 가는 트래픽은 변환하지 않습니다. 즉Pod A(10.244.1.10)에서 Pod B(10.244.1.20)로 통신할 때는 Pod IP 주소를 그대로 유지합니다.
구현 방법
Cilium Masquerading 은 eBPF 기반 구현 방식과 iptables 구현 방식이 존재합니다.
eBPF 기반 구현
활성화 설정
bpf.masquerade: true # eBPF 마스커레이딩 활성화
특징
고성능: 가장 효율적인 구현 방식
BPF Host-Routing: 기본적으로 BPF 호스트 라우팅 모드 활성화
NodePort 의존성: 현재 BPF NodePort 기능에 의존 (향후 제거 예정)
디바이스 감지: NodePort 디바이스 감지 메커니즘으로 자동 장치 선택
지원 프로토콜
TCP/UDP: 완전 지원
ICMP: Echo request/reply, Destination unreachable 제한 지원
상태 확인
kubectl -n kube-system exec ds/cilium -- cilium-dbg status | grep Masquerading
# 출력 예: Masquerading: BPF (ip-masq-agent) [eth0, eth1] 10.0.0.0/16
eBPF 구현은 커널 수준에서 최적화되어 최고 성능을 제공하지만, IPv6는 베타 상태입니다. masquerading 프로그램이 실행되는 디바이스에서만 동작하며, 클러스터 노드의 External IP 로의 트래픽은 masquerading 하지않는 특징이 있습니다.
ip-masq-agent 는 세밀한 masquerading 제어를 제공하며, Fsnotify 를 통해 설정 파일 변경을 실시간으로 추적합니다. 기본적으로 사설 주소와 링크 로컬 주소는 masquerading 에서 제외됩니다.
iptables 기반 구현
특징
레거시 구현: 모든 커널 버전에서 동작
기본 동작: Cilium이 아닌 네트워크 디바이스로 나가는 모든 트래픽 마스커레이딩
인터페이스 제한: egress-masquerade-interfaces 옵션으로 특정 인터페이스만 masquerading 지정 가능 인터페이스 우선순위 - egress-masquerade-interfaces 설정 시: 해당 인터페이스 우선 사용 - 미설정 시: devices 필드의 인터페이스 사용 - 접두사 매칭: eth+ ens+ 형태로 여러 인터페이스 패턴 지정 가능