반응형
S3 정의
- 객체 스토리지
- 버킷은 디렉토리, 객체는 파일과 유사
- 객체 크기는 5TB 까지 저장
- 무한히 스케일링이 가능
- 버킷 이름은 모든 계정 모든 리전 통틀어 유일해야 한다
- 버킷은 리전에 위치
- 사용 사례
- 아카이브 저장
- 백업 및 장애 복구
- 어플리케이션, 미디어 호스팅
- 데이터 레이크
- 정적 웹 사이트 호스팅
S3 복제
| CRR (Cross-Region Replication) (교차 리전 복제) |
SRR (Same-Region Replication) (동일 리전 복제) |
|
| 복제 대상 | 모든 오브젝트 또는 prefix 나 tag 기반 하위 오브젝트 | |
| 복제 지역 | 다른 AWS 지역 | 같은 AWS 지역 |
| 목적 | 컴플라이언스 준수 대기 시간 최소화 다른 계정 복제 재해 복구 |
로그 통합 프로덕션 계정과 테스트 계정 간에 라이브 복제 구성 운영 효율성 증가 |
S3 Storage Class
| 스토리지 클래스 | 설계 이유 | 내구성 | 가용성 | 가용영역 | 최소 스토리지 기간 | 최소 요금 객체 크기 | 기타 고려 사항 |
| S3 Standard | 자주 액세스하는 데이터(한 달에 한 번 이상), 밀리초 단위의 액세스 | 99.999999999% | 99.99% | >= 3 | 없음 | 없음 | 없음 |
| S3 Standard-IA | 밀리초 단위의 액세스로 한 달에 한 번 이따금 액세스하는 수명이 긴 데이터 | 99.999999999% | 99.9% | >= 3 | 30일 | 128KB | GB당 검색 요금이 적용됩니다. |
| S3 Intelligent-Tiering | 알 수 없거나 변경되거나 예측할 수 없는 액세스 패턴이 있는 데이터 | 99.999999999% | 99.9% | >= 3 | 없음 | None | 객체당 모니터링 및 자동화 비용이 적용됩니다. 검색 요금이 없습니다. |
| S3 One Zone-IA | 재생성 가능하고 자주 액세스하지 않는 데이터(한 달에 한 번), 밀리초 단위의 액세스 | 99.999999999% | 99.5% | 1 | 30일 | 128KB | GB당 검색 요금이 적용됩니다. 가용 영역의 손실에 대한 복원력이 없습니다. |
| S3 Express One Zone | 단일 AWS 가용 영역 내에서 지연 시간에 민감한 애플리케이션을 위한 10밀리초 미만의 데이터 액세스 | 99.999999999% | 99.95% | 1 | None | None | S3 Express One Zone 객체는 선택한 단일 AWS 가용 영역에 저장됩니다. |
| S3 Glacier Instant Retrieval | 밀리초 단위의 액세스로 분기에 한 번 액세스하는 수명이 긴 아카이브 데이터 | 99.999999999% | 99.9% | >= 3 | 90일 | 128KB | GB당 검색 요금이 적용됩니다. |
| S3 Glacier Flexible Retrieval | 몇 분에서 몇 시간의 검색 시간으로 1년에 한 번 액세스하는 수명이 긴 아카이브 데이터 | 99.999999999% | 99.99%(객체 복원 후) | >= 3 | 90일 | NA* | GB당 검색 요금이 적용됩니다. 이 객체에 액세스하려면 먼저 보관된 객체를 복원해야 합니다. 자세한 정보는 아카이브된 객체 복원 섹션을 참조하세요. |
| S3 Glacier Deep Archive | 몇 시간의 검색 시간으로 1년에 한 번 미만 액세스하는 수명이 긴 아카이브 데이터 | 99.999999999% | 99.99%(객체 복원 후) | >= 3 | 180일 | NA** | GB당 검색 요금이 적용됩니다. 이 객체에 액세스하려면 먼저 보관된 객체를 복원해야 합니다. 자세한 정보는 아카이브된 객체 복원 섹션을 참조하세요. |
S3 Lifecycle Rules

- LifeCycle Rule 을 통해 S3 버킷 스토리지 클래스를 자동으로 전환할 수 있다.
- 스토리지 클래스를 전환할 뿐만 아니라 유효기간이 만료되어 삭제도 가능하다. (전환 작업, 만료 작업)
- 버킷 전체나 버킷 내부 특정 Prefix 단위, Tag 단위로 설정이 가능하다.
- 사용 시 주의사항
- Standard => Standard-IA => Intelligent-tier => OneZone-IA => Glacier => Deep-Archive 클래스로 순으로 전환이가능하지만 역순은 불가능하다. 사본 생성 후 사본을 옮겨야 한다.
- 사용 사례
- 이미지 원본은 60일 이내에 즉시 복구가 가능하고, 썸네일은 쉽게 만들 수 있는데 마찬가지로 60일 정도 보관하고 6시간 이내에 복구해야 한다.
- => 이미지 원본은 Standard 보관, 60일 이후 Glacier 로 전환, 썸네일 이미지는 OneZone-IA 보관 60일 이후 삭제
- 드물지만 삭제된 객체는 30일 이내에 즉시 복구가 가능해야 하고, 최대 1년까지는 삭제한 객체를 48시간 내 복구해야 한다.
- => S3 버저닝 활성화 후, 이전 버전은 Standard-IA 로 전환하고 30일 이후에는 Glacier Deep-Archive 로 전환
- 이미지 원본은 60일 이내에 즉시 복구가 가능하고, 썸네일은 쉽게 만들 수 있는데 마찬가지로 60일 정도 보관하고 6시간 이내에 복구해야 한다.
S3 Analytics
- 스토리지 접근 패턴을 분석해 언제 S3 스토리지 객체를 변환해야 하는지 S3 Analytics 서비스를 사용할 수 있다.
- 오직 Standard 로 부터 Standard-IA 로 보낼 때만 사용 가능하다.
- 데이터 분석이 가능하도록 보고서 (.csv) 가 24 ~ 48 시간 주기로 매일 업데이트된다.
S3 Event
- S3 EventBridge 로 전달하거나 직접 SNS, SQS, Lambda 로 보낼 수 있다.
- 직접 보내는 경우, 여러 개의 이벤트 소스로 전달할 수 있다.
- 직접 보내는 경우 S3 가 행동할 수 있도록 SNS, SQS, Lambda 의 Resource Policy 정책이 허용되어 있어야 한다.
S3 Performance
baseline
- S3 는 아주 많은 수의 요청량을 처리하기 위해 자동으로 스케일링한다. 지연율은 보통 100 ~ 200 ms 정도이다.
- 버킷의 prefix 당 최대 초당 쓰기 요청(PUT/COPY/POST/DELETE) 횟수은 3,500, 최대 초당 읽기 요청(GET/HEAD) 횟수은 5,500 이다.
- 버킷의 총 최대 요청 횟수와 버킷 당 prefix 의 개수는 제한이 없으므로 더 많은 요청을 받기 위해서는 요청량이 집중되는 오브젝트 단위를 분석해 prefix 로 분리해야 한다.
- 사용 사례
- bucket/1/file => /1/, bucket/2/file => /2/, bucket/3/file => /3/, bucket/4/file => /4/ 라면 최대 22,000 요청량 가능
Multi-Part Upload (분할 업로드)
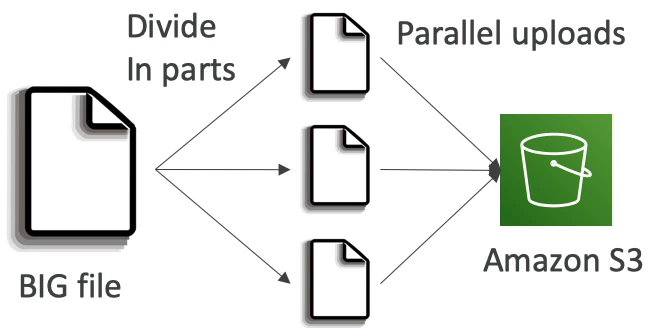
- 매우 큰 파일을 업로드 시 전송 속도를 향상하기 위해 파일을 분할하여 병렬 업로드한다.
- 100MB 이상 파일은 분할 업로드 권장, 5GB 이상 파일은 분할 업로드 필수
- 사용 사례
- 100GB 파일에 대해 멀티파트 업로드
- CreateMultipartUpload 호출
- 총 100GB 크기에 대해 각각 100MB 파트를 업로드하는 1000개의 개별 UploadPart 호출
- CompleteMultipartUpload 호출
- 100GB 파일에 대해 멀티파트 업로드
S3 Transfer Acceleration
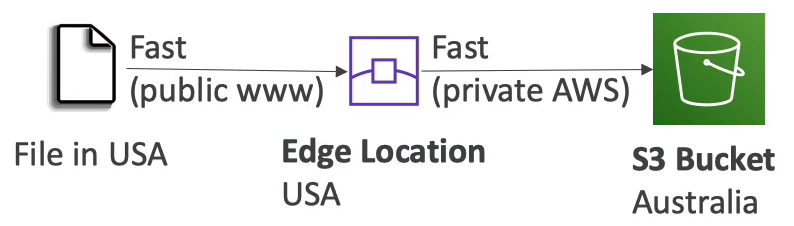
- 버킷 파일을 AWS 의 엣지 로케이션으로 전송함으로써 접송 속도를 높이는 방식이다.
- 공용 인터넷을 최소한으로 거치고 사설 AWS 네트워크 라인을 사용하기 때문에 속도가 훨씬 빠르다.
- Multi-Part Upload 기능과 호환
S3 Byte-Range Fetches
- 파일의 특정 바이트 일부 범위만 읽기 요청하는 방식이다.
- 병렬 요청 가능
- 사용 사례
- 다운로드 속도 가속화
- Multi-Part Upload 기능의 반대 전략으로 매우 큰 파일을 분할하여 병렬 다운로드한다. 예를 들어 100 GB 파일을 100 MB 씩 분할해서 10 번 반복 요청한다.
- 헤더 부분 읽어서 파일 확장자 확인
- 다운로드 속도 가속화
S3 Encryption
Amazon S3에서는 4가지 방법으로 S3 버킷의 객체를 암호화할 수 있다.
- Server-Side Encryption (SSE)
- Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3)
- Amazon S3 관리형 키를 사용하는 서버 측 암호화
- Server-Side Encryption with KMS Keys stored in AWS KMS (SSE-KMS)
- AWS KMS 키를 사용하는 서버 측 암호화
- Server-Side Encryption with Customer-Provided Keys (SSE-C)
- Client 가 제공하는 키를 사용하는 암호화
- AWS Console 에서는 확인이 불가능하고, SDK 프로그래밍 방식만 지원 가능
- Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3)
- Client-Side Encryption
- Client 에서 직접 암호화 후 전송하고 다운로드 후 복호화하는 방식
SSE-S3
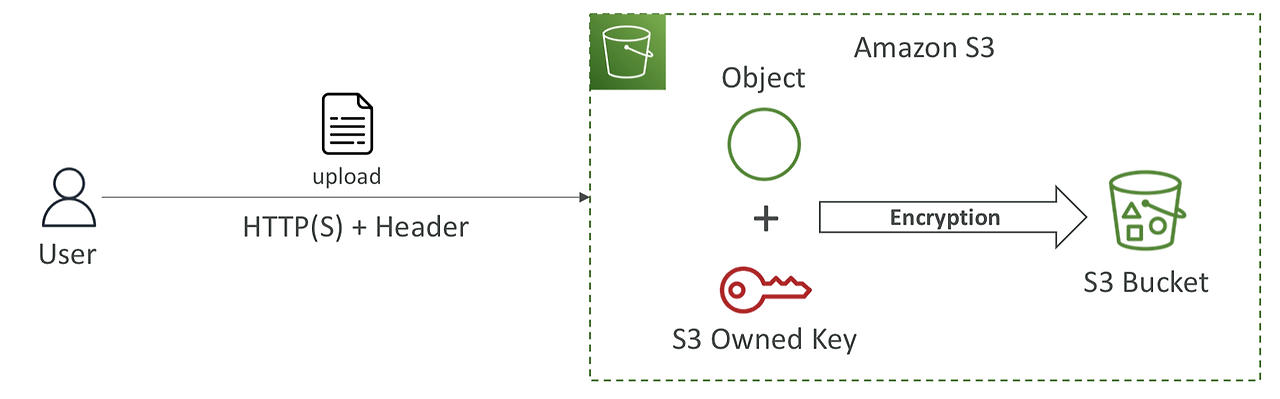
- 기본 S3 객체 암호화 방식
- AWS S3 에서 처리, 관리, 및 소유하는 키를 사용하여 암호화
- AES-256 알고리즘으로 암호화
- 클라이언트에서 "x-amz-server-side-encryption": "AES256" 로 header 조작 필요
SSE-KMS
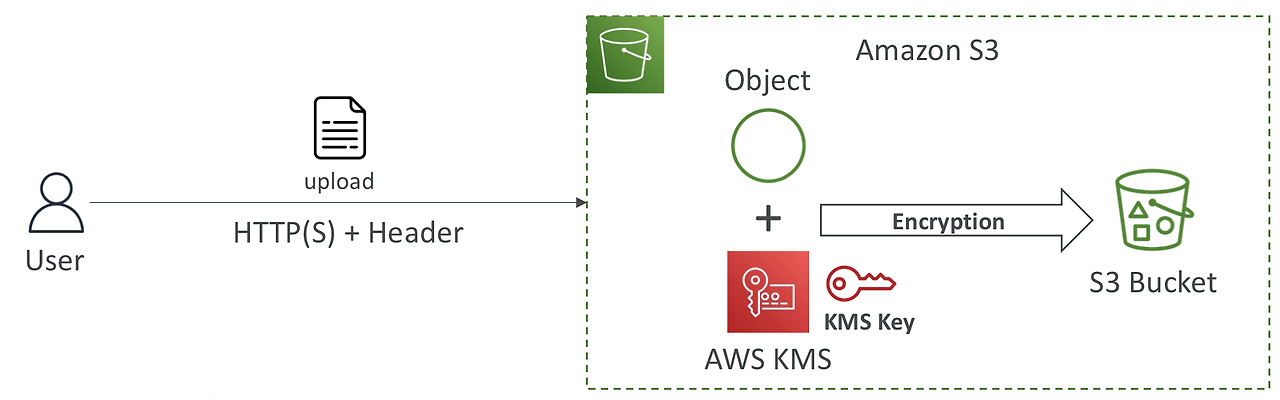
- AWS KMS(Key Management Service) 서비스를 통해 처리되고 관리되는 키를 사용하여 암호화
- 사용자가 KMS 서비스를 통해 키를 관리할 수 있음
- CloudTrail 로그를 통해서 키 사용 여부들을 감사 가능
- 클라이언트에서 "x-amz-server-side-encryption": "aws:kms" 로 header 조작 필요
- 사용 시 주의사항
- 업로드 시 GenerateDataKey KMS API 를 호출하고, 다운로드 시에는 Decrypt KMS API 를 호출하는데 이 API 가 초당 할당량 제한이 있음. 지역에 따라 다르지만 5,500, 10,000, 30,000 req/s.
- 쓰로틀링 방지를 위해, 서비스 할당량 콘솔을 통해 초당 할당량을 높인다.
SSE-C
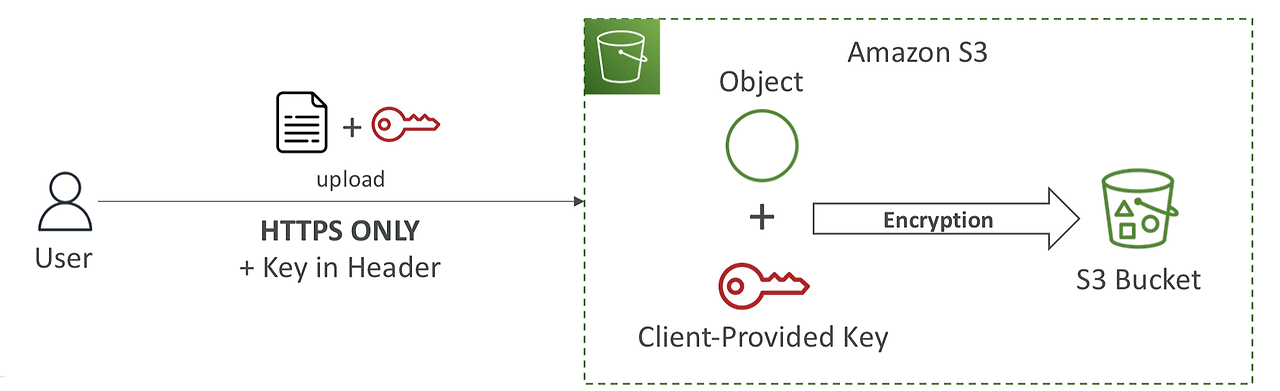
- Client 가 키를 생성해서 AWS 에 전송하고 서버 측에서 암호화 (Client 가 직접 키 관리)
- HTTPS 에서만 가능
- AWS 에서 키를 관리하지 않으므로 HTTPS 요청마다 암호화 키를 HTTP 헤더에 제공해야 함
Client-Side Encryption
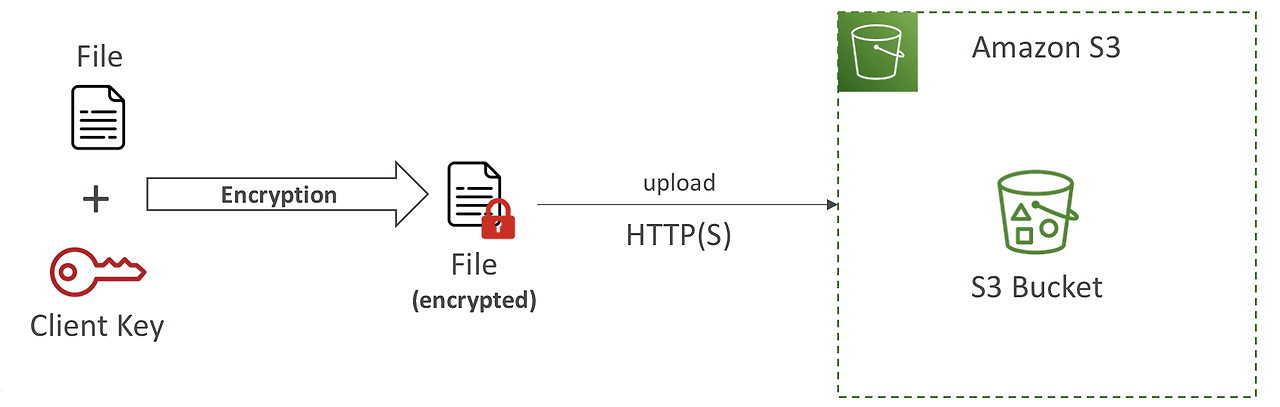
- AWS 에서 키 생성, 관리 및 암복호화 하지 않고 클라이언트 측에서 모두 수행하는 방식
- Amazon S3 Client-Side Encryption Library 와 같은 클라이언트 라이브러리 사용
- 클라이언트가 데이터를 S3 에 업로드하기 전에 암호화하고, 다운로드 후 복호화한다.
S3 전송 암호화 (SSL/TLS)
- S3 는 두 가지 방식의 엔드포인트를 제공
- HTTP 엔드포인트 (암호화하지 않음)
- HTTPS 엔드포인트 (전송 중 암호화)
- SSL 또는 TLS 방식으로 암호화
- HTTPS 를 권장
- 대부분의 클라이언트는 기본적으로 HTTPS 엔드포인트를 사용
S3 암호화 강제
- S3 버킷 정책을 사용하여 전송 중 암호화를 강제하거나, 오브젝트 업로드 시 특정 암호화 방식으로 강제할 수 있음
- 전송 중 암호화 강제
- Effect => Deny
- Condition => (Bool) aws:SecureTransport: false
- S3 객체 업로드 시 암호화 헤더 없는 경우 거부
- Effect => Deny
- Condition => (StringNotEquals) s3:x-amz-server-side-encryption: aws:kms
- Condition => (Null) s3:x-amz-server-side-encryption-customer-algorithm: true
- 사용 사례

- 왼쪽 정책은 SSE-KMS 방식 아니면 거부. 오른쪽 정책은 SSE-C 방식 아니면 거부.
- 아니면 기본 암호화 방식을 채택할 수 있다.
- 해당 버킷 정책은 항상 기본 암호화 전에 평가된다.
S3 Access Points
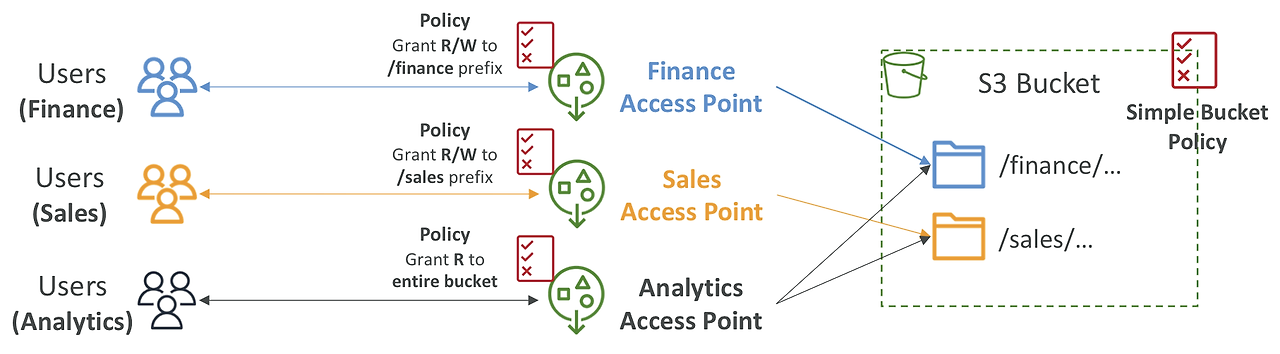
- S3 에 접근하는 사용자나 그룹이 많아지고 S3 에 저장하는 데이터의 유형이 많아짐에 따라 Bucket Policy 에 모든 접근 권한을 설정하기가 복잡해졌다.
- S3 버킷 Prefix 별로 사용자나 그룹의 접근 권한 설정을 한다.
- 접근할 수 있는 포인트인 DNS Name 과 Access Point Policy 를 가지고 있다.
- 사용 시 주의사항
- VPC 내부에서만 접근하도록 설정하려면
- VPC Endpoint(Interface 나 Gateway) 무조건 생성 필요
- VPC Endpoint Policy 에서 S3 Access Point 와 S3 Bucket 둘 다 allow 정책 허용 필요
- VPC 내부에서만 접근하도록 설정하려면
S3 Object Lambda
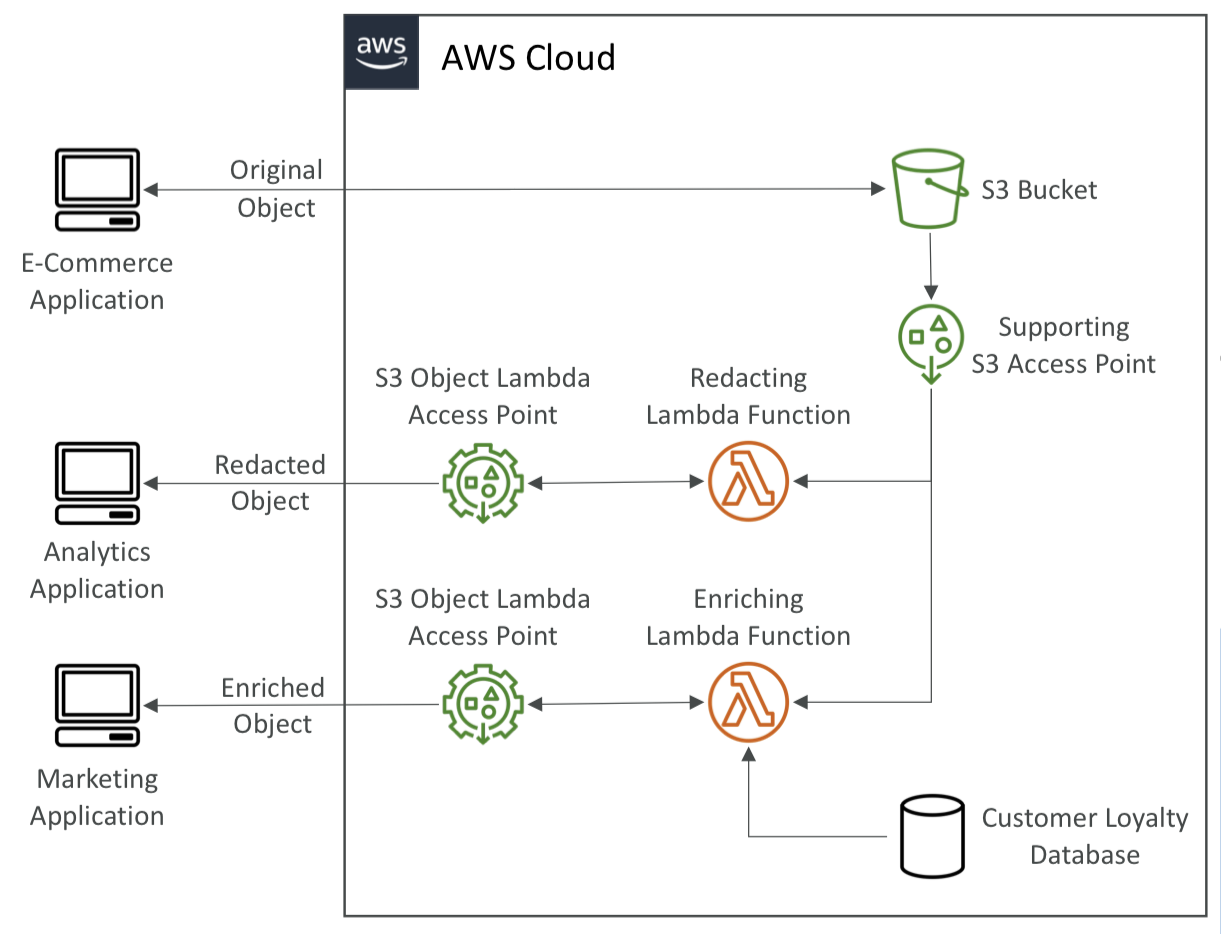
- S3 Object Lamda 기능이 출시되기 이전에는 각 어플리케이션의 요구사항을 충족시키기 위해 데이터를 추가 가공 후, 여러 개의 S3 버킷을 준비해서 오브젝트를 반환하거나 S3 Bucket 앞 단에 Proxy 인프라를 설계하여 가공했다.
- AWS Lambda 함수를 사용하여 S3 오브젝트를 반환하기 이전에 결과 값을 수정한다.
- 사용 사례
- 개인 식별 정보(PII) 삭제
- 데이터 형식 변환(예 : XML to JSON)
- 이미지 동적 크기 조정 및 워터마킹
- 마케팅 차원에서 요청 사용자의 개인 데이터 추가 작업
- 사용 시 주의 사항
- S3 Access Point 와 S3 Object Point 두 개 다 모두 필요
- 외부에서 접근 가능하도록 하려면 S3 Access Point 의 Policy 조작 필요
- 참고
- https://aws.amazon.com/ko/blogs/korea/introducing-amazon-s3-object-lambda-use-your-code-to-process-data-as-it-is-being-retrieved-from-s3/
- https://medium.com/musinsa-tech/s3-object-lambda%EB%A5%BC-%EC%9D%B4%EC%9A%A9%ED%95%9C-on-demand-%EC%9D%B4%EB%AF%B8%EC%A7%80-%EB%B3%80%ED%99%98-%EC%84%9C%EB%B9%84%EC%8A%A4-%EC%86%8C%EA%B0%9C-5e3650cc27a9
S3 CORS
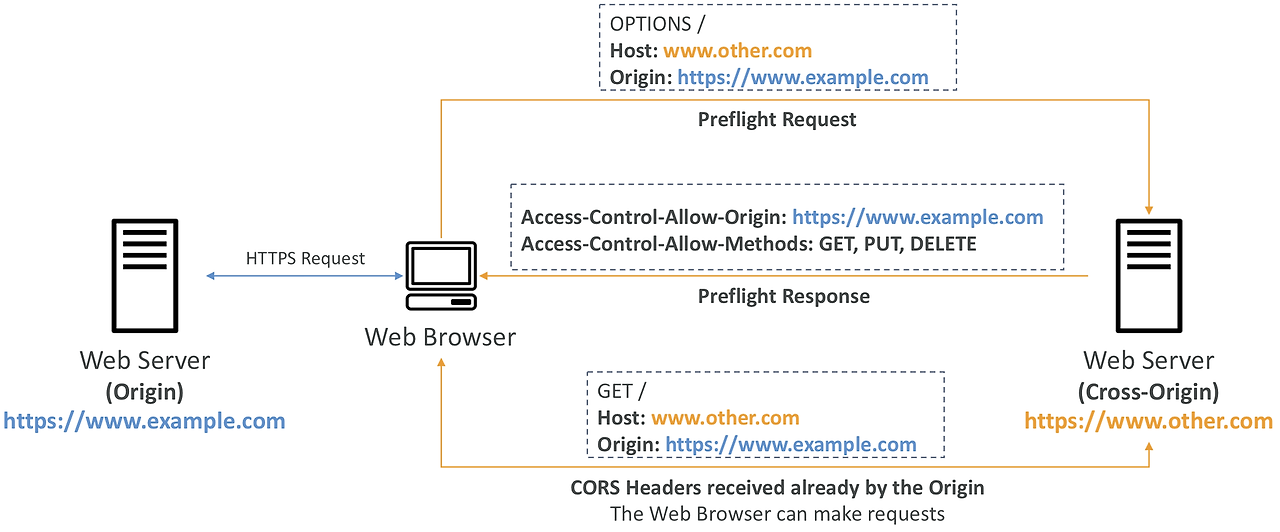
- 웹 브라우저에서 다른 Origin 에 대한 요청으로 인한 공격을 방지하고자 SOP(Same Origin Policy) 정책을 도입함
- Origin은 scheme (protocol) + host (domain) + port 로 Same Origin 은 프로토콜, 도메인, 포트 번호가 같아야 함
- 하지만 웹 사이트들이 다른 도메인 영역에 웹 자원을 로드하고 서비스하고 있는 경우가 많아 특정 Origin 만 접근이 가능하도록 설정이 필요했다. CORS(Cross-Origin Resourse Sharing) 이라는 기능이다.
- 현재 웹 사이트를 방문하면서 다른 Origin 의 자원을 사용해야 하는 경우, 다른 Origin 서버에서 허용 응답을 보내주어야 한다.
- 정확히는 응답 헤더로 Access-Control-Allow-Origin, Access-Control-Allow-Methods 등 CORS 헤더를 보내주어야 한다.
- 마찬가지로 S3 에서도 CORS 헤더를 설정함으로써 특정 출처와 메서드들을 허용할 수 있다.

S3 Delete 방지
MFA 사용
- 사용자가 중요한 S3 작업을 수행하기 전에 MFA (Multi-Factor Authentication) 다중 인증을 추가로 요구할 수 있다.
- 버전 관리 활성화 필수
- MFA Delete 기능을 활성화 / 비활성화 할 수 있는 권한은 버킷 소유자만 가능
- MFA가 필요한 작업은 다음과 같다.
- 객체 버전을 영구적으로 삭제
- 버킷에서 버전 관리를 중단할 때
S3 Object Lock
- WORM (Write Once Read Many) 모델로 지정된 기간 동안 특정 객체 버전을 삭제하는 것을 방지한다.
- 버저닝 기능이 무조건 활성화 되어 있어야 함
- 버킷 내의 모든 객체에 각각 적용 가능
- 보관 모드
- ( * 법적 보관은 보관모드는 아니나, 비교를 위해 같이 정리하였다 )
| Compliance (규정준수) | Governance (거버넌스) | Legal Hold (법적 보관) | |
| 삭제 가능 | 불가능 (루트 사용자 포함) | 삭제 권한이 있는 일부 사용자만 가능 | s3:PutObjectLegalHold IAM 권한 필요 |
| 보존 기간 | 보존 기간 설정 후 조작 불가능 | 보존 기간 설정 후 변경 가능 | 무기한 |
| 모드 변경 | 불가능 | 가능 | 가능 |
S3 Access Logs
- 감사 목적으로 S3 버킷의 모든 액세스를 로깅할 수 있다.
- 승인 또는 거부 여부와 상관없이 모든 계정에서 S3에 대한 요청이 로그로 남는다.
- 로깅 대상 버킷은 동일한 AWS 리전에 있어야 한다.
- Amazon S3 서버 액세스 로그 형식: https://docs.aws.amazon.com/ko_kr/AmazonS3/latest/userguide/LogFormat.html
- 사용 시 주의사항
- 로깅 버킷을 모니터링하는 버킷과 동일하게 설정하면 무한 루프 발생
Pre-Signed URLs
- 접근 권한 인증을 마쳤는데도 불구하고 다른 AWS 서비스 제한 때문에 S3 에 도달하지 못 할 수 있다.
- 접근 권한에 대한 인증을 마치면 직접 S3 에 접근할 수 있는 URL 을 발급해준다.
- URL 만료 기한
- S3 Console 은 1분부터 720분(12시간)까지 설정 가능
- AWS CLI 는 --expires-in 매개변수로 만료 시간을 지정할 수 있으며, 초 단위로 설정 가능 (기본값은 3600초, 최대 604800초(168시간))
- 미리 서명된 URL을 받은 사용자는 GET / PUT에 대한 권한을 URL을 생성한 사용자로부터 상속받음.
- 사용 사례
- 로그인한 사용자만 S3 버킷에서 프리미엄 비디오를 다운로드할 수 있도록 허용
- URL을 동적으로 생성하여 계속 변경되는 사용자 목록이 파일을 다운로드할 수 있도록 허용
- 일시적으로 사용자가 S3 버킷의 특정 위치에 파일을 업로드할 수 있도록 허용
반응형
'인프라 > AWS' 카테고리의 다른 글
| AWS DEA-C01 (0) | 2025.01.27 |
|---|---|
| AWS EBS & EFS (0) | 2024.09.03 |
| AWS Step Functions (0) | 2024.08.20 |
| AWS Service Catalog (0) | 2024.08.19 |
| Amazon EKS 역할 / 네트워크 / 볼륨 / 모니터링 (0) | 2024.07.20 |