cilium 이 k8s 플랫폼 내에서 동작을 하기 때문에 k8s 의 성능 테스트를 먼저 살펴보고, 그 다음 cilium 성능 테스트를 살펴보겠습니다.
지금까지는 Vagrant 로 VM 을 관리하면서 실습을 진행하였지만, 성능 테스트는 최대한 호스트 머신의 자원을 최대한 사용하는 것이 좋기 때문에 kind 로 스터디 실습을 진행하겠습니다.
실습 환경 구성
kind 클러스터를 생성할 때 kube-controller-manager, kube-scheduler, etcd, kube-proxy 의 메트릭 수집을 위해 bind-address를 설정합니다.
kind create cluster --name myk8s --image kindest/node:v1.33.2 --config - <<EOF
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
extraPortMappings:
- containerPort: 30000
hostPort: 30000
- containerPort: 30001
hostPort: 30001
- containerPort: 30002
hostPort: 30002
- containerPort: 30003
hostPort: 30003
kubeadmConfigPatches:
- |
kind: ClusterConfiguration
controllerManager:
extraArgs:
bind-address: 0.0.0.0
etcd:
local:
extraArgs:
listen-metrics-urls: http://0.0.0.0:2381
scheduler:
extraArgs:
bind-address: 0.0.0.0
- |
kind: KubeProxyConfiguration
metricsBindAddress: 0.0.0.0
EOF
kube-ops-view 설치
helm repo add geek-cookbook https://geek-cookbook.github.io/charts/
helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 \
--set service.main.type=NodePort,service.main.ports.http.nodePort=30003 \
--set env.TZ="Asia/Seoul" --namespace kube-system
metrics-server 설치
helm repo add metrics-server https://kubernetes-sigs.github.io/metrics-server/
helm upgrade --install metrics-server metrics-server/metrics-server \
--set 'args[0]=--kubelet-insecure-tls' -n kube-system
prometheus-stack 설치
cat < monitor-values.yaml
prometheus:
prometheusSpec:
scrapeInterval: "15s"
evaluationInterval: "15s"
service:
type: NodePort
nodePort: 30001
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
service:
type: NodePort
nodePort: 30002
alertmanager:
enabled: false
defaultRules:
create: false
prometheus-windows-exporter:
prometheus:
monitor:
enabled: false
EOT
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack \
--version 75.15.1 -f monitor-values.yaml --create-namespace --namespace monitoring
Kube-burner 를 활용한 성능 테스트
소개
Kube-burner 는 Golang 으로 작성된 쿠버네티스 성능 및 확장성 테스트 오케스트레이션 프레임워크입니다.
주요 특징은 다음과 같습니다.
- 쿠버네티스 리소스를 대규모로 생성, 삭제, 조회, 패치 가능
- Prometheus 메트릭 수집 및 인덱싱 지원
- 다양한 측정(Measurements) 기능 제공
- 알림(Alerting) 기능 제공
- Kubernetes 공식 클라이언트 라이브러리인 client-go를 광범위하게 활용
설치
git clone https://github.com/kube-burner/kube-burner.git
cd kube-burner
# 바이너리 설치(추천) <mac M칩>
curl -LO https://github.com/kube-burner/kube-burner/releases/download/v1.17.3/kube-burner-V1.17.3-darwin-arm64.tar.gz # mac M
tar -xvf kube-burner-V1.17.3-darwin-arm64.tar.gz
sudo cp kube-burner /usr/local/bin
시나리오 1: 기본 배포 테스트
deployment 1개(pod 1개)를 생성하고 삭제하면서 jobIterations, qps, burst 의 의미를 확인합니다.
cat << EOF > s1-config.yaml
global:
measurements:
- name: none
jobs:
- name: create-deployments
jobType: create
jobIterations: 1 # How many times to execute the job , 해당 job을 5번 반복 실행
qps: 1 # Limit object creation queries per second , 초당 최대 요청 수 (평균 속도 제한) - qps: 10이면 초당 10개 요청
burst: 1 # Maximum burst for throttle , 순간적으로 처리 가능한 요청 최대치 (버퍼) - burst: 20이면 한순간에 최대 20개까지 처리 가능
namespace: kube-burner-test
namespaceLabels: {kube-burner-job: delete-me}
waitWhenFinished: true # false
verifyObjects: false
preLoadImages: true # false
preLoadPeriod: 30s # default 1m
objects:
- objectTemplate: s1-deployment.yaml
replicas: 1
EOF
#
cat << EOF > s1-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-{{ .Iteration}}-{{.Replica}}
labels:
app: test-{{ .Iteration }}-{{.Replica}}
kube-burner-job: delete-me
spec:
replicas: 1
selector:
matchLabels:
app: test-{{ .Iteration}}-{{.Replica}}
template:
metadata:
labels:
app: test-{{ .Iteration}}-{{.Replica}}
spec:
containers:
- name: nginx
image: nginx:alpine
ports:
- containerPort: 80
EOF
테스트 시 중요한 주요 필드는 다음과 같습니다.
| jobIterations | 작업 반복 횟수 |
| qps | 초당 쿼리 수(Query Per Second) |
| burst | 순간 최대 처리량 |
아래 명령어로 테스트를 해보겠습니다.
kube-burner init -c s1-config.yaml --log-level debug
preLoadImages: false
초기에 이미지 다운로드하지 않고, 바로 이미지를 컨테이너화하여 업로드합니다.
waitWhenFinished: false
테스트 구성대로 잘 만들어졌는지 확인하지 않고, 바로 종료합니다.
JobIterations: 5
Job 에 정의된 행위들이 반복되어 테스트를 수행합니다.

objects.replicas: 2
replica 갯수를 늘려 테스트를 수행합니다.

replica 갯수를 2로 증가시켜 테스트하면 10 개의 파드가 생성된 것을 확인할 수 있습니다.
jobIterations: 10
다시 job 의 반복 회수를 10 개로 증가시켜 qps 와 burst 의 의미를 파악해보겠습니다. 현재 qps 가 1 이어서 API Controller 에 1초에 1개의 요청만 할 수 있습니다. 1초에 1개씩 pod 가 생성되어 10초가 걸렸습니다.
jobIterations: 10, qps: 1, burst:10, objects.replicas: 1
jobIterations: 100, qps: 1, burst:100, objects.replicas: 1
두 가지 케이스 모두 qps 가 1 이지만 burst(순간 처리할 수 있는 요청 최대치) 가 jobIterations 와 같아 1초만에 수행할 수 있습니다.
jobIterations: 10, qps: 1, burst:20, objects.replicas: 2
2개의 레플리카를 10번에 걸쳐 생성하므로 20 개의 오브젝트를 생성 요청하는데 burst 가 20 이므로 1초에 생성됩니다.
jobIterations: 10, qps: 1, burst:10, objects.replicas: 2
마찬가지로, 2개의 레플리카를 10번에 걸쳐 생성하므로 20 개의 오브젝트를 생성 요청하는데 10 개의 bust 만 쓸 수 있으므로 1초씩 진행됩니다.
jobIterations: 20, qps: 2, burst:20, objects.replicas: 2
같은 원리로 처음에 조건이 부합하여 한 번에 처리가 진행이 되다가 슬슬 처리가 늦어지는 것을 알 수 있습니다.
시나리오 2: 노드 1대에 최대 파드 배포 (150개)
jobIterations: 100, qps: 300, burst: 300, replicas: 1로 설정하여 최대 150개 파드 배포 테스트 해보겠습니다.

5개의 노드가 아직 pending 상태로 남아있습니다. 원인 파악을 위해 99번 파드에 대해 자세히 살펴보겠습니다.

"Too many pods. preemption: 0/1 nodes are availale:" 라는 메세지를 볼 수 있고, node 의 상태를 확인해보니

모든 가용영역을 다 사용한 것을 볼 수 있습니다.
기본적으로 쿠버네티스는 노드당 110개의 파드만 허용합니다. 더 많은 파드를 배포하려면 다음과 같이 설정을 변경해야 합니다.
# 현재 설정 확인
kubectl get cm -n kube-system kubelet-config -o yaml
# maxPods 설정 변경
docker exec -it myk8s-control-plane bash
cat /var/lib/kubelet/config.yaml
apt update && apt install vim -y
vim /var/lib/kubelet/config.yaml
# maxPods: 150 추가
systemctl restart kubelet
systemctl status kubelet
exit
시나리오 3: 파드 300개 배포 시도
jobIterations: 300, qps: 300, burst: 300 objects.replicas: 1로 설정하여 최대 300개 파드 배포 테스트를 해보겠습니다.
파드 배포하기 전, 넉넉하게 400 개의 maxPod 를 설정하고 테스트를 수행합니다.
# maxPods 설정 변경
docker exec -it myk8s-control-plane bash
cat /var/lib/kubelet/config.yaml
apt update && apt install vim -y
vim /var/lib/kubelet/config.yaml
# maxPods: 400 추가
systemctl restart kubelet
systemctl status kubelet
exit

maxPod 를 최대치까지 늘렸는데 containerCreating 된 상태의 pod 들이 존재합니다. pod 로그들을 통해 원인을 파악해보면,

배포 시에 PodCIDR 대역 문제가 발생하는 것을 볼 수 있습니다.("no IP addresses available in range set") 현재 PodCIDR 이 /24 대역(252개 IP)이므로 300개 파드를 생성할 수 없습니다.
K8S Performance
최대 수용 규모와 내부 구조
쿠버네티스의 퍼포먼스를 이해하려면, 쿠버네티스의 내부 구조와 처리 절차들을 이해하고 있어야 합니다.
먼저 쿠버네티스 v1.33 기준 단일 클러스터 최대 수용 규모와 절차들은 다음과 같습니다.
- 노드 수: 5,000대 이하
- 노드당 파드 수: 110개 이하
- 총 파드 수: 150,000개 이하
- 총 컨테이너 수: 300,000개 이하
Kubernetes는 실제 사용자의 워크로드를 실행하는 Data Plane과 클러스터 전체를 관리하는 Control Plane으로 구성됩니다. Control Plane은 주로 kube-apiserver와 etcd로 구성되며, 이 두 컴포넌트에서 문제가 발생하면 리소스 관리에 심각한 영향을 미칩니다.


kube-apiserver
- HTTP(S) 기반의 RESTful API 서버
- YAML, JSON, Protobuf 형식으로 외부 클라이언트(kube-controller-manager, kubelet, kubectl 등)와 통신
- 클러스터상 리소스 관리를 위한 최소한의 기능을 제공
- 복잡한 로직(스케줄링, 네트워킹, Progressive Delivery 등)은 외부 컴포넌트에 위임하는 MSA 구조
etcd
- gRPC로 kube-apiserver와 통신하는 Key-Value 데이터베이스
- RAFT 알고리즘을 사용하여 리더 선출 및 Write-Ahead Logging(WAL) 방식으로 데이터 복제
- Split-brain 등의 문제를 처리하는 CAP 정리의 CP/EC 시스템
- 데이터 일관성이 매우 높지만 성능 상 한계 존재
K8S API 성능 분석
응답 시간 분석
Pod 개수에 따른 API 응답 시간을 측정한 결과 다음과 같습니다.
100개 Pod 조회
curl -o /dev/null -s -w 'Total: %{time_total}s\n' 127.0.0.1:8001/api/v1/pods?limit=100
# Result: Total: 0.031002s (31ms)
10,000개 Pod 조회
curl -o /dev/null -s -w 'Total: %{time_total}s\n' 127.0.0.1:8001/api/v1/pods?limit=10000
# Result: Total: 2.131027s (2,131ms - 약 70배 증가)
계산 결과, 리소스 한 개당 처리 시간은 약 0.21ms 씩 증가합니다. 데이터 전송량도 비례적으로 증가합니다:
- 100개 Pod: 약 0.45MB
- 10,000개 Pod: 약 44.4MB
응답 속도가 조금 늦긴 하지만 쿠버네티스의 안전성의 비용으로 생각한다면 그리 속도가 느린 것은 아닌 것 같다. 하지만 메모리의 사용량이 문제이다.
메모리 사용량 분석
etcd 는 요청 처리 시 메모리에 모든 데이터를 적재한 후 응답을 반환합니다.
# 프로세스 시작 후 안정화 상태
08:28:48 0 7 0.00 0.00 10.7G 110.0M 0.7% etcd
# 첫 번째 curl 요청 (메모리 사용량 60MB 증가)
08:29:24 0 7 6941.58 0.00 10.8G 236.7M 1.5% etcd
# 두 번째 curl 요청 (메모리 사용량 30MB 증가)
08:29:28 0 7 1162.00 0.00 10.8G 265.0M 1.7% etcd
# etcd GC 실행 후 (메모리 사용량 90MB 감소)
08:29:36 0 7 9306.00 0.00 10.9G 187.1M 1.2% etcd
요청 하나를 처리하는데 대략 30~60MB 정도의 메모리 공간이 필요하며 10,000 개의 Pod Resource를 Protobuf로 저장했을 때 필요한 저장공간 (35MB)과 거의 유사합니다.
kube-apiserver 의 경우, 더 복잡한 처리 과정을 거칩니다:
- etcd로부터 protobuf 포맷으로 데이터 수신
- Go struct로 역직렬화(deserialization)
- JSON 형태로 직렬화(serialization)
과정이 최소한으로 필요하고, 필요에 따라 버전 변환 및 타입 변환을 하기 때문에
# 프로세스 시작 후 안정화 상태
08:41:44 0 7 0.00 0.00 1.4G 691.4M 4.3% kube-apiserver
# 첫 번째 curl 요청 (메모리 사용량 120MB 증가)
08:41:49 0 7 9304.00 0.00 1.4G 750.7M 4.7% kube-apiserver
08:41:50 0 7 346.00 0.00 1.5G 815.9M 5.1% kube-apiserver
...
# 여덟번째 curl 127.0.0.1:8001/api/v1/pods?limit=10000 (메모리 사용량 유지)
08:42:19 0 7 1137.00 0.00 2.0G 1.1G 6.9% kube-apiserver
08:42:20 0 7 0.00 0.00 2.0G 1.1G 6.9% kube-apiserver
08:42:21 0 7 0.00 0.00 2.0G 1.1G 6.9% kube-apiserver
08:42:22 0 7 0.00 0.00 2.0G 1.1G 6.9% kube-apiserver
매 요청마다 약 100MB 내외의 메모리가 필요하며, 이는 JSON 데이터 크기의 약 2.5배에 해당합니다.
만약 100개의 동시 요청을 처리할 경우, kube-apiserver 메모리 용량이 6배인 6GB 까지 치솟고, cgroup 으로 설정한 hard limit 을 넘어가 OOM Kill 이 발생하게 됩니다.
# 30초 만에 메모리 사용량이 6GB까지 증가하여 OOM Kill 발생
01:52:34 0 7 118.00 0.00 1.4G 693.9M 4.3% kube-apiserver
01:52:55 0 7 36775.00 0.00 7.6G 6.0G 38.2% kube-apiserver
01:52:56 0 7 5954.00 0.00 0.0k 0.0k 0.0% kube-apiserver # OOM Killed
동일한 시간 동안 etcd의 메모리 사용량도 30배(6GB) 증가합니다.
01:52:30 0 7 0.00 0.00 10.8G 165.4M 1.0% etcd
01:52:45 0 7 14475.00 0.00 16.6G 6.0G 38.1% etcd
문제 발생 원인 분석
etcd 는 데이터 일관성을 위해 Range 요청 처리 중 Store 에 Lock을 걸고 해당 데이터를 복제합니다. 이 과정에서 대량의 메모리가 필요하며, Zero Copy 로 구현할 경우 성능 저하가 심각합니다. 심지어 etcd 관련 api 제약사항이 아래와 같습니다.
- etcd 에는 Range API 만 존재하여 대용량 데이터를 한 번에 처리해야 함
- kube-apiserver 도 이를 처리할 대안이 제한적
- 2초간 100건의 동일한 요청이 들어오면 메모리 급증 불가피
문제 발생 조건들을 살펴보면 한 번에 조회 가능한 리소스 개수가 매우 많고, 해당 리소스를 조회하는 요청이 매우 많았습니다.
kubelet 과 같은 컨트롤러가 특정 노드의 Pod 만 조회하려 할 때,
/api/v1/pods?fieldSelector=spec.nodeName=worker-node-10
kube-apiserver는 spec.nodeName에 대한 인덱싱이 없어 etcd에서 모든 Pod를 검색해야 하므로, 결국 전체 데이터를 로드하게 됩니다.
해결 방안
1. API Limit/Continue 활용
limit 과 continue 를 활용해서 한 번에 조회하는 양을 제한하여 메모리 사용량을 덜 사용합니다.
# kubectl의 실제 요청 예시
kubectl get po -v6
# GET /api/v1/namespaces/default/pods?limit=500
# GET /api/v1/namespaces/default/pods?continue=eyJ2IjoibWV0YS5rOHMuaW8vdjEiLCJydiI6MzkzNDcsInN0YXJ0IjoidGVzdC01NzQ2ZDRjNTlmLTJuNTUyXHUwMDAwIn0&limit=500
2. ResourceVersion/ResourceVersionMatch 활용
Strong Consistency 가 필요하지 않은 경우 etcd 에 요청하지 않고 api server 에 존재하는 캐시된 데이터를 사용합니다.
# resourceVersion="0"으로 요청하면 kube-apiserver 캐시에서 데이터 반환
curl "127.0.0.1:8001/api/v1/pods?resourceVersion=0"
이 방법을 사용하면 etcd 부하는 완전히 제거되지만, kube-apiserver 의 OOM은 여전히 발생할 수 있습니다.
3. API Priority and Fairness(APF) 활용
요청을 분류하여 Rate Limit 을 적용하는 방법도 있습니다.
apiVersion: flowcontrol.apiserver.k8s.io/v1beta3
kind: FlowSchema
metadata:
name: cilium-pods
spec:
distinguisherMethod:
type: ByUser
matchingPrecedence: 1000
priorityLevelConfiguration:
name: cilium-pods
rules:
- resourceRules:
- apiGroups:
- "cilium.io"
clusterScope: true
resources:
- "*"
verbs:
- "list"
---
apiVersion: flowcontrol.apiserver.k8s.io/v1beta3
kind: PriorityLevelConfiguration
metadata:
name: cilium-pods
spec:
type: Limited
limited:
nominalConcurrencyShares: 5
limitResponse:
queuing:
handSize: 4
queueLengthLimit: 50
queues: 16
type: Queue
운영 관점의 해결법
- 불필요한 리소스 지속적 삭제
- 적절한 리소스 개수 유지
- 모니터링을 통한 사전 예방
시나리오 4: api-intensive - 파드를 생성(configmap, secret) 후 삭제
kube-burner 의 예제 샘플인 examples/workloads/api-intensive 를 조금 수정해서 api-server 의 과부화를 유도해보겠습니다.
cat << EOF > api-intensive-100.yml
jobs:
- name: api-intensive
jobIterations: 100
qps: 100
burst: 100
namespacedIterations: true
namespace: api-intensive
podWait: false
cleanup: true
waitWhenFinished: true
preLoadImages: false # true
objects:
- objectTemplate: templates/deployment.yaml
replicas: 1
- objectTemplate: templates/configmap.yaml
replicas: 1
- objectTemplate: templates/secret.yaml
replicas: 1
- objectTemplate: templates/service.yaml
replicas: 1
- name: api-intensive-patch
jobType: patch
jobIterations: 10
qps: 100
burst: 100
objects:
- kind: Deployment
objectTemplate: templates/deployment_patch_add_label.json
labelSelector: {kube-burner-job: api-intensive}
patchType: "application/json-patch+json"
apiVersion: apps/v1
- kind: Deployment
objectTemplate: templates/deployment_patch_add_pod_2.yaml
labelSelector: {kube-burner-job: api-intensive}
patchType: "application/apply-patch+yaml"
apiVersion: apps/v1
- kind: Deployment
objectTemplate: templates/deployment_patch_add_label.yaml
labelSelector: {kube-burner-job: api-intensive}
patchType: "application/strategic-merge-patch+json"
apiVersion: apps/v1
- name: api-intensive-remove
qps: 500
burst: 500
jobType: delete
waitForDeletion: true
objects:
- kind: Deployment
labelSelector: {kube-burner-job: api-intensive}
apiVersion: apps/v1
- name: ensure-pods-removal
qps: 100
burst: 100
jobType: delete
waitForDeletion: true
objects:
- kind: Pod
labelSelector: {kube-burner-job: api-intensive}
- name: remove-services
qps: 100
burst: 100
jobType: delete
waitForDeletion: true
objects:
- kind: Service
labelSelector: {kube-burner-job: api-intensive}
- name: remove-configmaps-secrets
qps: 100
burst: 100
jobType: delete
objects:
- kind: ConfigMap
labelSelector: {kube-burner-job: api-intensive}
- kind: Secret
labelSelector: {kube-burner-job: api-intensive}
- name: remove-namespace
qps: 100
burst: 100
jobType: delete
waitForDeletion: true
objects:
- kind: Namespace
labelSelector: {kube-burner-job: api-intensive}
EOF
# 수행
kube-burner init -c api-intensive-100.yml --log-level debug
100 개의 네임스페이스에 각각 Deployment, ConfigMap, Secret, Service 를 QPS 100 으로 대량 생성하고 생성된 리소스들을 패치하여 API 서버의 UPDATE 성능을 측정합니다. 이후 모든 리소스를 순차적으로 삭제하여 DELETE API 성능까지 종합적으로 테스트하는 예제입니다.
모니터링
다른 클라이언트로부터 받는 kube-apiserver 요청의 개수를 모니터링하고 싶다면, API 서버 QPS를 리소스별, 요청 타입별, 응답 코드별 모니터링을 진행하면 됩니다.
최근 5분간 Kubernetes API 서버가 처리한 요청에 대한 집계
# 응답 코드별 집계
sum by(verb) (irate(apiserver_request_total{job="apiserver"}[5m]))
# 리소스, 응답 코드, verb 별 집계
sum by(resource, code, verb) (irate(apiserver_request_total{job="apiserver"}[5m]))
# 최종
sum by(resource, code, verb) (rate(apiserver_request_total{resource=~".+"}[5m]))
or
sum by(resource, code, verb) (irate(apiserver_request_total{resource=~".+"}[5m]))
Cilium Performance
cilium 의 퍼포먼스를 이해하려면, cilium 의 내부 구조와 처리 절차들을 이해하고 있어야 합니다.
Cilium 내부 구조

cilium 개발자들은 kube-apiserver 나 clustermesh 에서 이벤트를 받아 ebpf 프로그램으로 처리하는데, 각 구간마다 장애가 발생한다면 어떻게 처리해야 할지 고민이 되었습니다.

이벤트가 적절한지 검증이 필요했고, 장애가 발생할 경우 재시도 로직이 필요했고, 상태를 저장할 필요가 있었습니다.

stateDB 와 효율적인 업데이트를 위한 Reconciler 컴포넌트를 중간에 두어 처리할 수 있게 하였습니다.
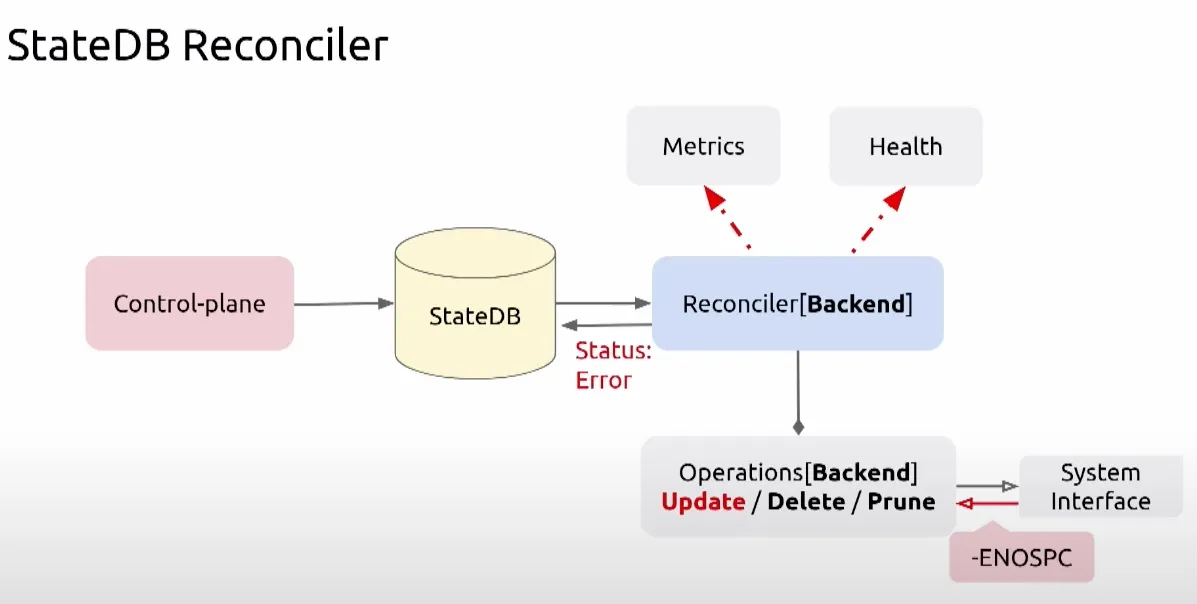
그래서 위와 같이 상태를 저장하는 StateDB 와 안정적인 운영을 위한 reconciler 컴포넌트(재시도 로직 및 헬스, 메트릭 체크) 를 도입하게 되었습니다.
Cilium 실습 환경 구성
kind 를 활용하여 cilium 테스트를 위한 실습 환경을 구성해보겠습니다.
kind create cluster --name myk8s --image kindest/node:v1.33.2 --config - <<EOF
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
extraPortMappings:
- containerPort: 30000
hostPort: 30000
- containerPort: 30001
hostPort: 30001
- containerPort: 30002
hostPort: 30002
- containerPort: 30003
hostPort: 30003
kubeadmConfigPatches: # Prometheus Target connection refused bind-address 설정
- |
kind: ClusterConfiguration
controllerManager:
extraArgs:
bind-address: 0.0.0.0
etcd:
local:
extraArgs:
listen-metrics-urls: http://0.0.0.0:2381
scheduler:
extraArgs:
bind-address: 0.0.0.0
- |
kind: KubeProxyConfiguration
metricsBindAddress: 0.0.0.0
networking:
disableDefaultCNI: true
kubeProxyMode: none
podSubnet: "10.244.0.0/16" # cluster-cidr
kubeadmConfigPatches:
- |
kind: ClusterConfiguration
controllerManager:
extraArgs:
allocate-node-cidrs: "true"
cluster-cidr: "10.244.0.0/16"
node-cidr-mask-size: "22"
EOF
cilium install --version 1.18.1 --set ipam.mode=kubernetes --set ipv4NativeRoutingCIDR=172.20.0.0/16 \
--set routingMode=native --set autoDirectNodeRoutes=true --set endpointRoutes.enabled=true --set directRoutingSkipUnreachable=true \
--set kubeProxyReplacement=true --set bpf.masquerade=true \
--set endpointHealthChecking.enabled=false --set healthChecking=false \
--set hubble.enabled=true --set hubble.relay.enabled=true --set hubble.ui.enabled=true \
--set hubble.ui.service.type=NodePort --set hubble.ui.service.nodePort=30003 \
--set prometheus.enabled=true --set operator.prometheus.enabled=true --set envoy.prometheus.enabled=true --set hubble.metrics.enableOpenMetrics=true \
--set hubble.metrics.enabled="{dns,drop,tcp,flow,port-distribution,icmp,httpV2:exemplars=true;labelsContext=source_ip\,source_namespace\,source_workload\,destination_ip\,destination_namespace\,destination_workload\,traffic_direction}" \
--set debug.enabled=true # --dry-run-helm-values
# metrics-server
helm repo add metrics-server https://kubernetes-sigs.github.io/metrics-server/
helm upgrade --install metrics-server metrics-server/metrics-server --set 'args[0]=--kubelet-insecure-tls' -n kube-system
kubectl apply -f https://raw.githubusercontent.com/cilium/cilium/1.18.1/examples/kubernetes/addons/prometheus/monitoring-example.yaml
kubectl patch svc -n cilium-monitoring prometheus -p '{"spec": {"type": "NodePort", "ports": [{"port": 9090, "targetPort": 9090, "nodePort": 30001}]}}'
kubectl patch svc -n cilium-monitoring grafana -p '{"spec": {"type": "NodePort", "ports": [{"port": 3000, "targetPort": 3000, "nodePort": 30002}]}}'
cilium 을 설치하기 위해 disableDefaultCNI: true 옵션과 kubeProxyMode: none 옵션을 사용해서 CNI 없이 클러스터 구성을 하고 이후 cilium CNI 플러그인을 설치해서 네트워킹을 활성화합니다. 모니터링을 위한 prometheus 와 grafana 도 설치합니다.
참고로 control-plane 을 3개를 띄우면 HA Proxy 를 구성할 수 있다고 합니다.
# Prometheus Target connection refused bind-address 설정 : kube-controller-manager , kube-scheduler , etcd , kube-proxy
kind create cluster --name myk8s --image kindest/node:v1.33.2 --config - <<EOF
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: control-plane
- role: control-plane
networking:
apiServerAddress: "127.0.0.1"
apiServerPort: 6443
disableDefaultCNI: true
kubeProxyMode: none
EOF
#
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3e0a95aff7a6 kindest/haproxy:v20230606-42a2262b "haproxy -W -db -f /…" 12 minutes ago Up 12 minutes 127.0.0.1:6443->6443/tcp myk8s-external-load-balancer
981cf7c18ac6 kindest/node:v1.33.2 "/usr/local/bin/entr…" 12 minutes ago Up 12 minutes 127.0.0.1:49776->6443/tcp myk8s-control-plane2
40b5b2ebe5bf kindest/node:v1.33.2 "/usr/local/bin/entr…" 12 minutes ago Up 12 minutes 127.0.0.1:49775->6443/tcp myk8s-control-plane
6aa3d5b5b1ab kindest/node:v1.33.2 "/usr/local/bin/entr…" 12 minutes ago Up 12 minutes 127.0.0.1:49777->6443/tcp myk8s-control-plane3
Cilium 테스트
cilium 에서는 네트워크 관련 성능 및 기능 테스트 도구를 제공합니다. cilium connectivity -h 명령어로 테스트 관련 명령어를 확인할 수 있습니다.
cilium connectivity -h
Connectivity troubleshooting
Available Commands:
perf Test network performance
test Validate connectivity in cluster
cilium connectivity test --debug
🐛 [cilium-test-1] Registered connectivity tests
🐛 <Test no-policies, 8 scenarios, 0 resources, expectFunc <nil>>
🐛 <Test no-policies-from-outside, 1 scenarios, 0 resources, expectFunc <nil>>
🐛 <Test no-policies-extra, 2 scenarios, 0 resources, expectFunc <nil>>
...
test 명령어 같은 경우에는 네트워크 정책이 없을 때 outside 로 통신이 되는지 여부, 모든 ingress deny 하고 나서 통신이 되는지 여부 등 통신 pass / fail 의 점검을 할 수 있습니다. perf 명령어는 같은 노드 내부에서 통신 성능 테스트를 하거나, host to pod 경유 흐름에서 통신 성능 테스트를 수행합니다.
iperf3 을 활용해서 대역폭을 측정할 수도 있습니다.
# TCP 양방향 테스트
kubectl exec -it deploy/iperf3-client -- iperf3 -c iperf3-server -t 5 --bidir
결과 예시:
- Client→Server (TX): 53.6 Gbps
- Server→Client (RX): 39.9 Gbps
- 재전송: TX=11, RX=14 (일부 패킷 손실)
- 전체적으로 40-54Gbps 대역폭 측정
Cilium BPF Map 모니터링
Map Operations 분석
# 상위 5개 BPF Map 연산 확인
topk(5, avg(rate(cilium_bpf_map_ops_total{k8s_app="cilium", pod=~"$pod"}[5m]))
by (pod, map_name, operation))
cilium_bpf_map_ops_total 메트릭으로 다음을 확인할 수 있습니다:
- BPF 맵 조작 횟수 (누적 카운터)
- Pod별, 맵별, 연산별 평균 발생률
- 어떤 BPF 맵에서 가장 많은 연산이 발생하는지 파악
eBPF Maps 최적화
mapDynamicSizeRatio 설정
모든 eBPF 맵은 용량 제한이 설정되어 있으며, Cilium은 시스템 전체 메모리 비중을 기준으로 자동 계산된 기본값을 사용합니다.
# eBPF 맵 용량을 시스템 메모리의 1%로 설정
mapDynamicSizeRatio: 0.01
Cilium 튜닝
Cilium Endpoint Slices (CES) Beta
k8s 에서 endpoint 와 endpoint slice 의 개념처럼 cilium 에서도 watch 할 endpoint 들을 별도로 구성하여 제공하는 기능입니다.

| 기존 endpoint | cilium endpoint | |
| watch 대상 | 파드 별 endpoint | CiliumEndpointSlice CRD 에 정의된 파드 |
| agent watch 대상 | 모든 에이전트가 모든 endpoint 를 watch | 상당히 적은 watch event |
| 룰 매칭 기준 | IP | label, identities |
기존 환경에서는 5,000 노드 × 100 엔드포인트 였다면 500,000 개를 Watch 해야 해서 kube-api 서버와 etcd 에 과도한 부하가 갔지만, CES 에서는 특정 조건에 부합하는 엔드포인트를 지정하여 리소스를 관리할 수 있습니다.
helm upgrade cilium cilium/cilium --version 1.18.1 --namespace kube-system --reuse-values \
--set ciliumEndpointSlice.enabled=true
kubectl rollout restart -n kube-system deployment cilium-operator
kubectl rollout restart -n kube-system ds/cilium
ciliumEndpointSlice.enabled=true 옵션으로 CES 를 사용할 수 있으며, kubectl get ciliumendpointslices.cilium.io -A 명령어로 watch 대상을 확인할 수 있습니다. 해당 옵션의 활성화 여부에 따라 차이가 많이 나는 것을 확인할 수 있습니다.
eBPF Host Routing , Netkit


cilium 은 ebpf 를 통해 네트워크 스택을 우회하고 host routing 을 지원하고 있습니다. ingress 의 경우 cpu 의 큐잉을 거치지 않지만, egress 의 경우 어쩔 수 없이 cpu 의 큐잉을 사용하고 있습니다.


netkit 디바이스를 사용하면 veth 가 쌍으로 존재해 egress 의 경우에도 ebpf 로 처리할 수 있어 컨테이너 네트워크의 오버헤드가 사라졌다라고 홍보하고 있습니다. (?)
helm upgrade cilium cilium/cilium --version 1.18.1 --namespace kube-system --reuse-values \
--set bpf.datapathMode=netkit
kubectl rollout restart -n kube-system deployment cilium-operator
kubectl rollout restart -n kube-system ds/cilium
위 명령어로 netkit 을 사용할 수 있지만 kernel 이 6.7 이상이어야 하고, CONFIG_NETKIT 옵션 활성화가 필요합니다.
cilium 성능 모니터링 메트릭
Cilium 상태 확인
# Cilium 상태 점검
cilium status
# BPF 맵 상태 확인
cilium bpf map list
# 메트릭 엔드포인트 확인
cilium metrics
주요 성능 메트릭
# BPF Map 연산 모니터링
cilium_bpf_map_ops_total
# 데이터패스 패킷 처리
cilium_datapath_packets_total
# 정책 계산 시간
cilium_policy_regeneration_time_stats_seconds
# 엔드포인트 상태 변화
cilium_endpoint_state_count
'인프라 > 쿠버네티스' 카테고리의 다른 글
| [Istio] mTLS strict mode 실습 (0) | 2026.03.28 |
|---|---|
| [cilium] Security (0) | 2025.09.07 |
| [cilium] Ingress / Gateway API (0) | 2025.08.23 |
| [cilium] cluster mesh (2) | 2025.08.15 |
| [cilium] BGP 설정 방법 (1) | 2025.08.15 |