
ITEM 11 "equals를 재정의하려거든 hashCode도 재정의하라"
본 글을 보기 전에 아래 순서대로 HashTable 에 대한 정의를 살펴보는 것을 추천한다.
HashTable 의 구현 방식들과 좋은 해쉬 함수를 작성하는 방법에 대해 잘 설명되어 있다. Effective Java 에서 다소 설명이 부족한 부분들은 아래 블로그에서 일부 차용해 작성하려고 한다.
https://bcho.tistory.com/1072
https://d2.naver.com/helloworld/831311
자바 최고 조상 Object 에는 equals 메서드 뿐만 아니라 hashCode 메서드도 기본적으로 정의되어 있다. HashMap 이나 HashSet 같은 Collection 에서 Object 의 hashCode 메서드를 활용하기 때문이다. 그래서 (Item 10) Object 를 재정의하였다면 hashCode 도 함께 재정의해야 한다. 아래는 Object 명세서에서 정의되어 있는 HashCode 가 지켜야 하는 규약들이다.
"equals 비교에 사용되는 정보가 변경되지 않았다면, hashCode 는 몇 번을 호출해도 일관되게 항상 같은 값을 반환해야 한다."
"equals 가 두 객체를 같다고 판단했다면, 두 객체의 hashCode 는 동일한 값을 반환해야 한다."
"equals 가 두 객체를 다르다고 판단했더라도, 두 객체의 hashCode 는 서로 다른 값을 반환할 필요는 없다. 다만, 다른 값을 반환해야 해시테이블의 성능이 좋아진다."
hashCode 재정의를 안 하거나 잘못 했을 때, 두 번째 조항을 위반한다. equals 에서 논리적으로 같다고 판단하더라도 Object 의 hashCode 기본 메서드는 이 둘을 전혀 다르게 판단할 수도 있다.
public class HashTest {
@Test
public void hashcode_재정의하지_않음() {
HashMap<PhoneNumber, String> map = new HashMap<>();
PhoneNumber test1 = new PhoneNumber(010, 1234, 5678);
PhoneNumber test2 = new PhoneNumber(010, 1234, 5678);
System.out.println("첫 번째 hashcode : " + test1.hashCode());
System.out.println("두 번째 hashcode : " + test2.hashCode());
map.put(test1, "골드에그");
assertNotEquals(map.get(test2), "골드에그");
}
@Test
public void hashcode_재정의() {
HashMap<AddedHashCodePhoneNumber, String> map = new HashMap<>();
AddedHashCodePhoneNumber test1 = new AddedHashCodePhoneNumber(010, 1234, 5678);
AddedHashCodePhoneNumber test2 = new AddedHashCodePhoneNumber(010, 1234, 5678);
System.out.println("첫 번째 hashcode : " + test1.hashCode());
System.out.println("두 번째 hashcode : " + test2.hashCode());
map.put(test1, "골드에그");
assertEquals(map.get(test2), "골드에그");
}
public static class PhoneNumber {
protected int firstNumber;
protected int secondNumber;
protected int thirdNumber;
public PhoneNumber(int firstNumber, int secondNumber, int thirdNumber) {
this.firstNumber = firstNumber;
this.secondNumber = secondNumber;
this.thirdNumber = thirdNumber;
}
@Override
public boolean equals(Object o) {
if (o == this)
return true;
if (!(o instanceof PhoneNumber)) {
return false;
}
PhoneNumber p = (PhoneNumber) o;
return this.firstNumber == p.firstNumber &&
this.secondNumber == p.secondNumber &&
this.thirdNumber == p.thirdNumber;
}
}
public static class AddedHashCodePhoneNumber extends PhoneNumber {
public AddedHashCodePhoneNumber(int firstNumber, int secondNumber, int thirdNumber) {
super(firstNumber, secondNumber, thirdNumber);
}
@Override
public int hashCode() {
int c = 31;
int hashcode = Integer.hashCode(firstNumber);
hashcode = c * hashcode + Integer.hashCode(secondNumber);
hashcode = c * hashcode + Integer.hashCode(thirdNumber);
return hashcode;
}
}
}
책에 있는 예제로 직접 테스트 해보면, 재정의 하지 않았을 때 hashCode 값이 같지 않아 get 메서드로 PhoneNumber 객체를 못 꺼내오는 것을 확인할 수 있다. 2번 규약과 같이 hashCode 가 같아야만 동치성 비교를 하기 때문이다.
그렇다고 아래와 같이 모두 같은 상수로 반환하면 HashTable 의 성능이 O(1) -> O(N) 으로 성능이 떨어지게 된다.
물론 3번 정의에 위반되지는 않지만, 아래와 같이 설계하면 42 라는 키에 모든 아이템들이 순차적으로 쌓일 것이다. 배열이나 링크드 리스트에서 아이템을 검색하는 것과 다를 바가 없게 된다.
@Override
public int hashCode() { return 42; }
어떻게 해야 여러 키들로 균등 분배하는 해시함수를 만들 수 있을지 고민해봐야 한다.
(위 네이버 링크를 참고해보면, 자바 진영에서도 더 성능이 좋은 해시함수를 만들기 위해 노력한 흔적들이 보인다.)
먼저 해시 테이블이 어떤 구성으로 되어 있는지 살펴보자.
해시 테이블은 입력에 대한 해시코드를 만들고 그 해시코드를 버킷의 갯수만큼 나누어 분배한다. 아무리 나눈다고 하지만 해시함수가 완전함수가 아니라면 결과가 중복이 되어 충돌이 날 수 밖에 없다. 이런 충돌을 피하고자 크게 Separate Chaining 방식과 Open Address 방식으로 해결한다.

Open Addressing 방식은 index 에 대한 충돌이 일어날 경우, 추가적으로 메모리를 할당하지 않고 비어있는 버킷을 사용한다. Separate Chaining 방식보다 메모리를 덜 사용하고 캐시된 데이터를 빠르게 꺼낼 수 있다는 장점이 있지만 데이터의 크기가 커지면 자연스레 캐시미스가 나서 성능이 점점 떨어진다. (자세한 사항은 1번 참조 블로그를 확인하자.)
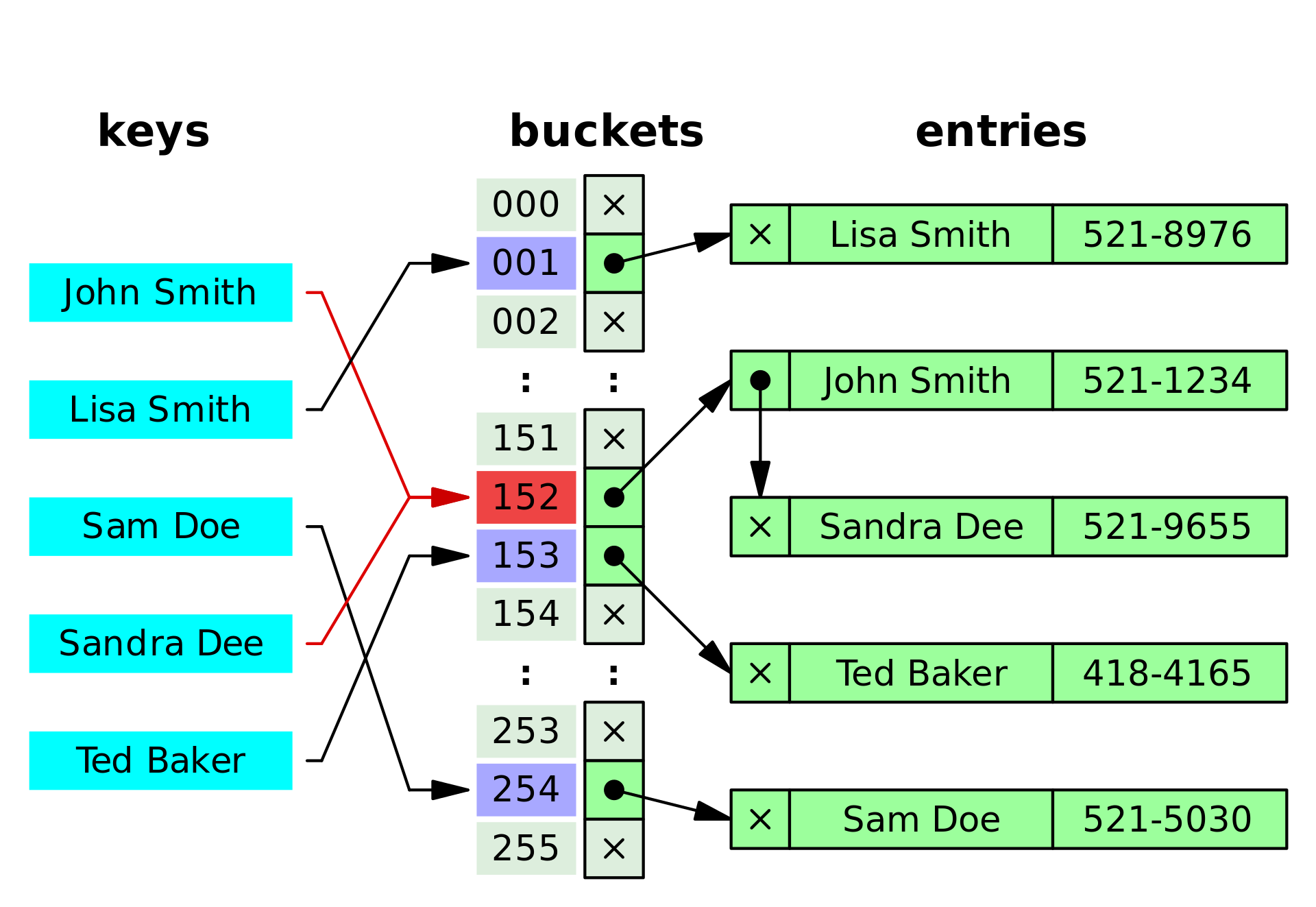
Separate chaining 방식은 동일한 인덱스로 인해 충돌나면 그 index 가 가리키고 있는 linked list 에 노드를 추가하여 값을 추가한다. (역시 자세한 사항은 1번 참조 블로그를 확인하자.)
두 방식 모두 버킷의 크기가 넉넉해야 되고, 잘 분배되어야 해시 성능이 좋아진다는 것을 직감적으로 알 수 있다.
책에서 3번째 규약을 잘 지키기 위해 좋은 해시 함수들을 다음과 같이 제안하고 있다.
좋은 해시 함수 만들기
(* 여기서 소개하는 핵심필드들은 equals 메서드에서 사용했던 필드들이다.)
1 . 결과 값 int 변수를 선언하고 첫 번째 핵심필드에 대한 hashCode 로 초기화한다.
2 . 기본타입 필드라면, Type.hashCode 를 실행한다. (Type 은 기본타입의 Boxing 클래스)
3 . 참조타입이라면 참조타입에 대한 hashCode 를 호출한다. 값이 null 이라면 0 을 더한다.
4 . 필드가 배열이라면 핵심 원소를 2번과 3번처럼 각각 계산한다. 배열의 모든 원소가 핵심필드라면 Arrays.hashCode 를 호출한다.
5 . 각각의 핵심 필드를 해시코드로 표현하여 소수와 곱해 재귀적으로 결과값을 더한다.
위 HashTest 코드에 오버라이딩된 hashCode 메서드가 이 방법을 통해 만든 것이다.
소수를 곱하는 이유는 책에서 관습적으로 해왔고 정확한 사유는 모르겠다고 하지만, 내 생각엔 소수가 자기 자신과 1 만이 약수를 가지고 있는 형태라 의미를 잃지 않는 값이라는 점을 활용한 것으로 보였다. 소수들 중에 31 이 2^5 - 1 로 계산이 쉬운 숫자라 활용된 것으로 보인다.
hashCode 를 재정의할 때 주의할 점은 다음과 같다.
1 . 성능을 높인다고 hashCode 를 계산할 때 핵심 필드를 생략해서는 안 된다.
2 . hashCode 생성 규칙을 API 사용자에게 공표하지 말자. 해시 성능을 더 높일 수 있는 좋은 방안이 있는데 공표를 하게 되면 그 hashCode 를 믿고 작성한 코드들 때문에 다음 릴리즈 때 성능을 개선할 수 없게 된다.
"equals 를 재정의하였다면 hashCode 도 재정의하자.
좋은 해시 함수 만들기 방법을 통해 적절히 분배하여 성능을 높이자"
'독후감 > Effective JAVA' 카테고리의 다른 글
| [Effective JAVA] 13 "clone 재정의는 주의해서 진행하라" (0) | 2022.05.05 |
|---|---|
| [Effective JAVA] 12 "toString 을 항상 재정의하라" (0) | 2022.05.03 |
| [Effective JAVA] 10 "equals는 일반 규약을 지켜 재정의하라" (0) | 2022.04.30 |
| [Effective JAVA] 9 "try-with-resource 를 사용하라" (0) | 2022.04.29 |
| [Effective JAVA] 8 "finalizer 와 cleaner 사용을 피하라" (0) | 2022.04.29 |